【Flume】Flume实践之采集网站日志上传至HDFS
文章目录
1. 需求
将机器A(bigData02)和机器B(bigData03)两台机器实时产生的日志数据汇总到机器C(bigData04)中,再通过机器C(bigData04)将数据统一上传至HDFS的指定目录中。其中,HDFS中的目录是按天生成的,每天一个目录。
2. 分析
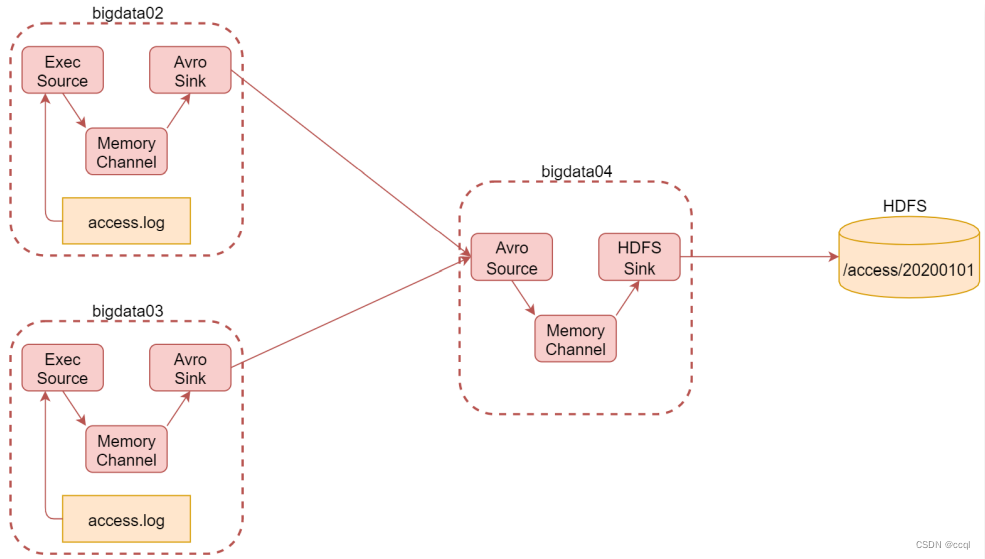 对于机器A和机器B:由于网站日志是存放在具体文件中的,因此使用Exec Source采集数据;由于网站的日志数据对存储安全性要求没那么高且为了保证快速存储,因此采用Memory Channel作为通道传输数据;Avro是一种数据序列化系统,经过它序列化的数据传输起来效率更高,因此使用Avro Sink,与之对应的还有Avro Source。
对于机器A和机器B:由于网站日志是存放在具体文件中的,因此使用Exec Source采集数据;由于网站的日志数据对存储安全性要求没那么高且为了保证快速存储,因此采用Memory Channel作为通道传输数据;Avro是一种数据序列化系统,经过它序列化的数据传输起来效率更高,因此使用Avro Sink,与之对应的还有Avro Source。
对于机器C:为了接收Avro Sink传输的序列化数据,使用Avro Source接收数据;由于要将数据写入HDFS中,因此使用HDFS Sink。
3. 配置
一共涉及到三个机器,其中机器A和B收集网站信息,并发送给机器C汇总传输到HDFS,因此需要配置三台机器,机器A和B的配置基本相同。
3.1 配置机器A-bigData02
Exec Source的命令配置中,tail -F是根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪;而tail -f根据文件描述符进行追踪,当文件改名或被删除,追踪停止。
a1.channels.c1.capacity指Channel中最多存储1000个event,a1.channels.c1.transactionCapacity指一次事务中写入和读取的event最大数为100。
a1.sinks.s1.hostname需要换成自己要发往的虚拟机IP地址,这里指bigData04的地址。
a1.sources = r1
a1.channels = c1
a1.sinks = s1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.s1.type = avro
a1.sinks.s1.hostname =
a1.sinks.s1.port = 45454
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
3.2 配置机器B-bigData03
与机器A的配置相同。
a1.sources = r1
a1.channels = c1
a1.sinks = s1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.s1.type = avro
a1.sinks.s1.hostname =
a1.sinks.s1.port = 45454
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
3.3 配置机器C-bigData04
Avro Source的bind参数是要监听的ip地址,这里设置为当前机器的通用ip:0.0.0.0。因为一台机器可以有多个ip,例如:内网ip、外网ip,如果通过bind参数指定某一个ip的话,表示就只监听通过这个ip发送过来的数据了,这样会有局限性,所以使用通用ip。注意port与机器A和B的Avro Sink的端口配置保持一致。
a1.sinks.s1.hdfs.filePrefix参数指定文件前缀,a1.sinks.s1.hdfs.path参数指定地址,若要使用时间信息(%Y%m%d…)有两种方法:要么在header中添加timestamp键值对,要么设置hdfs.useLocalTimeStamp为true。hdfs.rollInterval参数指定Sink间隔多久将临时文件滚动成最终目标文件,这里设置的3600s,也就是1h。hdfs.rollSize参数指定当临时文件达到多大时(单位:bytes),滚动成目标文件,这里设置的134217728B=131072K=128M。
a1.sources = r1
a1.channels = c1
a1.sinks = s1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 45454
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://(hdfs的ip地址):9000/flume/events/data/log/%Y%m%d/
a1.sinks.s1.hdfs.filePrefix = logs
a1.sinks.s1.hdfs.fileType = DataStream
a1.sinks.s1.hdfs.writeFormat = Text
# 60 * 60s = 1h
a1.sinks.s1.hdfs.rollInterval = 3600
# 128*1024*1024 = 128M
a1.sinks.s1.hdfs.rollSize = 134217728
a1.sinks.s1.hdfs.rollCount = 0
a1.sinks.s1.hdfs.useLocalTimeStamp = true
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
4. 执行
4.1 模拟网站日志输出
为了模拟网站输出日志信息到/data/log/access.log,写了一个简单的Shell脚本(每隔一秒向文件中输入时间信息),后台运行命令为nohup sh test.sh &。
#!/bin/bash
# test.sh
while [ "1" = "1" ]
do
currentTime=`date +%s`
name=`hostname`
echo ${name}_${currentTime} >> /data/log/access.log
sleep 1
done
4.2 执行结果
执行后,可以看到HDFS中创建了相应的文件。由于文件每秒更新一条,且之前设置了transactionCapacity = 100,因此文件每隔100s一次性新增100条数据。
[root@bigData01 hadoop-3.2.0]# hdfs dfs -cat /flume/events/data/log/20230205/logs.1675606239297.tmp | wc -l
1734
[root@bigData01 hadoop-3.2.0]# hdfs dfs -cat /flume/events/data/log/20230205/logs.1675606239297.tmp | wc -l
1834

 浙公网安备 33010602011771号
浙公网安备 33010602011771号