
HBase 读写数据流程
HBase 读数据流程
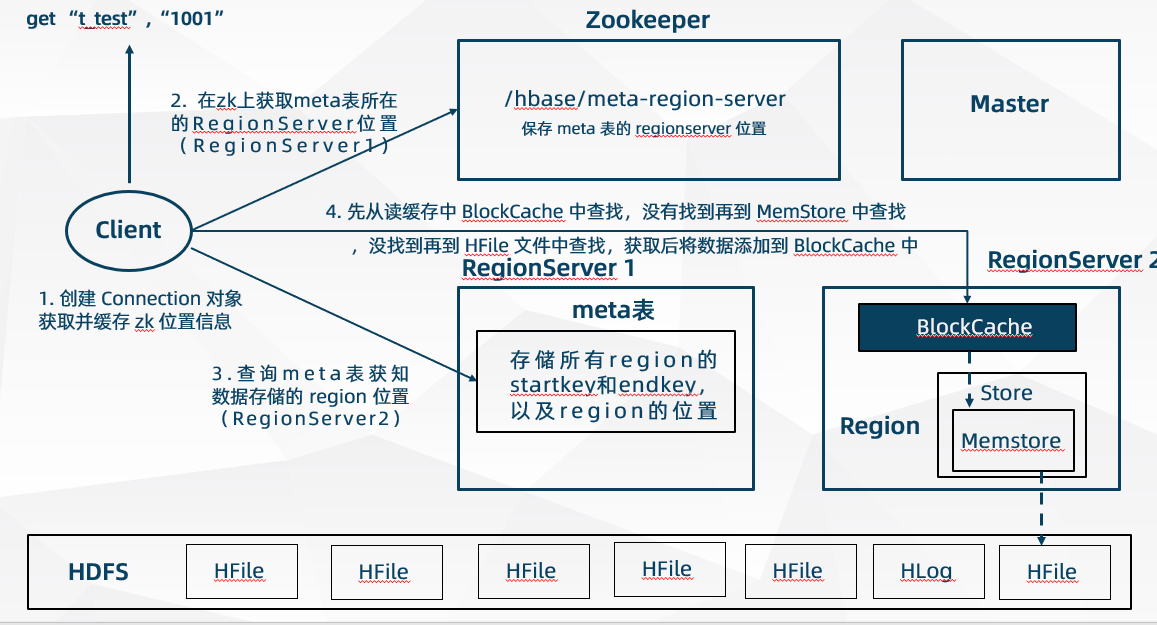
- 客户端创建 Connection 连接对象,通过加载的 hbase-site.xml 配置文件获得 zk 集群地址
- 客户端连接到 zk 集群然后去读取 zk 目录 /hbase/meta-region-server 的配置信息,找到 meta 表存放的 HRegionServer 地址
- 客户端根据 zk 返回的 HRegionServer 地址去连接该 HRegionServer 并读取里面的 meta 表(meta 表存放着 HBase 中所有 Region 的 startkey 和 endkey,以及 这些 Region 所在的各个 HRegionServer 地址)
- 客户端查询 meta 表,找到将要读取的表数据属于哪个 Region,以及归哪个 HRegionServer 负责管理
- 客户端连接该 HRegionServer,发送读取数据请求
- HRegionServer 先从读缓存 BlockCache 中查找数据,没有找到再到写缓存 MemStore 中查找,如果还没找到就到 HFile 文件中查找,获取数据一方面返回给客户端,一方面将数据添加到 BlockCache 中,如果下次查找相同数据则直接从 BlockCache 中返回即可
HBase 写数据流程
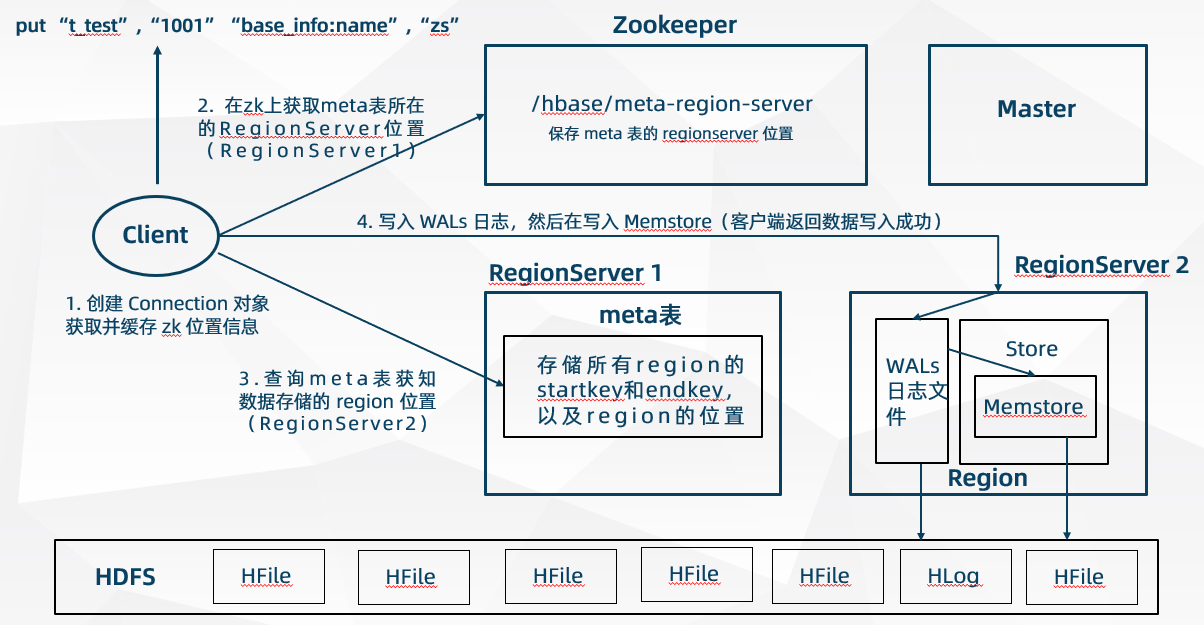
- 客户端创建 Connection 连接对象,通过加载的 hbase-site.xml 配置文件获得 zk 集群地址
- 客户端连接到 zk 集群然后去读取 zk 目录 /hbase/meta-region-server 的配置信息,找到 meta 表存放的 HRegionServer 地址
- 客户端根据 zk 返回的 HRegionServer 地址去连接该 HRegionServer 并读取里面的 meta 表(meta 表存放着 HBase 中所有 Region 的 startkey 和 endkey,以及 这些 Region 所在的各个 HRegionServer 地址)
- 客户端查询 meta 表,找到将要写入的表数据属于哪个 Region,以及归哪个 HRegionServer 负责管理
- 客户端连接该 HRegionServer
- 客户端获取行锁(HBase 中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性)
- HRegionServer 先将写入数据操作顺序写入到 WALs 日志文件中(类似于 Redis 的 AOF 文件),然后再写入 MemStore 写缓存中,这时 HRegionServer 向客户端返回写入数据成功
- 客户端释放行锁(HBase 中其他可以允许 Table 表中该行数据的写入操作)
- 当 MemStore 写缓存满足一定大小之后再一起写入磁盘中(落盘),并生成新的 HFile 格式文件
总结
- 在 HBase 的读写过程中,客户端实际上是不需要跟 HMaster 有任何交互的。这也是为什么我们在客户端的配置中,连接地址是填写的zookeeper 而不是 HMaster
- 客户端第一次访问才会到 zk 中获取 meta 表信息,然后会客户端上进行缓存,这样就不需要每次都到 zk 上去查找
- 客户端上的读请求分为 两种:Get 和 Scan,对于 HBase 服务端来说,当一个 Get 请求过来后,还是会转换为一个特殊的 Scan 请求,即 startrow 和 endrow 一致的 Scan 请求
- HBase 的写入很快,是追加多版本的形式,删除也很快,只是插入一条打上 “deteled” 标签的数据。因此,HBase 的读操作比较复杂的,需要处理各种状态和关系
posted @
2022-01-13 20:24
追こするれい的人
阅读(
136)
评论()
编辑
收藏
举报
点击右上角即可分享


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现