SpringCloud学习(一)
SpringCloud学习(一)
本文参考:
https://blog.csdn.net/qq_25928447/article/details/123748607
我的源码:
https://github.com/King-of-makabaka/springcloud_study/blame/main/springcloudstudy.rar
介绍:
我的理解是:微服务是在分布式服务上一步步的升级,只是学习笔记
入口:
分布式服务每次调用服务都需要使用RestTemplate,有没有简化的方法呢?
@Service
public class BorrowServiceImpl implements BorrowService{
@Resource
BorrowMapper mapper;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
//RestTemplate支持多种方式的远程调用
RestTemplate template = new RestTemplate();
//这里通过调用getForObject来请求其他服务,并将结果自动进行封装
//获取User信息
User user = template.getForObject("http://localhost:8082/user/"+uid, User.class);
//获取每一本书的详细信息
List<Book> bookList = borrow
.stream()
.map(b -> template.getForObject("http://localhost:8080/book/"+b.getBid(), Book.class))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
有的,就从Eureka开始吧,哈哈哈!
Eureka注册中心的使用
简单介绍:
Eureka能够自动注册并发现微服务,然后对服务的状态、信息进行集中管理,这样当我们需要获取其他服务的信息时,我们只需要向Eureka进行查询就可以了。
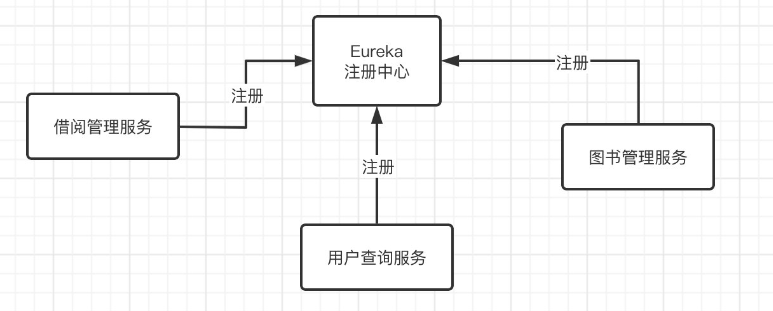
学习Eureka
-
首先在工程中搭建一个Eureka服务器
只需要创建一个新的Maven模块即可

需要父工程有SpringCloud依赖,如果没有添加依赖.
例:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
-
为新创建的模块添加 Eureka 依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
-
创建主类(启动类)
@EnableEurekaServer //开启Eureka
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
-
编写服务端配置文件(这里以
application.yml为例)
server:
port: 8888
eureka:
# 开启之前需要修改一下客户端设置(虽然当前是服务端)
client:
# 由于是作为服务端角色,所以不需要获取服务端,改为false,默认为true
fetch-registry: false
# 暂时不需要将自己也注册到Eureka
register-with-eureka: false
# 将eureka服务端指向自己
service-url:
defaultZone: http://localhost:8888/eureka
-
查看
在浏览器输入 地址+端口 即可访问Eureka的管理后台:
这里是: localhost:8888
现在服务端配置好了,接下来配置客户端
-
配置客户端
例如有 user book borrow 三个客户端
-
导入Eureka客户端依赖
在三个客户端子工程中都加入客户端依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
-
编写客户端配置文件
spring:
application:
name: userservice #想要在页面显示出注册的名称,不写就会默认显示 UNKNOWN
eureka:
client:
service-url: # 需要指向Eureka服务端地址,这样才能进行注册,并被服务端发现
defaultZone: http://localhost:8888/eureka
注意:子工程启动类是不需要添加 @EnableEurekaServer 注解的
-
将客户端和服务端都启动

当服务启动之后,会每隔一段时间跟Eureka发送一次心跳包,这样Eureka就能够感知到服务是否处于正常运行状态。
可以对远程调用进行简化 RestTemplate
原先使用远程调用(使用 服务地址+端口)
User user = template.getForObject("http://localhost:8082/user/"+uid, User.class);
现在使用远程调用(使用 配置文件注册的名称)
User user = template.getForObject("http://userservice/user/"+uid, User.class);
实现高可用
问题:虽然Eureka能够实现服务注册和发现,但是如果Eureka服务器崩溃了,那样所有需要用到服务发现的微服务就挂了
解决:搭建Eurea集群,这样存在多个Eureka服务器,这样就算挂掉其中一个,其他的也还在正常运行
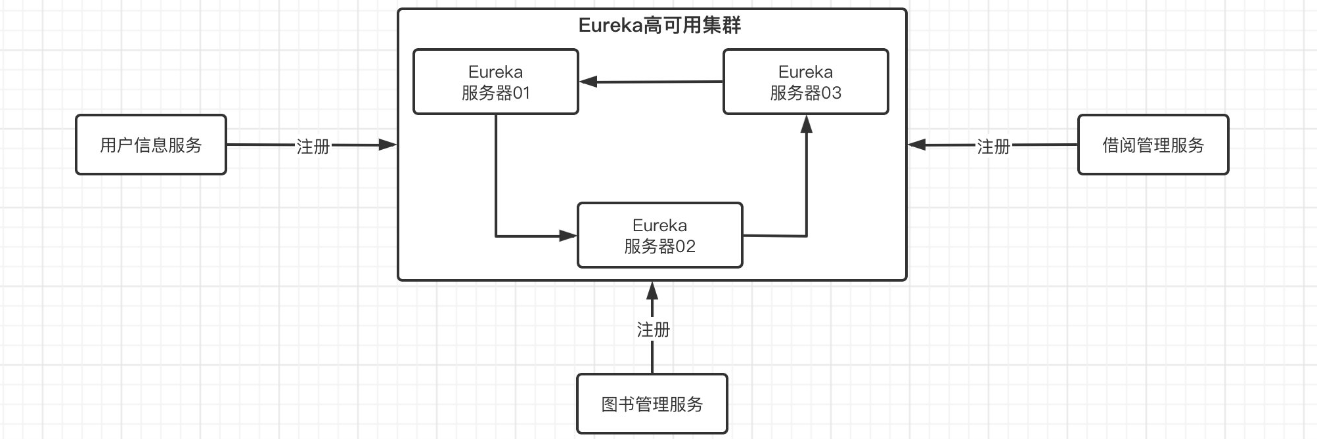
搭建Eureka集群
以搭建两个Eureka为例:
-
配置服务端
需要创建2个服务端配置文件
application-01.yml
server:
port: 8801
spring:
application:
name: eurekaserver
eureka:
instance:
# 由于不支持多个localhost的Eureka服务器,但是又只有本地测试环境,所以就只能自定义主机名称了
# 主机名称改为eureka01
hostname: eureka01
client:
fetch-registry: false
# 去掉register-with-eureka选项,让Eureka服务器自己注册到其他Eureka服务器,这样才能相互启用
service-url:
# 注意这里填写其他Eureka服务器的地址,不用写自己的
defaultZone: http://eureka01:8802/eureka
application-02.yml
server:
port: 8802
spring:
application:
name: eurekaserver
eureka:
instance:
# 由于不支持多个localhost的Eureka服务器,但是又只有本地测试环境,所以就只能自定义主机名称了
# 主机名称改为eureka02
hostname: eureka02
client:
fetch-registry: false
# 去掉register-with-eureka选项,让Eureka服务器自己注册到其他Eureka服务器,这样才能相互启用
service-url:
# 注意这里填写其他Eureka服务器的地址,不用写自己的
defaultZone: http://eureka02:8801/eureka
这里由于修改成自定义的地址,需要在hosts文件中将其解析到172.0.0.1才能回到localhost,Mac下文件路径为/etc/hosts,Windows下为C:\Windows\system32\drivers\etc\hosts
在文件中添加
127.0.0.1 eureka01
127.0.0.1 eureka02
-
配置客户端
分别将各个客户端eureka配置修改
eureka:
client:
service-url:
# 将两个Eureka的地址都加入,这样就算有一个Eureka挂掉,也能完成注册
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
实现负载均衡
-
使用Eureka+SpringCloud自带的负载均衡
手动将RestTemplate声明为一个Bean,然后添加@LoadBalanced注解,这样Eureka就会对服务的调用进行自动发现,并提供负载均衡:
@Configuration
public class BeanConfig {
@Bean
@LoadBalanced
RestTemplate template(){
return new RestTemplate();
}
}
在2020年前的SpringCloud版本是采用Ribbon作为负载均衡实现,但是2020年的版本之后SpringCloud把Ribbon移除了,进而用自己编写的LoadBalancer替代。
那么,负载均衡是如何进行的呢?
-
解析负载均衡
在添加@LoadBalanced注解之后,会启用拦截器对我们发起的服务调用请求进行拦截(注意这里是针对我们发起的请求进行拦截),叫做LoadBalancerInterceptor,它实现ClientHttpRequestInterceptor接口:
@FunctionalInterface
public interface ClientHttpRequestInterceptor {
ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException;
}
主要是对intercept方法的实现:
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));
}
服务端会在发起请求时执行这些拦截器。
最后给过来的请求地址,并不是一个有效的主机名称,而是服务名称,要得到真正需要访问的主机名称呢,还是得找Eureka获取的。
然后执行loadBalancer.execute(),具体实现为BlockingLoadBalancerClient
//从上面给进来了服务的名称和具体的请求实体
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
String hint = this.getHint(serviceId);
LoadBalancerRequestAdapter<T, DefaultRequestContext> lbRequest = new LoadBalancerRequestAdapter(request, new DefaultRequestContext(request, hint));
Set<LoadBalancerLifecycle> supportedLifecycleProcessors = this.getSupportedLifecycleProcessors(serviceId);
supportedLifecycleProcessors.forEach((lifecycle) -> {
lifecycle.onStart(lbRequest);
});
//可以看到在这里会调用choose方法自动获取对应的服务实例信息
ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);
if (serviceInstance == null) {
supportedLifecycleProcessors.forEach((lifecycle) -> {
lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));
});
//没有发现任何此服务的实例就抛异常(之前的测试中可能已经遇到了)
throw new IllegalStateException("No instances available for " + serviceId);
} else {
//成功获取到对应服务的实例,这时就可以发起HTTP请求获取信息了
return this.execute(serviceId, serviceInstance, lbRequest);
}
}
所以,实际上在进行负载均衡的时候,会向Eureka发起请求,选择一个可用的对应服务,然后会返回此服务的主机地址等信息
LoadBalancer默认提供了两种负载均衡策略:
- RandomLoadBalancer - 随机分配策略
- (默认) RoundRobinLoadBalancer - 轮询分配策略
如果希望修改默认的负载均衡策略,可以进行自定义负载均衡,比如现在希望用户服务采用随机分配策略,我们需要先创建随机分配策略的配置类(不用加@Configuration)
-
自定义负载均衡
- 自定义负载均衡类
public class LoadBalancerConfig {
//将官方提供的 RandomLoadBalancer 注册为Bean
@Bean
public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory){
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}
- 接着使用注解为对应的服务指定负载均衡策略
@Configuration
@LoadBalancerClient(value = "userservice", //指定为 userservice 服务,只要是调用此服务都会使用我们指定的策略
configuration = LoadBalancerConfig.class) //指定之前定义好的配置类
public class BeanConfig {
@Bean
@LoadBalanced
RestTemplate template(){
return new RestTemplate();
}
}
OpenFeign实现负载均衡
Feign和RestTemplate一样,也是HTTP客户端请求工具,但是它的使用方式更加便捷
-
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
-
使用
在启动类添加@EnableFeignClients注解
@SpringBootApplication
@EnableFeignClients//开启OpenFeign
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
需要调用其他微服务提供的接口,直接创建一个对应服务的接口类即可,例:
以前:
RestTemplate template = new RestTemplate();
User user = template.getForObject("http://userservice/user/"+uid, User.class);
现在:
//声明为userservice服务的HTTP请求客户端,替代手写远程调用
@FeignClient("userservice")
public interface UserClient {
@RequestMapping("/user/{uid}")//路径保证和其他微服务提供的一致即可
User getUserById(@PathVariable("uid") int uid); //参数和返回值也保持一致
}
在服务类中直接注入使用
@Resource
private UserClient userClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
//现在远程调用
User user = userClient.getUserById(uid);
//这是以前远程调用,需要RestTemplate
@Resource
private RestTemplate restTemplate;
List<Book> bookList = borrow
.stream()
.map(b -> template.getForObject("http://bookservice/book/"+b.getBid(), Book.class))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
完全修改后:
@Service
public class BorrowServiceImpl implements BorrowService {
@Resource
BorrowMapper mapper;
@Resource
UserClient userClient;
@Resource
BookClient bookClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
Feign也有很多的其他配置选项,这里就不多做介绍了,详细请查阅官方文档。
官方文档:https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
Hystrix 服务熔断
微服务之间是可以进行相互调用的,那么如果出现了下面的情况会导致什么问题?

由于位于最底端的服务提供者E发生故障,那么此时会直接导致服务ABCD全线崩溃,就像雪崩了一样。

这种问题实际上是不可避免的,由于多种因素,比如网络卡顿、系统故障、硬件问题等,都存在一定可能,会导致这种极端的情况发生。
为了解决分布式系统的雪崩问题,SpringCloud提供了Hystrix熔断器组件,他就像我们家中的保险丝一样,当电流过载就会直接熔断,防止危险进一步发生,从而保证家庭用电安全。可以想象一下,如果整条链路上的服务已经全线崩溃,这时还在不断地有大量的请求到达,需要各个服务进行处理,肯定是会使得情况越来越糟糕的。
-
服务降级
注意一定要区分开服务降级和服务熔断的区别,服务降级并不会直接返回错误,而是可以提供一个补救措施,正常响应给请求者。这样相当于服务依然可用,但是服务能力肯定是下降了的。
基于借阅管理服务来进行举例,不开启用户服务和图书服务,表示用户服务和图书服务已经挂掉了。
- 导入Hystrix的依赖(此项目已经停止维护,SpringCloud依赖中已经不自带了,所以说需要自己单独导入)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.10.RELEASE</version>
</dependency>
- 需要在启动类添加注解开启
@SpringBootApplication
@EnableHystrix //启用Hystrix
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
现在,由于用户服务和图书服务不可用,所以查询借阅信息的请求肯定是没办法正常响应的,这时可以提供一个备选方案,也就是说当服务出现异常时,返回备选方案
@RestController
public class BorrowController {
@Resource
private BorrowService service;
@HystrixCommand(fallbackMethod = "onError")//当服务出现故障使用备选方案,指定的备选方案
@RequestMapping("/borrow/{id}")
public BorrowDetail getById(@PathVariable Long id) {
return service.getByUid(id);
}
//备选方案(补救措施),这里直接返回空列表了
//注意参数和返回值要和上面的一致
public BorrowDetail onError(Long id) {
return new BorrowDetail(null, Collections.emptyList());
}
}
虽然服务无法正常运行了,但是依然可以给浏览器正常返回响应数据


服务降级是一种比较温柔的解决方案,虽然服务本身的不可用,但是能够保证正常响应数据。
-
服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制,当检测出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。当检测到该节点微服务响应正常后恢复调用链路。
实际上,熔断就是在降级的基础上进一步升级形成的,也就是说,在一段时间内多次调用失败,那么就直接升级为熔断。
Hystrix能够对一段时间内出现的错误进行侦测,当侦测到出错次数过多时,熔断器会打开,所有的请求会直接响应失败,一段时间后,只执行一定数量的请求,如果还是出现错误,那么则继续保持打开状态,否则说明服务恢复正常运行,关闭熔断器。

-
OpenFeign实现降级
Hystrix也可以配合Feign进行降级,可以对应接口中定义的远程调用单独进行降级操作。
比如还是以用户服务挂掉为例,那么这个时候肯定是会远程调用失败的,也就是说Controller中的方法在执行过程中会直接抛出异常,进而被Hystrix监控到并进行服务降级。
而实际上导致方法执行异常的根源就是远程调用失败,所以既然用户服务调用失败,那么就给这个远程调用添加一个替代方案,如果此远程调用失败,那么就直接上替代方案。那么怎么实现替代方案呢?Feign都是以接口的形式来声明远程调用,那么既然远程调用已经失效,那就自行对其进行实现
- 创建一个实现类,对原有的接口方法进行替代方案实现
@Component //需要将其注册为Bean,Feign才能自动注入
public class UserFallbackClient implements UserClient{//实现client接口,返回替代方案
@Override
public User getById(Long id) {
User user = new User();
user.setName("补救措施");
return user;
}
}
- 实现完成后,只需要在原有的接口中指定失败替代实现即可
//声明为userservice服务的HTTP请求客户端,替代手写远程调用
//fallback为实现了client接口的用于 替代方案 的实现类
@FeignClient(value = "userservice",fallback = UserFallbackClient.class)
public interface UserClient {
@RequestMapping("/user/{id}")
User getById(@PathVariable Long id);
}
- 在配置文件中开启熔断支持
feign:
circuitbreaker:
enabled: true
去掉之前BorrowController的@HystrixCommand注解和备选方法
除了对服务的降级和熔断处理,还可以对其进行实时监控,只需要安装监控页面即可
-
页面监控部署
- 新建一个模块,并导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
<version>2.2.10.RELEASE</version>
</dependency>
- 添加配置文件
server:
port: 8900
hystrix:
dashboard:
# 将localhost添加到白名单,默认是不允许的
proxy-stream-allow-list: "localhost"
- 创建主类
注意需要添加
@EnableHystrixDashboard注解开启管理页面
@SpringBootApplication
@EnableHystrixDashboard
public class HystrixDashBoardApplication {
public static void main(String[] args) {
SpringApplication.run(HystrixDashBoardApplication.class, args);
}
}
- 在要进行监控的服务中添加Actuator依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
Actuator是SpringBoot程序的监控系统,可以实现健康检查,记录信息等。在使用之前需要引入spring-boot-starter-actuator,并做简单的配置即可。
- 在需要被监控的配置文件中配置Actuator添加暴露
management:
endpoints:
web:
exposure:
include: '*'
- 启动,打开管理页面
在中间填写要监控的服务:比如借阅服务:http://localhost:8301/actuator/hystrix.stream,注意后面要添加/actuator/hystrix.stream,然后点击Monitor Stream即可进入监控页面

可以看到现在都是Loading状态,这是因为还没有开始统计,在尝试调用几次服务后就可以看到监控页面信息了
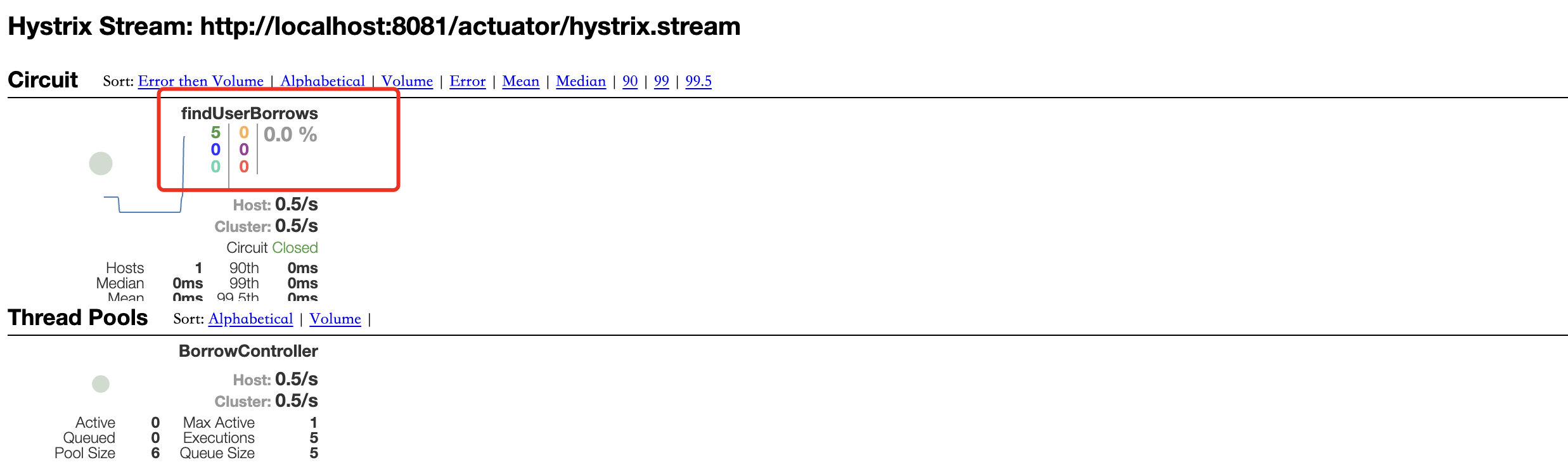
可以看到5次访问都是正常的,所以显示为绿色,接着尝试将图书服务关闭,这样就会导致服务降级甚至熔断,然后再多次访问此服务看看监控会如何变化
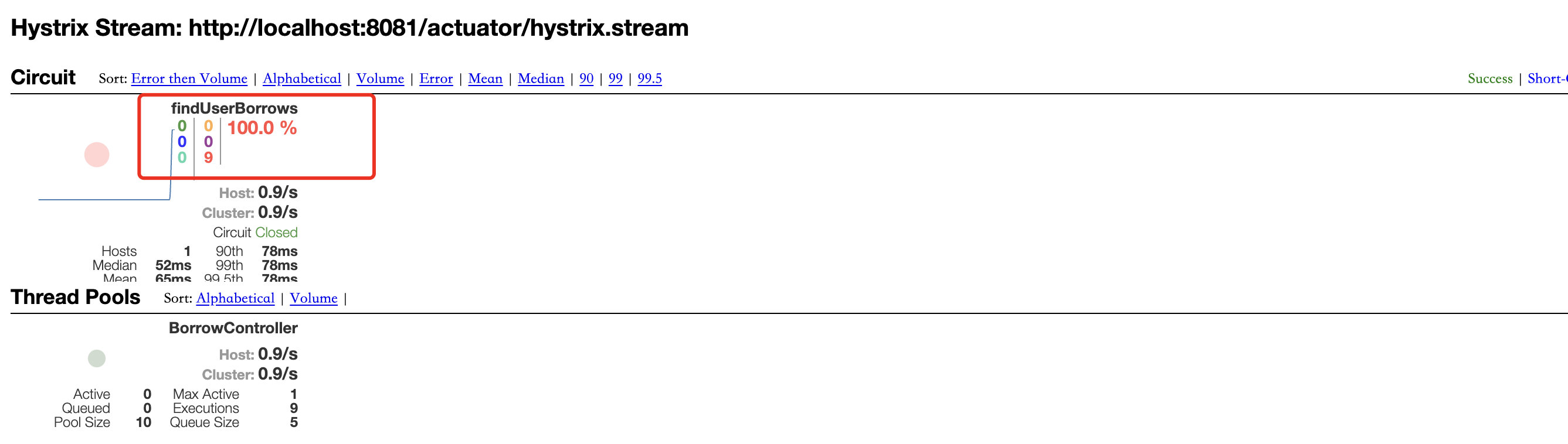
可以看到,错误率直接飙升到100%,并且一段时间内持续出现错误,中心的圆圈也变成了红色,继续进行访问
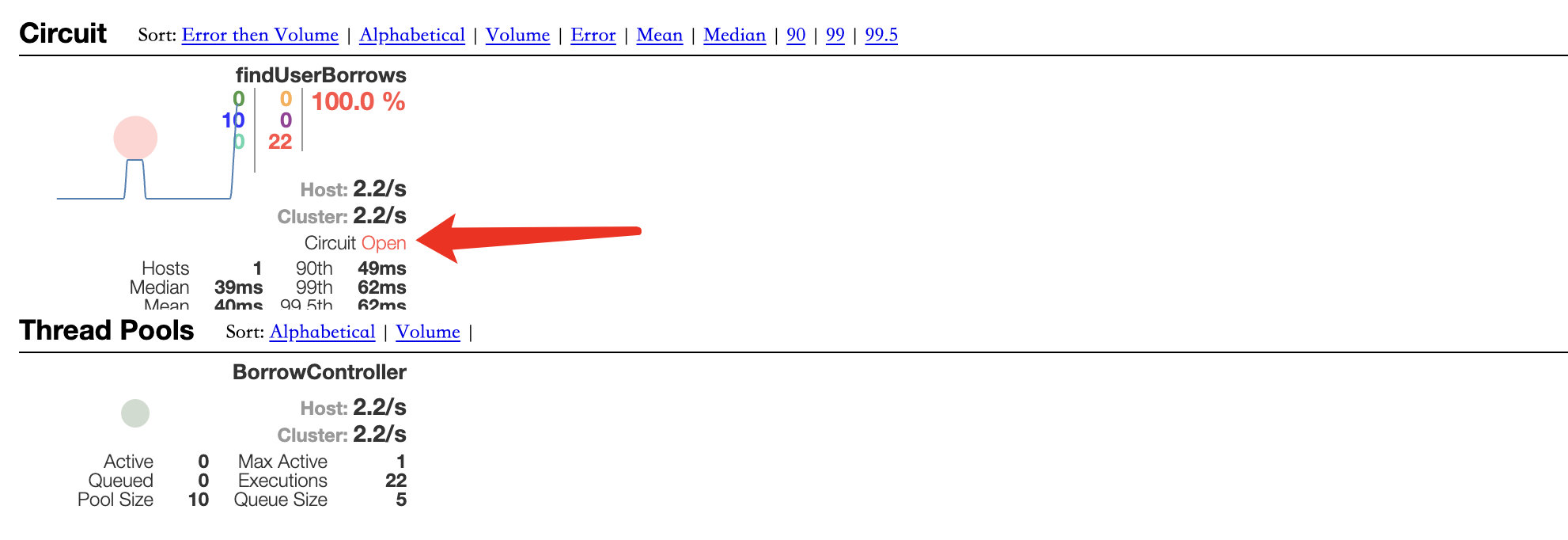
在出现大量错误的情况下保持持续访问,可以看到此时已经将服务熔断,Circuit更改为Open状态,并且图中的圆圈也变得更大,表示压力在持续上升。
当停止调用或者调用服务成功过段时间,Circuit又会变为Close状态
GateWay 路由网关
官网地址:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
为了安全,一般情况下,可能并不是所有的微服务都需要直接暴露给外部调用,这时就可以使用8路由机制,添加一层防护,让所有的请求全部通过路由来转发到各个微服务,并且转发给多个相同微服务实例也可以实现负载均衡。
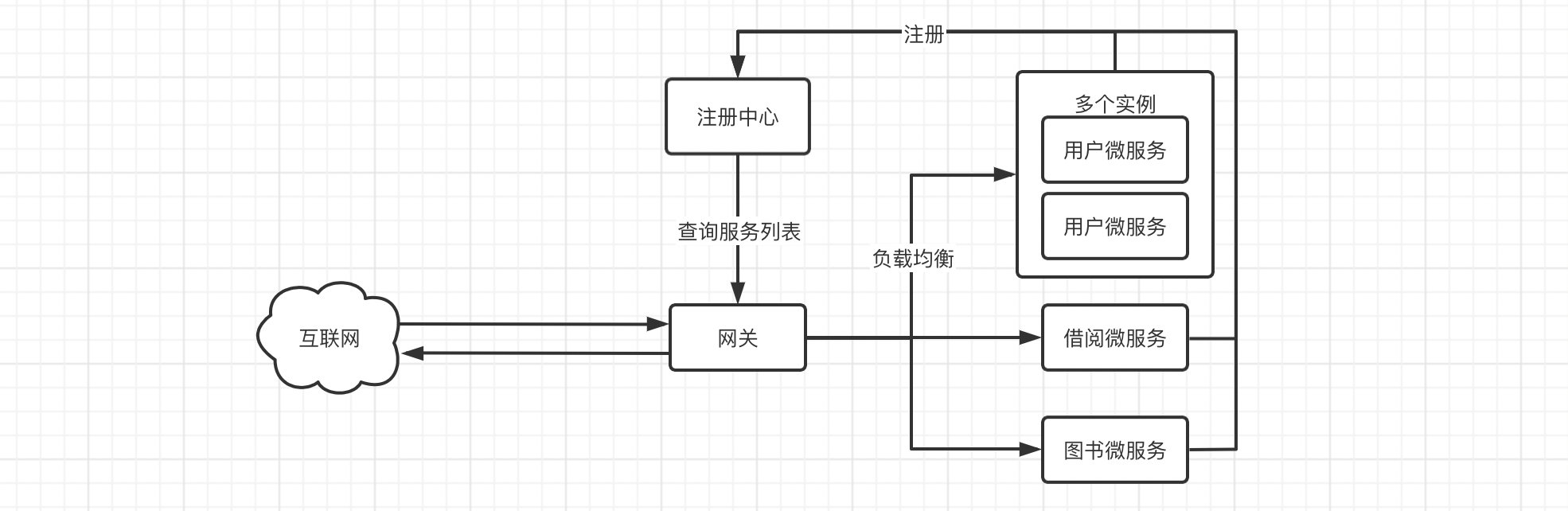
在之前,路由的实现一般使用Zuul,但是已经停更,而现在新出现了由SpringCloud官方开发的Gateway路由,它相比Zuul不仅性能上得到了一定的提升,并且是官方推出,契合性也会更好,所以就用Gateway。
部署网关
- 新建一个模块,作为网关,并添加依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
第一个依赖就是网关的依赖,而第二个则跟其他微服务一样,需要注册到Eureka才能生效,注意别添加Web依赖,使用的是WebFlux框架。
- 编写配置文件
server:
port: 8500
eureka:
client:
service-url:
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
spring:
application:
name: gateway
cloud:
gateway:
# 配置路由,注意这里是个列表,每一项都包含了很多信息
routes:
- id: borrow-service # 路由名称
#uri: lb://borrowservice # 路由的地址,lb表示使用负载均衡到微服务,也可以使用http正常转发
uri: http://localhost:8301 #上面不能用,可能是版本问题
predicates: # 路由规则,断言什么请求会被路由
- Path=/borrow/** # 只要是访问的这个路径,一律都被路由到上面指定的服务
- 现在通过路由访问,依然能获取到服务

这样就可以将不需要外网直接访问的微服务全部放到内网环境下,而只依靠网关来对外进行交涉。
路由过滤器
路由过滤器支持以某种方式修改传入的 HTTP 请求或传出的 HTTP 响应,路由过滤器的范围是某一个路由,跟之前的断言一样,Spring Cloud Gateway 也包含许多内置的路由过滤器工厂,详细列表:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gatewayfilter-factories
比如现在希望在请求到达时,在请求头中添加一些信息再转发给服务,那么这个时候就可以使用路由过滤器来完成,只需要对配置文件进行修改
server:
port: 8500
eureka:
client:
service-url:
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
spring:
application:
name: gateway
cloud:
gateway:
# 配置路由,注意这里是个列表,每一项都包含了很多信息
routes:
- id: borrow-service # 路由名称
# uri: lb://borrowservice # 路由的地址,lb表示使用负载均衡到微服务,也可以使用http正常转发
uri: http://localhost:8301 #上面不能用,可能是版本问题
predicates: # 路由规则,断言什么请求会被路由
- Path=/borrow/** # 只要是访问的这个路径,一律都被路由到上面指定的服务
- id : book-service
# uri: lb://bookservice
uri: http://localhost:8201
predicates:
- Path=/book/**
filters: #添加过滤器
- AddRequestHeader=Test, HelloWorld! #添加请求头信息
然后再Controller层用HttpServletRequest获取头信息 Test(request.getHeader("Test"))就可以获取到 HelloWorld!

除了针对于某一个路由配置过滤器之外,也可以自定义全局过滤器,它能够作用于全局。但是需要通过代码的方式进行编写,比如要实现拦截没有携带指定请求参数的请求
- 编写判断
/**
* 全局过滤器
*/
@Component//需要注册为bean
public class TestFilter implements GlobalFilter{
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//先获取ServerHttpRequest对象,注意不是HttpServletRequest
ServerHttpRequest request = exchange.getRequest();
//打印一下所有的请求参数
System.out.println(request.getQueryParams());
System.out.println(request.getHeaders().get("Test"));
//判断是否包含test参数,且参数值为1
List<String> value = request.getQueryParams().get("test");
if(value != null && value.contains("1")) {
//将ServerWebExchange向过滤链的下一级传递(跟JavaWeb中介绍的过滤器其实是差不多的)
return chain.filter(exchange);
}else {
//直接在这里不再向下传递,然后返回响应
return exchange.getResponse().setComplete();
}
}
- 观察结果
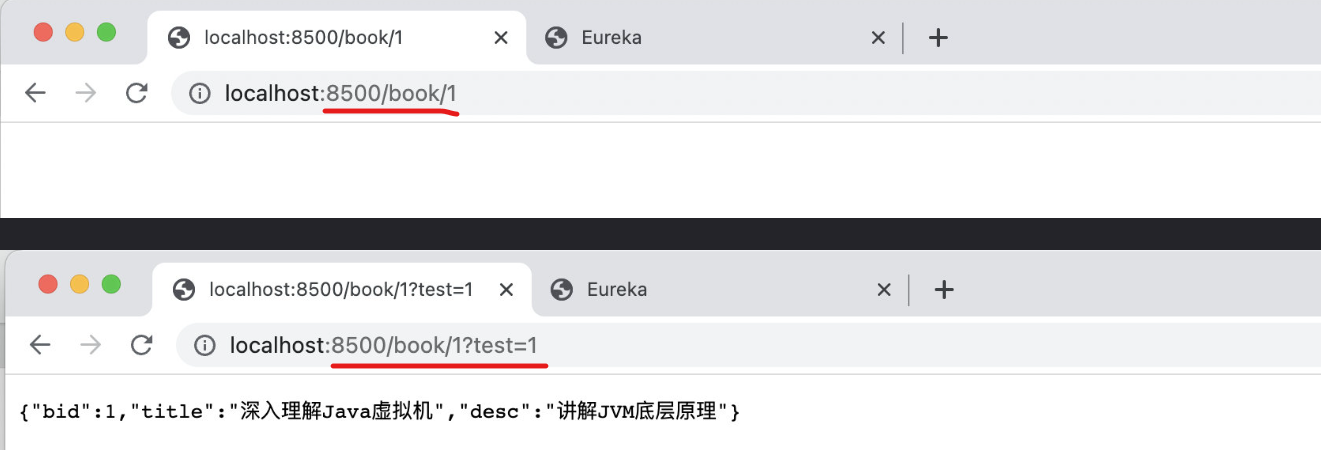
成功实现规则判断和拦截操作
过滤器肯定是可以存在很多个的,可以手动指定过滤器之间的顺序
/**
/**
* 全局过滤器
*/
@Component//需要注册为bean
public class TestFilter implements GlobalFilter , Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//先获取ServerHttpRequest对象,注意不是HttpServletRequest
ServerHttpRequest request = exchange.getRequest();
//打印一下所有的请求参数
System.out.println(request.getQueryParams());
System.out.println(request.getHeaders().get("Test"));
//判断是否包含test参数,且参数值为1
List<String> value = request.getQueryParams().get("test");
if(value != null && value.contains("1")) {
//将ServerWebExchange向过滤链的下一级传递(跟JavaWeb中介绍的过滤器其实是差不多的)
return chain.filter(exchange);
}else {
//直接在这里不再向下传递,然后返回响应
return exchange.getResponse().setComplete();
}
}
/**
* 根据order值,指定过滤器的顺序,order值越小优先级越高,配置文件配置的过滤器默认是 1 ;
* 当全局过滤器与配置文件优先级冲突时,全局优先
* @return
*/
@Override
public int getOrder() {//配置全局过滤器优先级
return 2;
}
}
注意Order的值越小优先级越高,并且无论是在配置文件中编写的单个路由过滤器还是全局路由过滤器,都会受到Order值影响(单个路由的过滤器Order值按从上往下的顺序从1开始递增),最终是按照Order值决定哪个过滤器优先执行,当Order值一样时 全局路由过滤器执行 优于 单独的路由过滤器执行。
Config 控制中心
官方文档:https://docs.spring.io/spring-cloud-config/docs/current/reference/html/
如果微服务项目需要部署很多个实例,那么配置文件就要一个一个去改,可能十几个实例还好,要是有几十个上百个呢?一个一个去配置,就太花时间和人力了。
所以,需要一种更加高级的集中化地配置文件管理工具,集中地对配置文件进行配置。
Spring Cloud Config 为分布式系统中的外部配置提供服务器端和客户端支持。使用 Config Server,可以集中管理所有环境中应用程序的外部配置
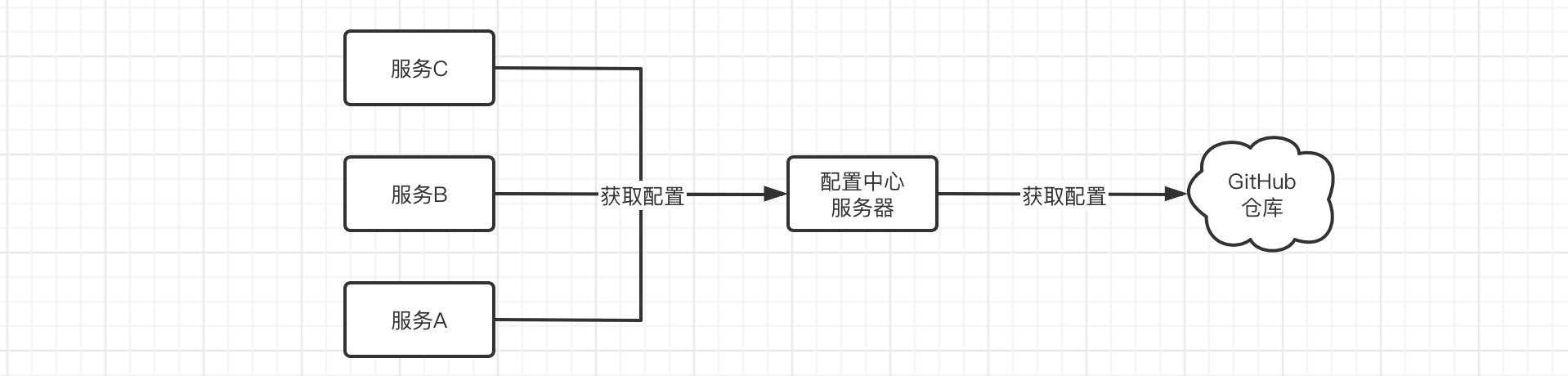
实际上Spring Cloud Config就是一个配置中心,所有的服务都可以从配置中心取出配置,而配置中心又可以从GitHub远程仓库中获取云端的配置文件,这样只需要修改GitHub中的配置即可对所有的服务进行配置管理了。
部署配置中心
- 新建一个模块,导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
- 启动类开启ConfigServer
@SpringBootApplication
@EnableConfigServer
public class ConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigApplication.class, args);
}
}
- 编写服务端配置文件
server:
port: 8700
spring:
application:
name: configserver
eureka:
client:
service-url:
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
这里以本地仓库为例:
创建一个本地仓库,在本地仓库里创建需要管理的配置文件
注意名称最好是{服务名称}-{环境}.yml
例:

然后在配置文件中,添加本地仓库的一些信息(远程仓库同理)
详细使用教程:https://docs.spring.io/spring-cloud-config/docs/current/reference/html/#_git_backend
server:
port: 8700
spring:
application:
name: configserver
cloud:
config:
server:
git:
# 这里填写的是本地仓库地址,远程仓库直接填写远程仓库地址 http://git...
uri: D:/idea_workspace/springcloudstudy/config-repo
# 默认分支设定为你自己本地或是远程分支的名称
default-label: master
eureka:
client:
service-url:
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
启动配置服务器,通过以下格式进行访问:
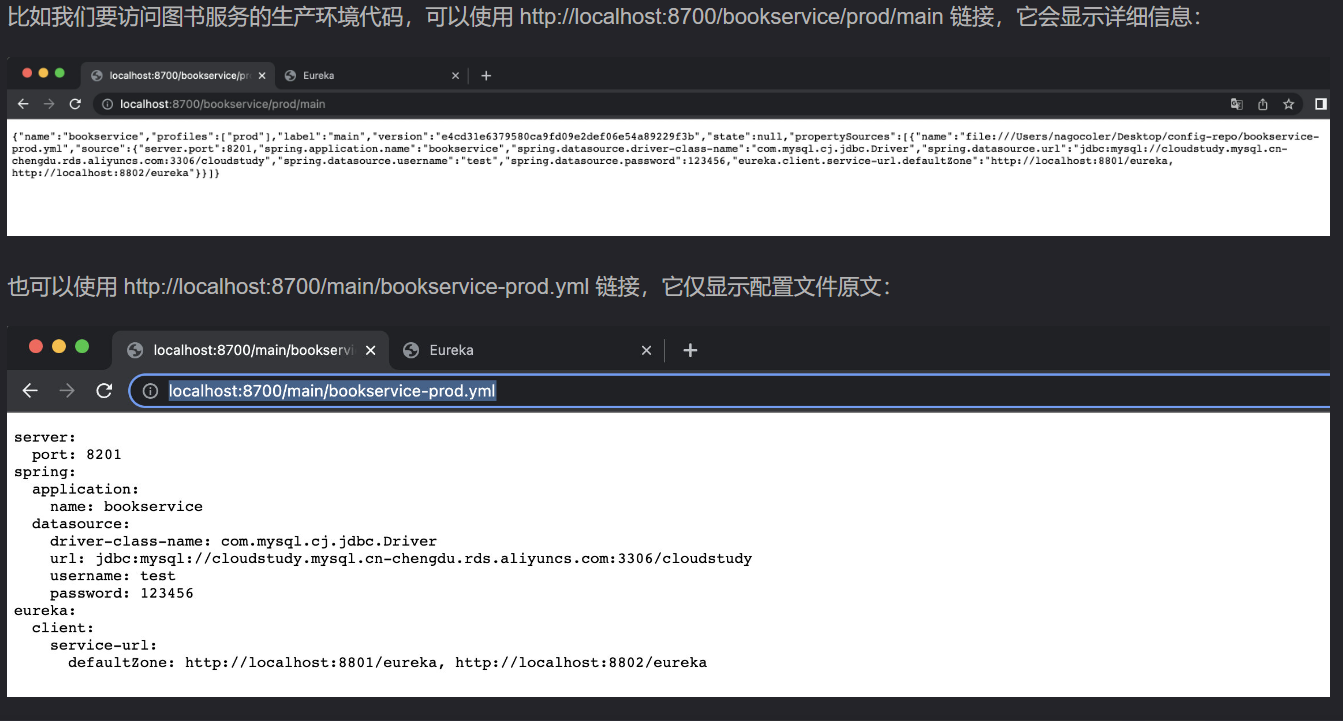
除了使用Git来保存之外,还支持一些其他的方式,详细情况请查阅官网。
- 编写客户端配置文件
服务既然需要从服务器读取配置文件,那么就需要进行一些配置,删除原来的application.yml文件(也可以保留,最后无论是远端配置还是本地配置都会被加载),改用bootstrap.yml(在application.yml之前加载,可以实现配置文件远程获取):
- 添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
- 在本地仓库中加入需要远程管理的配置
例如:
spring:
application:
name: bookservice
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/cloudstudy
username: root
password: 081901
- 最后一步在bootstrap.yml中加入远程配置
spring:
cloud:
config: #从远端获取配置信息
# 名称,其实就是文件名称
name: bookservice
# 配置服务器的地址
uri: http://localhost:8700
# 环境
profile: dev
# 分支
label: master
理论知识:微服务 CAP 原则
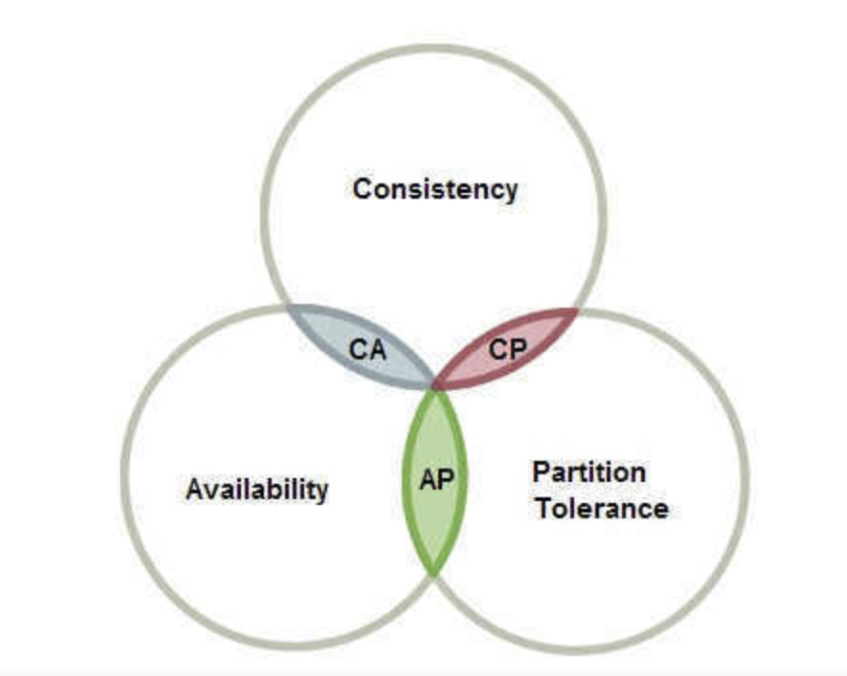
CAP原则又称CAP定理,指的是在一个分布式系统中,存在Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可同时保证,最多只能保证其中的两者。
一致性(C):在分布式系统中的所有数据备份,在同一时刻都是同样的值(所有的节点无论何时访问都能拿到最新的值)
可用性(A):系统中非故障节点收到的每个请求都必须得到响应(比如使用服务降级和熔断,其实就是一种维持可用性的措施,虽然服务返回的是没有什么意义的数据,但是不至于用户的请求会被服务器忽略)
分区容错性(P):一个分布式系统里面,节点之间组成的网络本来应该是连通的,然而可能因为一些故障(比如网络丢包等,这是很难避免的),使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中(这样就可能出现某些被分区节点存放的数据访问失败,需要来容忍这些不可靠的情况)
总的来说,数据存放的节点数越多,分区容忍性就越高,但是要复制更新的次数就越多,一致性就越难保证。同时为了保证一致性,更新所有节点数据所需要的时间就越长,那么可用性就会降低。
所以,只能存在以下三种方案:
AC 可用性+一致性
要同时保证可用性和一致性,代表着某个节点数据更新之后,需要立即将结果通知给其他节点,并且要尽可能的快,这样才能及时响应保证可用性,这就对网络的稳定性要求非常高,但是实际情况下,网络很容易出现丢包等情况,并不是一个可靠的传输,如果需要避免这种问题,就只能将节点全部放在一起,但是这显然违背了分布式系统的概念,所以对于分布式系统来说,很难接受。
CP 一致性+分区容错性
为了保证一致性,那么就得将某个节点的最新数据发送给其他节点,并且需要等到所有节点都得到数据才能进行响应,同时有了分区容错性,那么就代表可以容忍网络的不可靠问题,所以就算网络出现卡顿,那么也必须等待所有节点完成数据同步,才能进行响应,因此就会导致服务在一段时间内完全失效,所以可用性是无法得到保证的。
AP 可用性+分区容错性
既然CP可能会导致一段时间内服务得不到任何响应,那么要保证可用性,就只能放弃节点之间数据的高度统一,也就是说可以在数据不统一的情况下,进行响应,因此就无法保证一致性了。虽然这样会导致拿不到最新的数据,但是只要数据同步操作在后台继续运行,一定能够在某一时刻完成所有节点数据的同步,那么就能实现最终一致性,所以AP实际上是最能接受的一种方案。
比如Eureka集群,它使用的就是AP方案,Eureka各个节点都是平等的,少数节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka客户端在向某个Eureka服务端注册时如果发现连接失败,则会自动切换至其他节点。只要有一台Eureka服务器正常运行,那么就能保证服务可用(A),只不过查询到的信息可能不是最新的(C)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号