
【动手学深度学习】深度卷积神经网络_AlexNet
深度卷积神经网络_AlexNet
本文为李沐老师《动手学深度学习》一书的学习笔记,原书地址为:Dive into Deep Learning。
1.网络结构
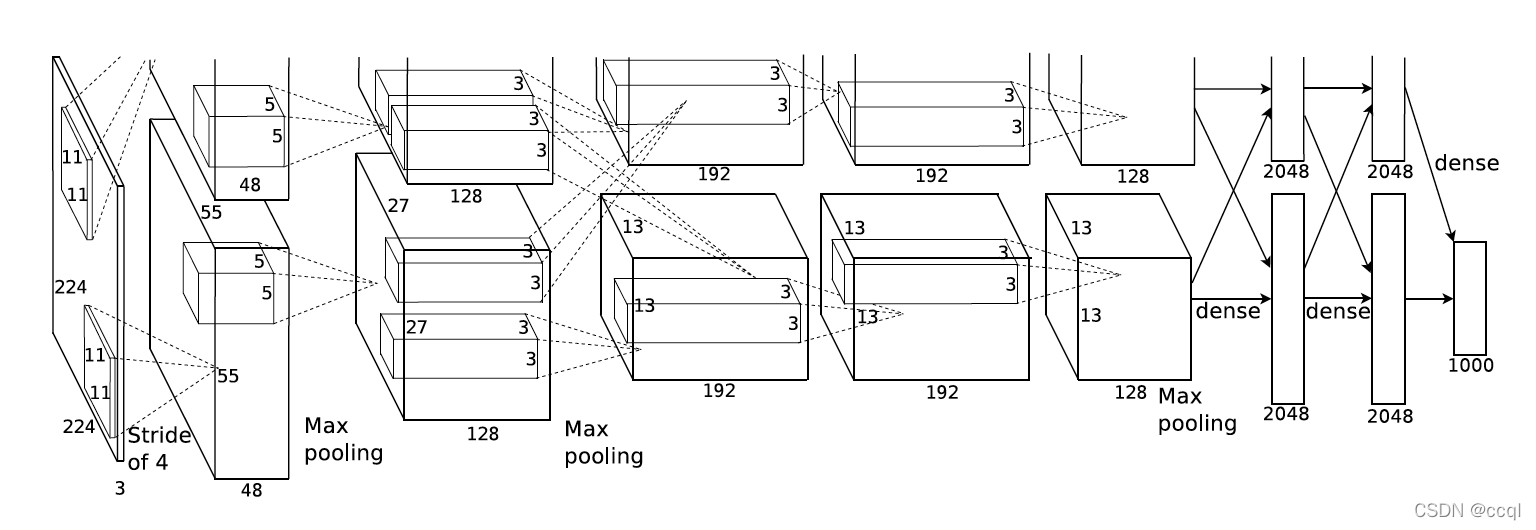
网络结构计算过程:
假设输入形状是 n h × n w n_h\times n_w nh×nw,卷积核窗口形状是 k h × h w k_h\times h_w kh×hw,在高的两侧一共填充 p h p_h ph行(Conv2d()函数中的padding代表是在一边填充的行数,所以若用该函数, p h p_h ph和 p w p_w pw要 × 2 \times2 ×2),在宽的两侧一共填充 p w p_w pw列,高上步幅为 s h s_h sh,宽上步幅为 s w s_w sw,则卷积输出形状计算公式: ⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor\times\lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋
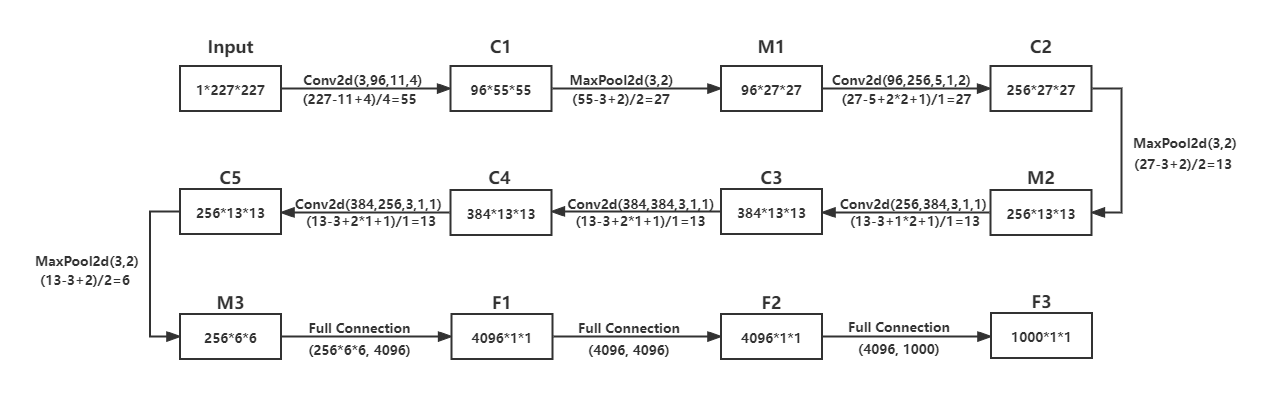
2.网络结构说明
AlexNet与LeNet的设计理念非常相似,但也有显著的区别。
第一,更大的卷积窗口和更多的卷积通道:AlexNet第一层中的卷积窗口形状是 11 × 11 11\times11 11×11。因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上,ImageNet图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。第二层中的卷积窗口形状减小到 5 × 5 5\times5 5×5,之后全采用 3 × 3 3\times3 3×3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为 3 × 3 3\times3 3×3、步幅为2的最大池化层。而且,AlexNet使用的卷积通道数也大于LeNet中的卷积通道数数十倍。
第二,ReLU激活函数:AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,例如它并没有sigmoid激活函数中的求幂运算。另一方面,ReLU激活函数在不同的参数初始化方法下使模型更容易训练。这是由于当sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数;而ReLU激活函数在正区间的梯度恒为1。因此,若模型参数初始化不当,sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。
第三,丢弃法:AlexNet通过丢弃法来控制全连接层的模型复杂度。而LeNet并没有使用丢弃法。
第四,图像增广:AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
3.代码实现
import time
import torch
from torch import nn, optim
import torchvision
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output

 浙公网安备 33010602011771号
浙公网安备 33010602011771号