哈希
一、词典的引入

循value(数值)访问,其代表为hashing(散列)
当使用数组来存储电话号码时,可以按秩访问,对应的时间效率为O(1),但是问题在于要存储的电话号码的数量是极大的,可达到100M(北京市),但是我们经常用到的只是其中一个非常小的子集(清华大学),所以其空间效率极低。 N << R,此时效率只有万分之几。

散列表对数组的空间进行了压缩; N < M << R
M尽可能与N同阶。
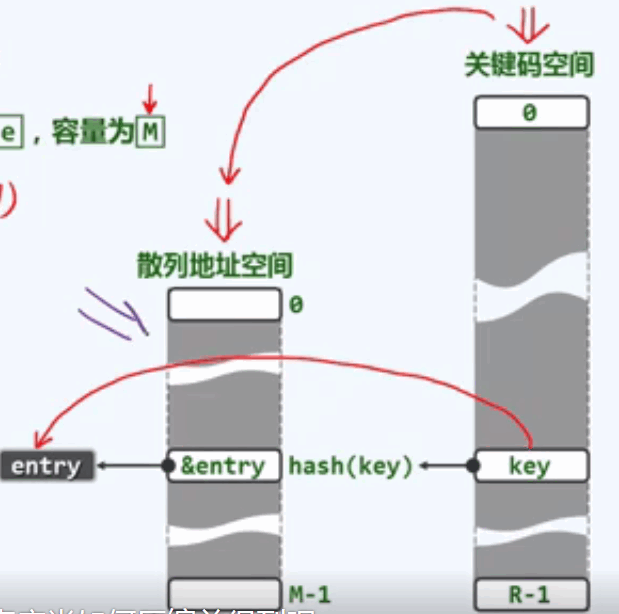
散列函数:hash(): key -> &entry(这里并不是直接对应词条本身,转换为散列表中的某个桶单元,)
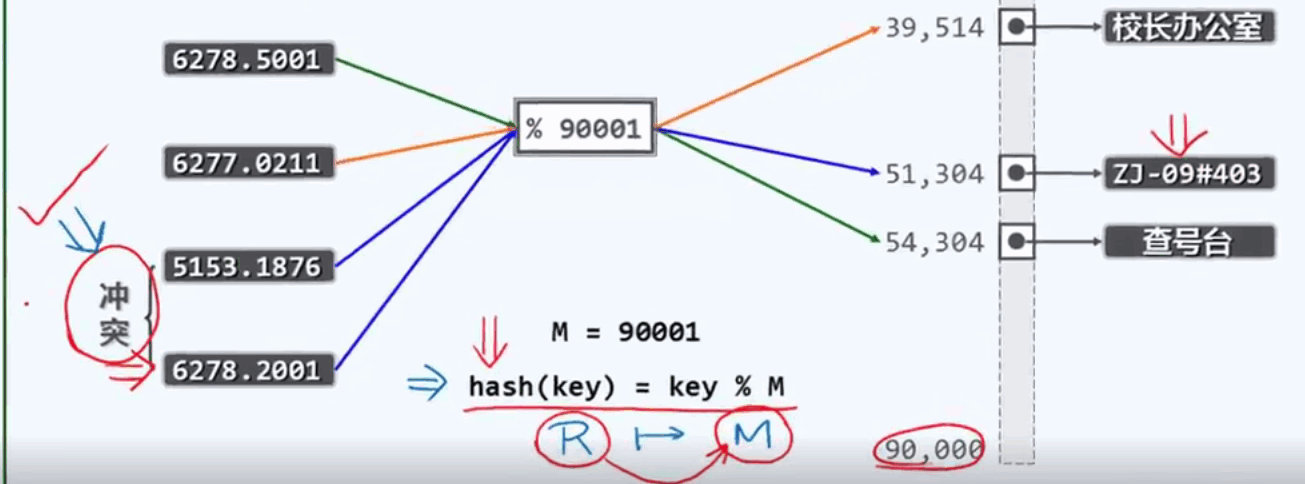
散列表的选择,就是尽量远远小于北京市电话号码的数量,又要和我们实际存放的电话号码数量25K保持同阶,这样,效率提高到了25%.

通过一个hash函数,将输入的电话号码,映射到散列表汇总,找到电话对应的人。N/M的比值,称为装填因子,load factor
散列冲突:
有可能出现多个电话号码对应一个散列位置的冲突,称之为散列冲突,就是有R个鸽子,但是只有M个笼子,根据鸽巢原理,冲突不可避免。
C部分:如何设计散列函数?
散列表无非就是映射, 将词条空间中的元素映射到散列表地址空间。通常情况,前者远远大于后者。所以我们需要精心设计散列表,或者散列函数,尽可能降低冲突的概率。并且制定可行的预案,在冲突发生时,能够尽可能排解。
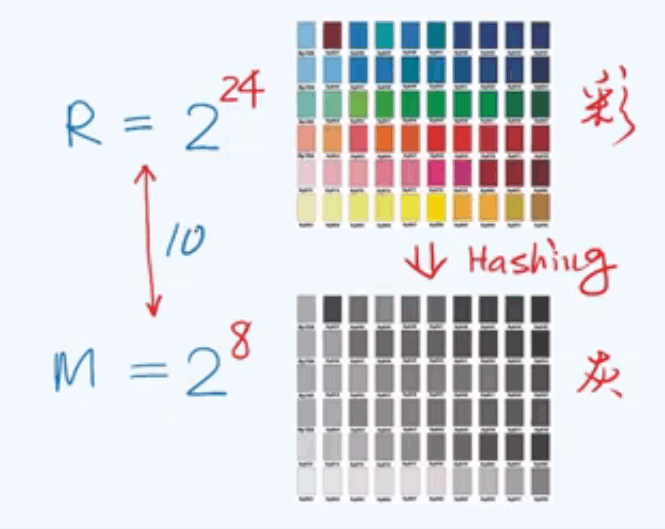
近似的单射:
例子: 将彩色图像映射为灰度图像,
设计散列函数的准则:
1.确定性: 同一关键码总是被映射到同一地址
2.快速性: O(1)的时间效率
3.满射性: 尽可能充分覆盖整个散列空间
4.均匀性: 关键码映射到散列表各位置的概率尽量可能接近,可有效避免聚集clustering现象。
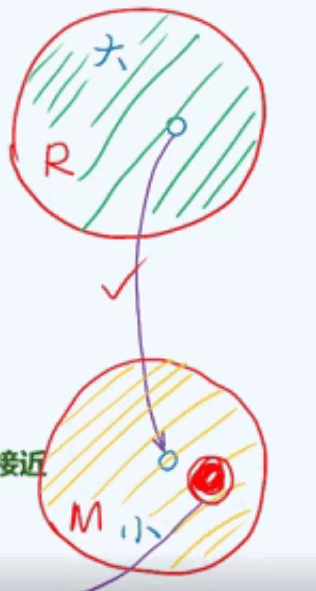
散列函数1:除余法
取余法取M为素数,数据对散列表的覆盖最充分,分布也最为均匀。
MAD(除余法缺陷):
1. 不动点:无论M表长取值如何,总有hash(0) = 0 ;
2. 零阶均匀:[0,R)的关键码,平均分配到M个桶,但是相邻的关键码的散列地址也比相邻。
我们希望实现更高阶的均匀性:
1.临近的关键码,散列地址不再临近!
改进如下: M+A+D(先乘后加再取余)
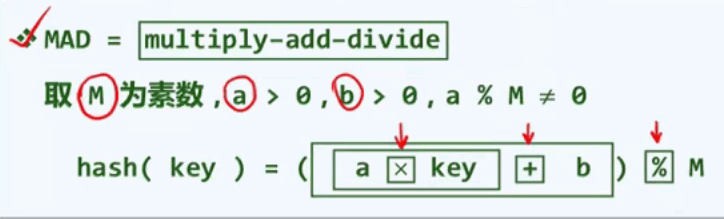
小空间往大空间的映射:密码学
散列函数2:平方取中法:
取key的平方中间的若干位,构成地址。为什么是“居中”呢?因为越是往中间,最终取出的数越是与原数更接近。

散列函数3:折叠法:
将key分割成等宽的若干段,取其总和作为地址。

散列函数4:位异或法:
将key分割成等宽的二进制段,经异或运算得到地址。

总之,散列函数越是随机,越是没有规律,越好。
散列函数5:伪随机数法:
越是随机,越是没有规律。确定+高效+均匀+满射,恰巧这些都是评判伪随机数和评判散列函数的标准。但是创建伪随机数的方法因平台而异。
 散列函数6:多项式法
散列函数6:多项式法
对于英文字符串,将每个字符分解成一个多项式,如1所示,但是其中包含很多的乘法,计算量较为复杂。所以采用方法二替代:遍历整个字符串,首先将每个字符转换为对应的数字,接着对其累加,累积前先对其做移位运算。
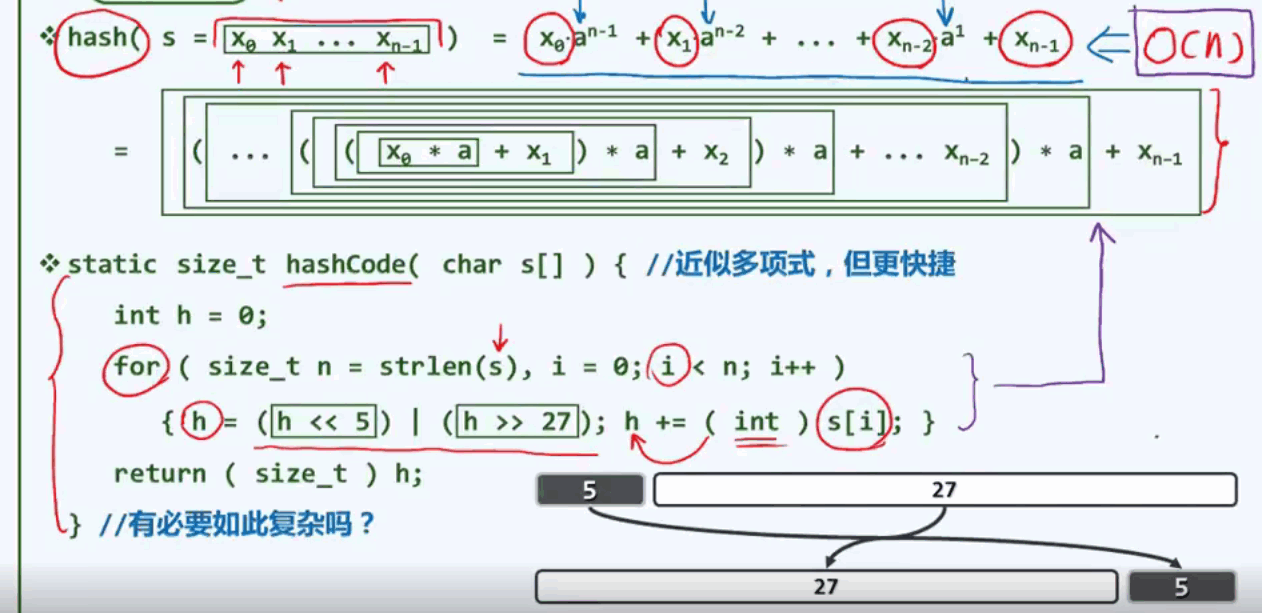
采用如下方法,对于不同的字符串,可能会对应相同的hash code. 汤姆·马沃罗·里德尔(伏地魔名字) 与 伏地魔 与哈利波特(伏地魔的第七个魂器) 具有相同的hash code.所以这种方式会造成很多的冲突。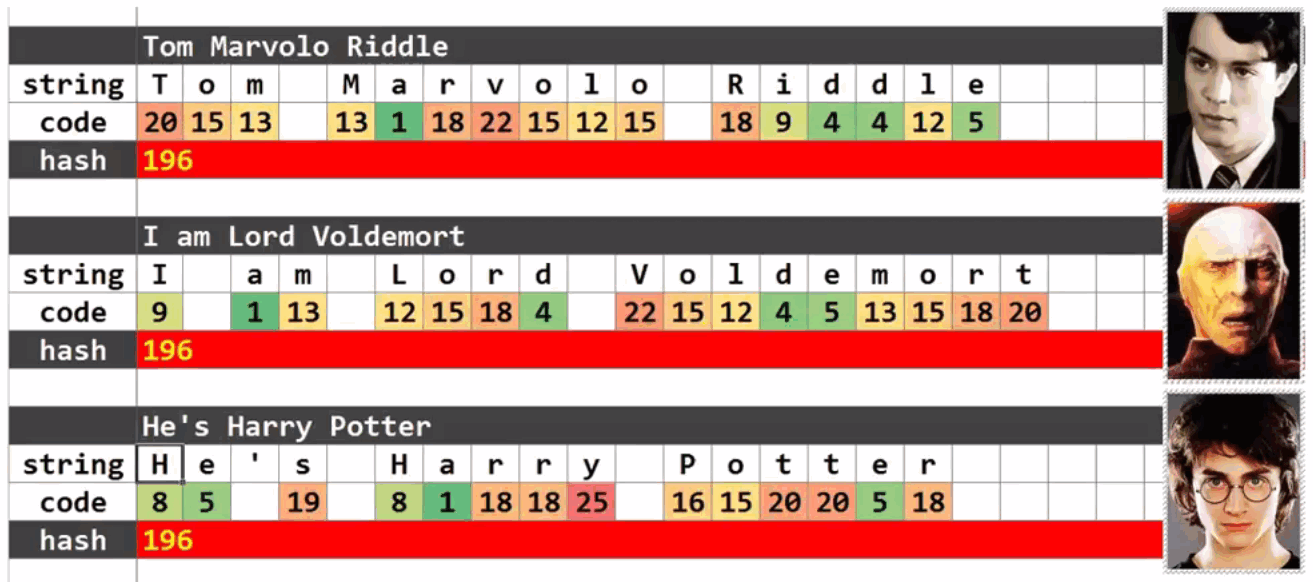
D部分:如何消除冲突?
消除冲突方法1:多槽位法
1.将桶单元细分成若干槽位slot.存放(与同一个单元)相冲突的词条。
2.只要槽位的数目不多,依然能够保持O(1)的效率。
3.但是会存在以下问题:
1)预留过多,空间浪费。
2)预留过少,空间不顾。
改进如下:对于以上问题,显然是vector的缺陷,改用链表即可解决。
消除冲突方法2:独立链法
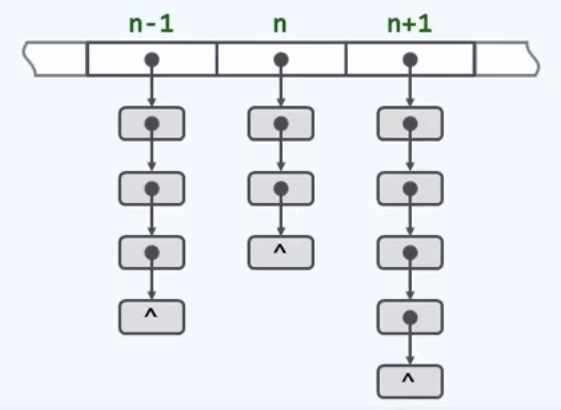
举例如下:

其优点在于无需为多个桶预留多个槽位,任意多次的冲突都可以解决。删除操作实现简单,统一。
其缺点在于指针需要额外的空间,节点需要动态申请。
并且空间分布,未必连续,系统缓存几乎失效。每个桶内部的查找,都是沿着对应的链表顺序进行的,其中一个节点在物理空间上,并不是连续分布的。所以系统无法通过有效的缓存,加速查找过程。当散列表规模较大时,这一缺陷更加明显。
消除冲突方法3:开放定址法:
冲突的排解都在一块连续的空间中排解, 每个桶单元应该面向所有的词条开放,每个词条都有可能存放在任意的桶中。其中优先级最高的是,词条本应归属的桶,构成一个查找链。
会存在以下两种结果:
1.命中成功。
2.抵达一个空桶。
线性试探:一旦冲突,则试探后一个紧邻桶单元,如下图所示:
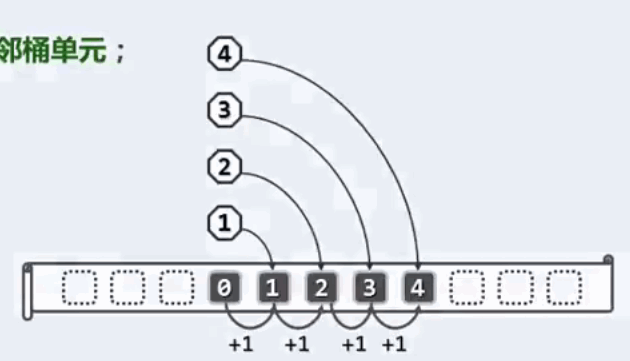
其缺点在于如果一旦发生一个顺序错误,后续的错误也会紧邻发生。
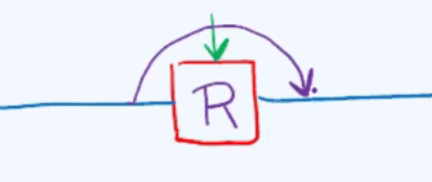
消除冲突方法4:懒惰删除:
若需要删除其中的某一个词条,则仅做删除标记,查找链不必续接。如果发生中断,则应该越过它,继续查找下去。
 消除冲突方法5: 平方试探:
消除冲突方法5: 平方试探:
每次试探的位置不是简单的线性递增,应该以平方数作为距离,确定下一个试探的桶单元。
[ hash(key) + 1 ] % M
[ hash(key) + 4 ] % M
[ hash(key) + 9 ] % M
[ hash(key) + 16 ] % M
[ hash(key) + 25 ] % M
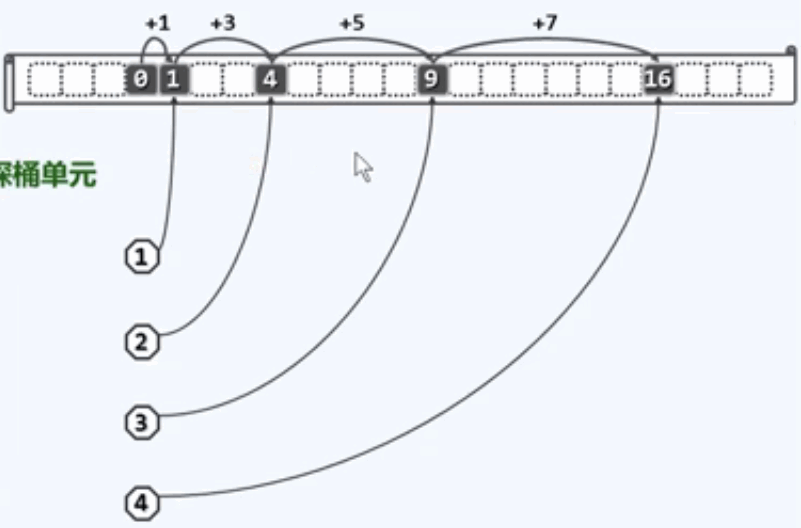
其优点在于数据集聚集的现象有所缓解,查找链上,各个桶之间的间距线性递增。一旦冲突,可聪明的调离是非之地。若涉及外村,I/O将激增。并且散列表中依然存在空桶时,按照这种策略却不能够发现。