
Flume 架构
核心概念
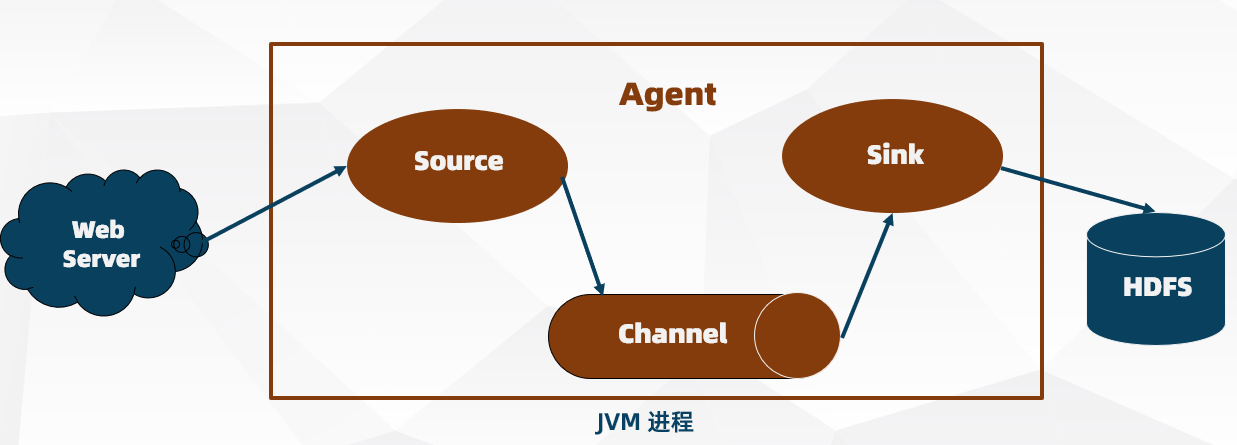
Agent
- Flume 最核心的角色就是 Agent。Flume 数据采集系统是由一个个 Agent 连接起来的数据传输通道
- 对于每个 Agent来 说就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发送到下一个目的地
Agent 内部有三个重要的组件:Source,Channel,Sink
Source(数据源)
- 从数据发生器接收数据,并将接收的数据以 Event 的形式传递给一个或多个 Channel
Flume提供多种数据接收方式,比如 Avro,Thrift 等
Channel(通道)
- Channel 是一种短暂的存储容器,它从 Source 处接收到 Event 格式数据后进行缓存,直到被消费掉。它在 Source 和 Sink 之间起到了桥梁作用,Channel 是一个完整的事务,这一点保障了数据在收发时的一致性,并且可以和任意数量的 Source 和 Sink 连接。
Channel 支持的类型有:JDBC Channel、FileSystem Channel,Memory Channel 等
Sink(接收地)
- Sink 将数据存储到集中存储器(比如 HBase 和 HDFS),它从 Channels 消费数据 (Events) 并将其传递给目标地. 目标地可能是另一个 Sink,也可能 HDFS 或 HBase
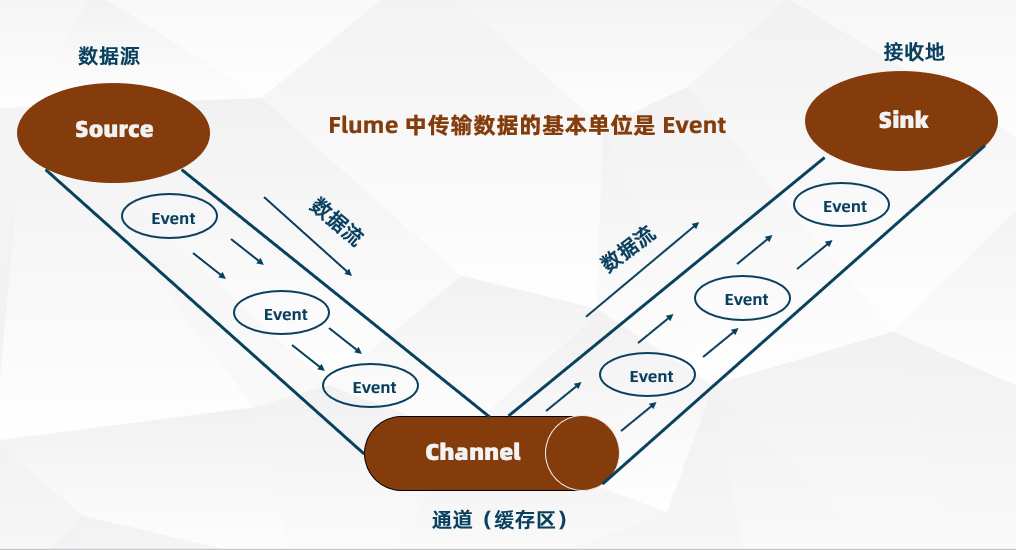
Event(事件)
-
数据在 Flume 内部是以 Event 封装的形式存在的。因此 Source 组件在获取到原始数据后,需要封装成 Event 后发送到 Channel 中,然后 Sink 从 Channel 取出 Event 后,根据配置要求再转成其他的形式进行数据输出
-
Event 封装的对象主要有两部分:Headers(Event 头)和 Body(Event 体)

- Headers:是一个 Map 集合类型(Key-Value),用于存储元数据(如标志、描述等)
- Body:就是一个字节数组,保存采集的实际数据内容
Transaction(事务)
- Flume 的事务机制(类似于数据库的事务机制)
- Flume 使用独立的事务分别从 Source 到 Channel,以及从 Channel 到 Sink 的 Event 传递
注意:在任何时刻,Event 至少在一个 Channel 是完整有效的(基于事务机制保障)
Interceptor(拦截器)
- 拦截器拦截工作在 Source 组件之后,Source 产生的 Event 会被传入的拦截器根据需要进行拦截处理
- 拦截器可以组成拦截器链
总结
通过 Flume 框架可以知道,学习 Flume 其实就是学习 Source、Channel、Sink 的组合。Flume 框架要是使用 Source、Channel、Sink 的组合,就必须是我们通过配置文件告诉框架。
学习 Flume 其实就是学习 Source + Channel + Sink 的组合配置。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现