【Flume】高级组件之Channel Selectors及项目实践
文章目录
1. 组件简介
通俗来讲,Channel Selectors组件控制Source采集到的数据分别流向哪些Channels。组件包括Replicating Channel Selector、Load Balancing Channel Selector和Multiplexing Channel Selector,其中Replicating Channel Selector是默认的Channel选择器,它会将Source采集过来的Event发往所有Channel;Load Balancing Channel Selector是一种负载均衡机制,将数据按照随机或者轮换的策略分发到不同的Channel,以缓解数据传输量大时的Channel阻塞;Multiplexing Channel Selector可以根据Event中header里面的值将其发往不同的Channel;。
- Replicating Channel Selector:该组件有两个配置项,分别是
selector.type和selector.optional。selector.type必须配置为replicating,表示使用Replicating Channel Selectors;selector.optional是一个可选配置,若配置a1.sources.r1.selector.optional = c1,则表示c1是可选Channel,对c1的写入失败将被忽略。 - Load Balancing Channel Selector:该组件有两个配置项,分别是
selector.type和selector.policy。selector.type必须配置为load_balancing,表示使用Load Balancing Channel Selector;selector.policy为数据分发方式选择,有两个机制可供选择:轮换(round_robin)和随机(random)。 - Multiplexing Channel Selector:该组件有四个配置项,分别是
selector.type、selector.header、selector.default和selector.mapping.*。selector.type必须配置为multiplexing,表示使用multiplexing Channel Selector;selector.header配置标注了Event依据header中的哪一个键值对分发;selector.default和selector.mapping.*用于定义分发规则,详见后续实践。
2. 项目实践
2.1 Replicating Channel Selector实践
2.1.1 需求
将Source采集到的数据重复发送给两个Channle,最后每个Channel后面接一个Sink,负责把数据存储到不同存储介质中,方便后期使用。在实际工作中这种需求还是比较常见的,就是希望把一份数据采集过来以后,分别存储到不同的存储介质中,不同存储介质的特点和应用场景是不一样的,典型的就是HDFS Sink和Kafka Sink,通过HDFS Sink实现离线数据落盘存储,方便后面进行离线数据计算;通过Kafka Sink实现实时数据存储,方便后面进行实时计算,由于我还没学Kafka,所以在这里先使用Logger Sink代理。
2.1.2 配置
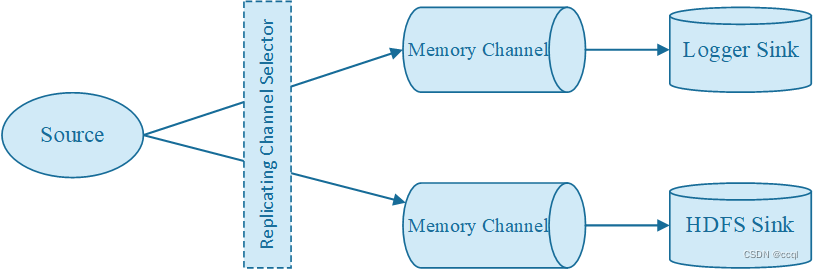
默认其实就采用Replicating Channel Selector将相同的数据发往链接的多个Channels,因此也可以不配置这个选择器。这个实例项目主要实践了多Channel的配置,两个Channel分别发往两个Sink,一个以Log方式打印在控制台,一个发往HDFS。
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channle选择器[默认就是replicating,所以可以省略]
a1.sources.r1.selector.type = replicating
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://192.168.182.100:9000/replicating
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
2.1.3 运行
运行如下命令运行Agent a1:
bin/flume-ng agent --name a1 --conf conf --conf-file conf/replicatingChannelSelectors.conf -Dflume.root.logger=INFO,console
使用telnet命令连接44444端口,并发送数据:hello
[root@bigData01 apache-flume-1.9.0-bin]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
hello
OK
Sink k1在控制台输出数据hello:
2023-02-10 23:09:10,315 ...... Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Sink k2在HDFS写入数据hello:
[root@bigData01 apache-flume-1.9.0-bin]# hdfs dfs -ls /replicating
Found 1 items
-rw-r--r-- 2 root supergroup 7 2023-02-10 23:09 /replicating/data.1676041750272.log.tmp
[root@bigData01 apache-flume-1.9.0-bin]# hdfs dfs -cat /replicating/data.1676041750272.log.tmp
hello
2.2 Multiplexing Channel Selector实践
2.2.1 需求
根据数据内容不同,把数据分别发往不同的存储介质,把所处城市为bj的居民数据以日志方式发往控制台,其余城市的居民数据存储在HDFS。居民数据如下:
{"name":"jack","age":19,"city":"bj"}
{"name":"tom","age":26,"city":"sh"}
2.2.2 配置
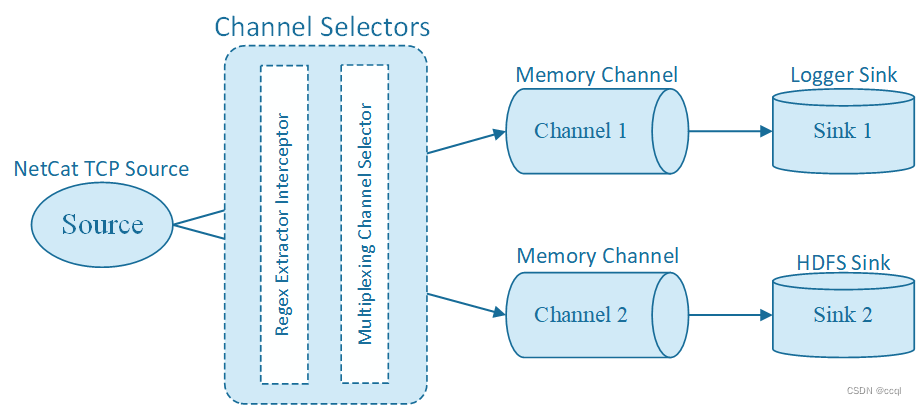
先用Regex Extractor Interceptor把城市数据写入Event的header部分,并使用Multiplexing Channel Selector读取header内容并分别发往不同的Channel,最终发往不同的Sink。
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置source拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "city":"(\\w+)"
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = city
# 配置channle选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = city
a1.sources.r1.selector.mapping.bj = c1
a1.sources.r1.selector.default = c2
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://192.168.150.100:9000/multiplexing
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
2.2.3 运行
如下命令运行Agent a1:
bin/flume-ng agent --name a1 --conf conf --conf-file conf/multiplexingChannelSelectors.conf -Dflume.root.logger=INFO,console
使用telnet命令连接44444端口,并发送数据:
[root@bigData01 apache-flume-1.9.0-bin]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
{"name":"jack","age":19,"city":"bj"}
OK
{"name":"tom","age":26,"city":"sh"}
OK
Sink k1在控制台打印居住在bj的居民信息:
2023-02-10 23:19:58,494 ...... {"name":"jack"," }
Sink k2向HDFS中发送居住在其他城市的居民信息:
[root@bigData01 apache-flume-1.9.0-bin]# hdfs dfs -cat /multiplexing/data.1676042412667.log.tmp
{"name":"tom","age":26,"city":"sh"}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号