HBase 数据模型
HBase 数据模型
逻辑视图
HBase 逻辑视图(表结构)如下:
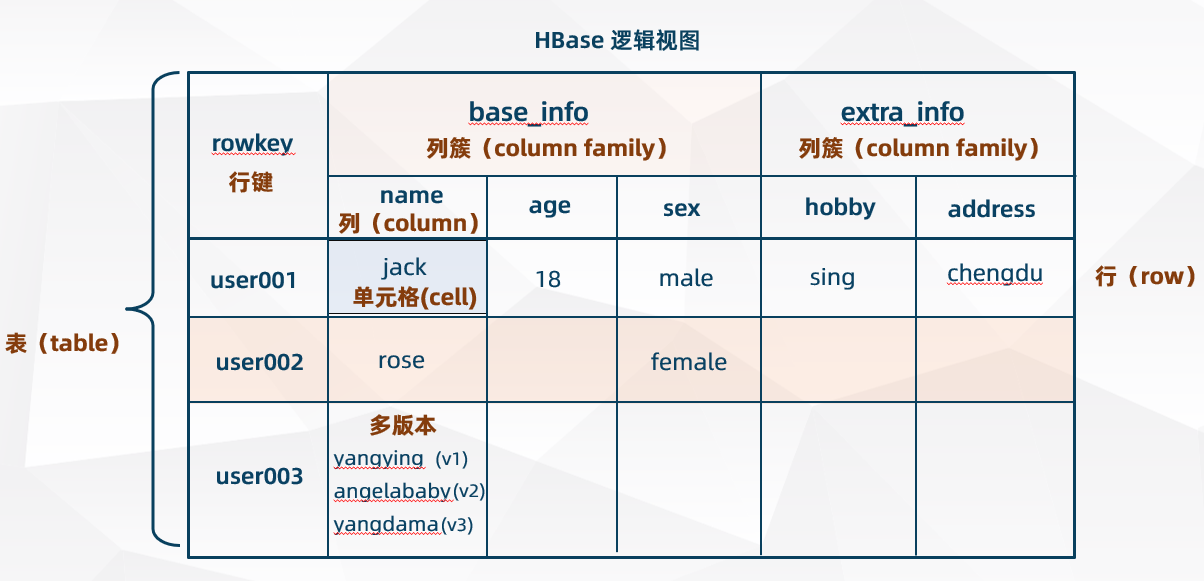
基本概念术语
-
Table(表)
HBase 一个表由多行组成
-
Row Key(行键)
HBase 中表中一行的唯一标识(类似于关系表中的主键)。一张表中所有行都按照行键(rowkey)的字典序由小到大排序。
-
Row(行)
HBase 中的行由一个行键(row key)和一个或多个列组成,这些列的值与它们相关联。
-
Column(列)
与关系型数据库中的列不同,HBase 的列由列族(column family)以及列限定符(qualifier)即列名两部分组成,两者中间使用 :(冒号)相连。
比如 base_info:name,其中 base_info 为列簇,name 为列限定符(即列名)
-
Column Family(列族)
- 表中的每一行都有相同的列族,尽管给定的行可能不会在给定的列族中存储任何东西(允许空值)
- 列族(column family)在表创建的时候需要指定,用户不能随意增减(列族是固定不变的)
- 一个列族(column family)下可以设置任意多个列,理论上甚至可以扩展到上百万列(列可以动态增加的)
列族在物理上协调一组列及其值,这通常是出于性能原因。每个列族都有一组存储属性,例如是否应该将其值缓存在内存中、如何压缩其数据或对其行键进行编码等
-
Cell(单元格)
单元格是行、列族和列限定符(即列名)的组合,包含一个值和一个时间戳(表示值的版本)
-
Timestamp(时间戳)
时间戳写在单元格每个值旁边,它是一个值的给定版本的标识符。默认情况下,时间戳表示写入数据时在 RegionServer 上的时间,但可以在将数据放入单元格时指定不同的时间戳值。
表结构特点
- HBase 的表没有固定的字段定义;
- HBase 的表中每行存储的都是一些 key-value 键值对(一个key-value 键值对叫一个 cell 单元格),并且 value 的值可以有多个版本
- HBase 的表中有列族的划分,用户可以指定将哪些 key-value 插入哪个列族
- HBase 的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中
- HBase 的表中的每一行都固定有一个行键(row key),而且每一行的行键在表中不能重复(类似于 MySQL 的主键)
- HBase 的数据,包含行键、key、value 都是 byte[ ] 类型,Hbase 不负责为用户维护任何数据类型
- HBase 对事务的支持很差
物理视图
HBase 本质是一个 Map,由 Key-Value 键值对构成,不过与普通的 Map 不同,Hbase 是一个稀疏的、分布式的、多维排序的 Map。
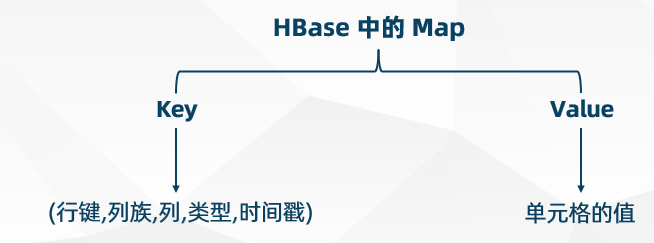
Key-Value 结构如下:
{"user001","base_info","name","put","timetamp"} -> "jack"
{"user001","base_info","age","put","timetamp"} -> "18"
{"user002","base_info","name","put","timetamp"} -> "rose"
HBase Map 特性
-
多维
这个特性比较容易理解。HBase 中的 Map 与普通 Map 最大的不同在于,Key 是一个复合数据结构,由多维元素构成,包括行键、列族、列、类型和时间戳组成的五元组
-
稀疏
稀疏性是 HBase 一个突出特点。从上面表结构可以看出,user002 这一行仅有两列(name 和 age)有值,其他列都为空值。在其他数据库中,对于空值的处理一般都会填充 null,而对于 HBase,空值不需要任何填充。这个特性为什么重要?因为 HBase 的列在理论上是允许无限扩展的,对于成百万列的表来说,通常都会存在大量的空值,如果使用填充 null 的策略,势必会造成大量空间的浪费。因此稀疏性是 HBase 的列可以无限扩展的一个重要条件,即 HBase 空值不占用任何存储空间。
-
排序
构成 HBase 的 Key-Value 在同一个文件中都是有序的,但规则并不是仅仅按照行键(row key)排序,而是按照 Key-Value 中的 Key 进行排序
排序规则如下:
- 不同行
- 按行键(row key)排序(字典排序)
- 同一行
- 先按列族(column family)排序(字典排序)
- 再按 Key 排序(字典排序)
- 最后按照时间戳排序
- 不同行
HBase 的多维元素排序规则对于提升 HBase 的查询效率性能至关重要
-
分布式
很容易理解,构成 HBase 的所有 Map 并不集中在某台机器上,而是分布在整个 HBase 集群中
HBase 数据类型
HBase 中只支持字节类型 byte[] (即 HBase 存储二进制,不维护任何数据类型)
注:此处的 byte[] 包括: 行键、键值对(key-value)、列族名、表名等
HBase 数据存储
数据存储领域比较常见的两种数据存储方式:行式存储和列式存储
-
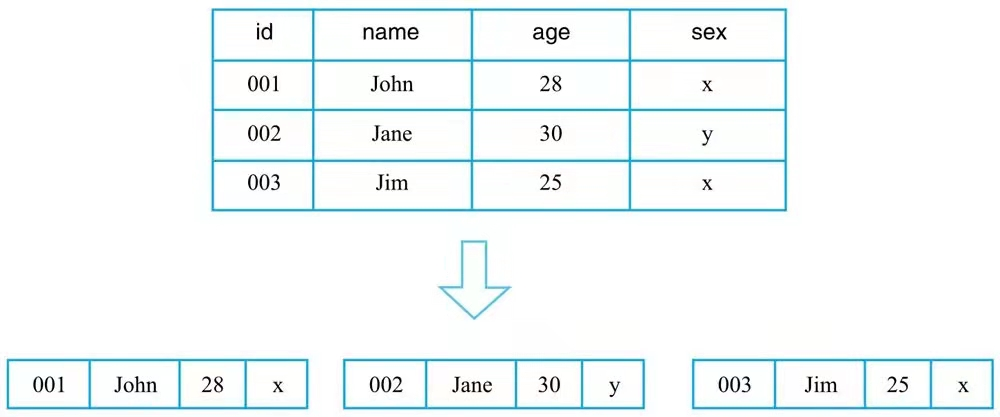
行式存储
行式存储系统会将一行数据存储在一起,一行数据写完之后再接着写下一行,最典型的如 MySQL 这类关系型数据库
![]()
特点
行式存储在获取一行数据时是很高效的,但是如果某个查询只需要读取表中指定列对应的数据,那么行式存储会先取出一行行数据,再在每一行数据中截取待查找目标列。
这种处理方式在查找过程中引入了大量无用列信息,从而导致大量内存占用。因此,这类系统仅适合于处理 OLTP(联机事务处理) 类型的负载,对于OLAP(联机分析处理) 这类分析型负载并不擅长。
-
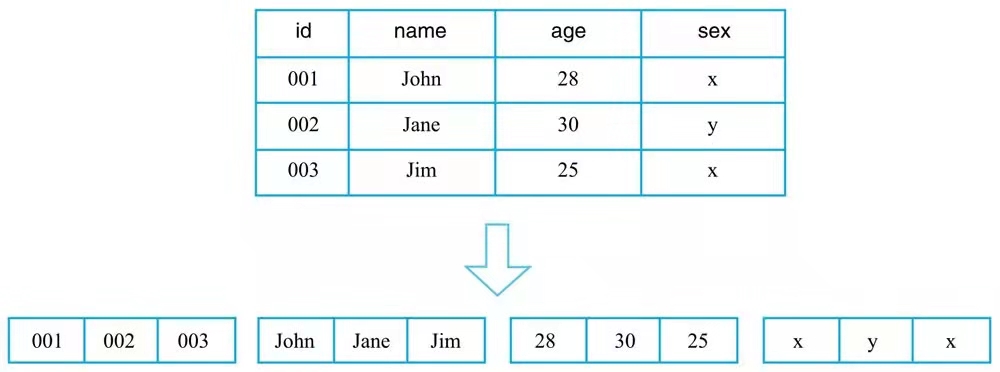
列式存储
列式存储理论上会将一列数据存储在一起,不同列的数据分别集中存储
![]()
特点
列式存储对于只查找某些列数据的请求非常高效,只需要连续读出所有待查目标列,然后遍历处理即可;
但是反过来,列式存储对于获取一行的请求就不那么高效了,需要多次 IO 读多个列数据,最终合并得到一行数据。另外,因为同一列的数据通常都具有相同的数据类型,因此列式存储具有天然的高压缩特性。
HBase 采用列簇式存储
从概念上来说,列簇式存储介于行式存储和列式存储之间,可以通过不同的设计思路在行式存储和列式存储两者之间相互切换。
比如,一张表只设置一个列簇,这个列簇包含所有用户的列。HBase 中一个列簇的数据是存储在一起的,因此这种设计模式就等同于行式存储。
比如,一张表设置大量列簇,每个列簇下仅有一列,很显然这种设计模式就等同于列式存储。
HBase 表物理存储结构
HBase 系统级别目录结构
HBase 在 HDFS 上的存储位置,根目录是由配置项hbase.rootdir决定,默认是 /hbase
-
/hbase/.tmp:当对表做创建或者删除操作时,会将表移动到该目录下,然后再去做处理操作
-
/hbase/WALs:RegionServer 在处理数据插入和删除的过程中记录操作内容的一种日志
-
/hbase/oldWALs:当 /hbase/WALs 目录中的 logs 文件没有用之后,会将这些文件移到此目录下,HMaster 会定期进行清理,相当于垃圾回收站
-
/hbase/MasterProcWAL:HMaster 记录管理操作日志
-
/hbase/archive:HBase 在做 Split 或者 Compact 操作完成之后,会将 HFile 移到 .archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
-
/hbase/corrupt:存储HBase做损坏的日志文件,一般都是为空的
-
/hbase/.snapshot:hbase若开启了 snapshot(快照)功能之后,对某一个用户表建立一个 snapshot(快照) 之后,snapshot 都存储在该目录下
-
/hbase/data:核心目录,存储 HBase 表的数据
默认情况下该目录下有两个目录
-
hbase/data/default:当在用户创建表的时候,没有指定 namespace(名称空间) 时,表就创建在此目录下
-
hbase/data/hbase:系统内部创建的表,hbase:meta; namespace
namespace(名称空间)是表的逻辑分组,类似于关系数据库系统中的数据库名
-
-
/hbase/hbase.id:存储集群唯一集群 cluster id (UUID)
-
/hbase/hbase.version:集群版本号
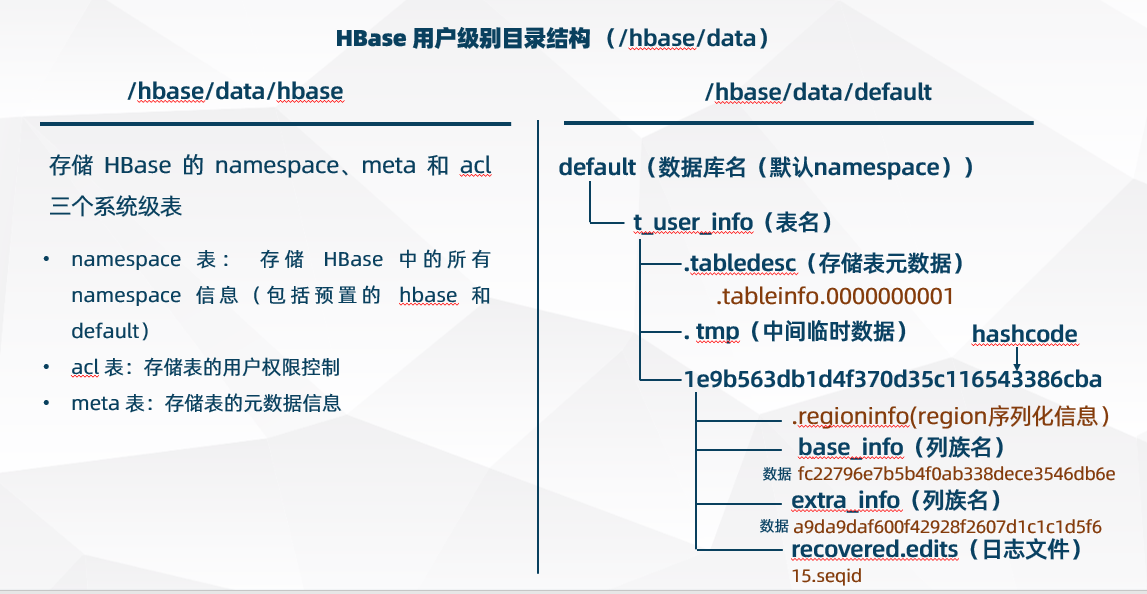
HBase 用户级别目录结构(/hbase/data)
-
/hbase/data/hbase:存储 HBase 的 namespace、meta 和 acl 三个系统级表
- namespace 表: 存储 HBase 中的所有 namespace 信息,包括预置的 hbase 和 default。
- acl 表:存储表的用户权限控制
- meta 表:存储表的元数据信息
-
/hbase/data/库名(namespace)
- /hbase/data/库名/表名/.tabledesc:存储表的元数据信息
- /hbase/data/库名/表名/.tabledesc/.tableinfo.0000000001:表的元数据信息具体文件
- /hbase/data/库名/表名/.tmp:中间临时数据,当 .tableinfo 被更新时该目录就会被用到
- /hbase/data/库名/表名/01a10fbfc443c8a91766ccea497ce4ee:是由 region 的表名+ Key + 时间戳产生的 HashCode 码
- /hbase/data/库名/表名/region名/.regioninfo:包含了对应 region 的 HRegionInfo 的序列化信息,类似 .tableinfo
- /hbase/data/库名/表名/region名/列族名:每个列族的所有实际数据文件
- /hbase/data/库名/表名/region名/列族名/文件名:HBase实际数据文件
- /hbase/data/库名/表名/region名/.tmp:存储临时文件
- /hbase/data/库名/表名/.tabledesc:存储表的元数据信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号