
K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
import matplotlib.pylab as plt from sklearn.cluster import KMeans import matplotlib.image as img import numpy as np #读取图片 image=img.imread('d:\\xj3.jpg') plt.imshow(image) plt.show() #数据转化为线性 X=image.reshape(-1,3) #建立模型。确定聚类中心数 model=KMeans(64) labels=model.fit_predict(X) colors=model.cluster_centers_ #用聚类中心的颜色代替原来的颜色值 new_image=colors[labels].reshape(image.shape) #显示压缩后的图片 plt.imshow(new_image.astype(np.uint8)) plt.imshow(new_image.astype(np.uint8)[::3,::3]) #存储图片 import matplotlib.image as img img.imsave('d:\\zzj-02.jpg',new_image.astype(np.uint8)) img.imsave('d:\\zzj-03.jpg',new_image.astype(np.uint8)[::3,::3])
查看图片大小:
图片对比:
原图:

zzj-02.jpg:

zzj-03.jpg:

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
天气空气质量评级聚类:
采集以及预处理数据:
import requests from bs4 import BeautifulSoup #每个省的省会城市网址后缀 list=[101010100,101020100,101030100,101040100,101050101,101060101,101070101,101080101,101090101,101100101,101110101,101120101,101130101,101140101,101150101 ,101160101,101170101,101180101,101190101,101200101,101210101,101220101,101230101,101240101,101250101,101260101,101270101,101280101,101290101,101300101 ,101310101,101320101,101330101] #爬取数据函数 def resxxx(url): res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser') info=[0,0,0,0,0,0] info_value=['PM2.5','PM10','O3','NO2','SO2','CO'] for i in range(len(soup.select('.badthing-name span'))): for j in range(6): if(soup.select('.badthing-name span')[i].text==info_value[j]): info[j]=soup.select('.badthing-des .g-fl')[i].text info.append(soup.select('.mh-pm25-num')[0].text) info.append(soup.select('.mh-pm25-txt')[0].text) info.append(soup.select('.change-title')[0].text) return info #建立空白集合 import pandas as pd df=pd.DataFrame(columns=['PM2.5','PM10','O3','NO2','SO2','CO','空气质量','空气评级','地点']) total=[] for i in list: #通过省会城市获得所有城市的后缀 res = requests.get('https://tianqi.so.com/air/'+str(i)) soup = BeautifulSoup(res.text, 'html.parser') for j in range(len(soup.select('.js-town option'))): url = 'https://tianqi.so.com/air/' + soup.select('.js-town option')[j].attrs['data-citycode'] result = resxxx(url) total.append(result) df.loc[len(df)]=result print(result) #存储得到的数据 df.to_csv('./olddata.csv') print(len(total)) print(total) data=pd.read_csv("./olddata.csv") #数据处理转化类型 data[['PM2.5','PM10','O3','NO2','SO2','CO','空气质量']]=data[['PM2.5','PM10','O3','NO2','SO2','CO','空气质量']].astype('int') data.loc[data['空气评级']=='优','空气评级']=1 data.loc[data['空气评级']=='良','空气评级']=2 data.loc[data['空气评级']=='轻度污染','空气评级']=3 data.loc[data['空气评级']=='中度污染','空气评级']=4 data.loc[data['空气评级']=='重度污染','空气评级']=5 data['空气评级']=data['空气评级'].astype('int') data.to_csv('./newdata.csv')
旧数据: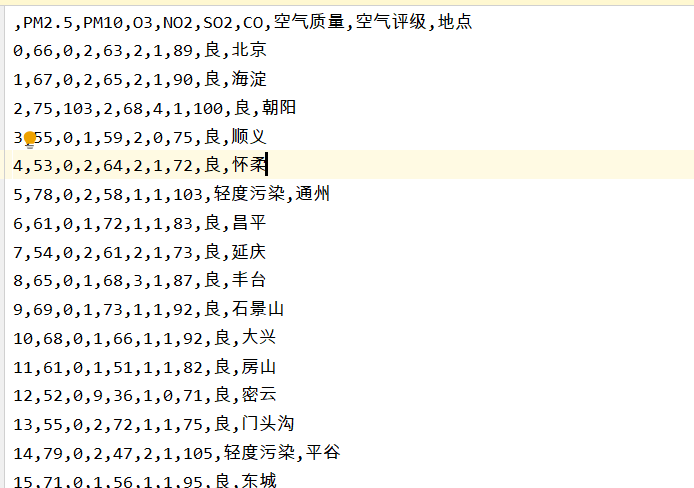
预处理后的数据:
模型建立预测:
import pandas as pd data=pd.read_csv("./newdata.csv") from sklearn.cluster import KMeans import matplotlib.pylab as plt model=KMeans(n_clusters=5).fit_predict(data.iloc[:,2:4]) #数据预测散点图 plt.scatter(data.iloc[:,2],data.iloc[:,3],c=model,s=50,cmap='rainbow') #实际情况散点图 plt.scatter(data.iloc[:,2],data.iloc[:,3],c=data.iloc[:,9],s=50,cmap='rainbow')
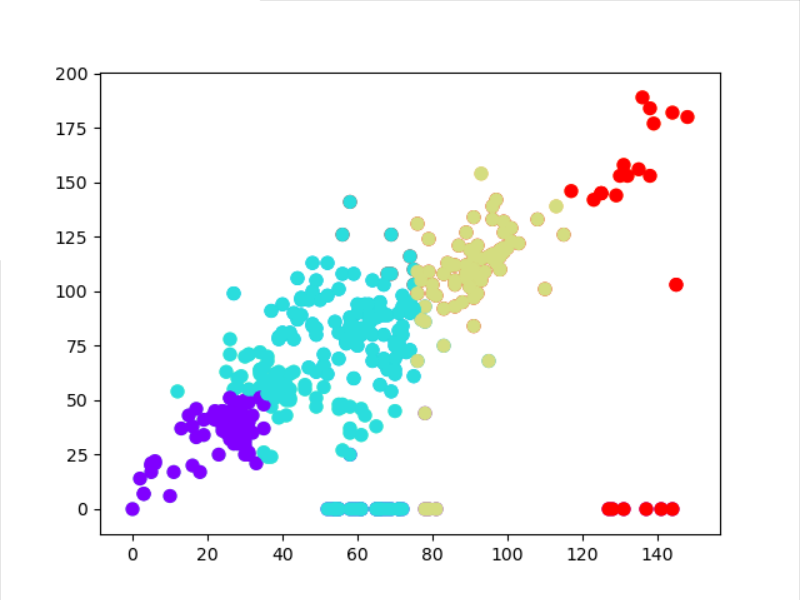
分类对比:
实际情况:
预测情况: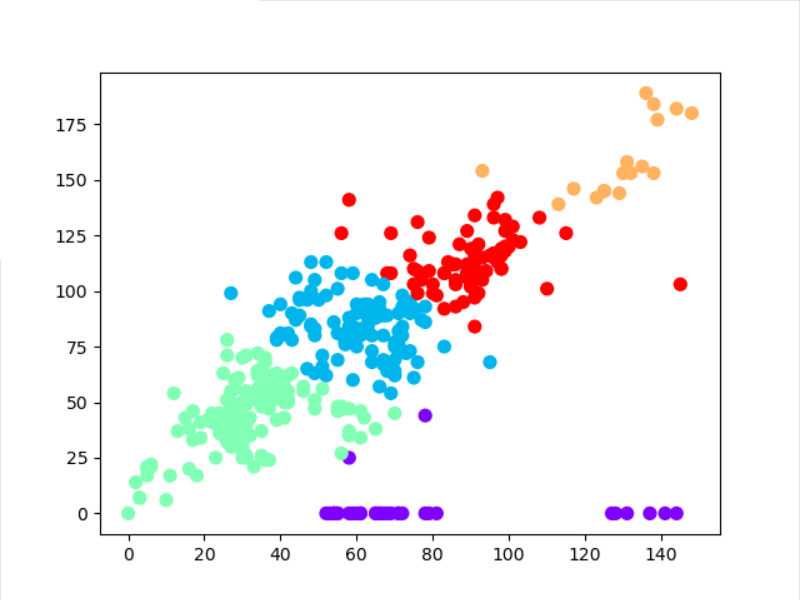
结果:可以看到实际与预测情况大致相同,可以得出结论。可以得出结论:利用天气质量的PM2.5和PM10可以预测天气的评级。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号