
MapReduce ReduceTask 并行度和分区(Partition)
ReduceTask 并行度
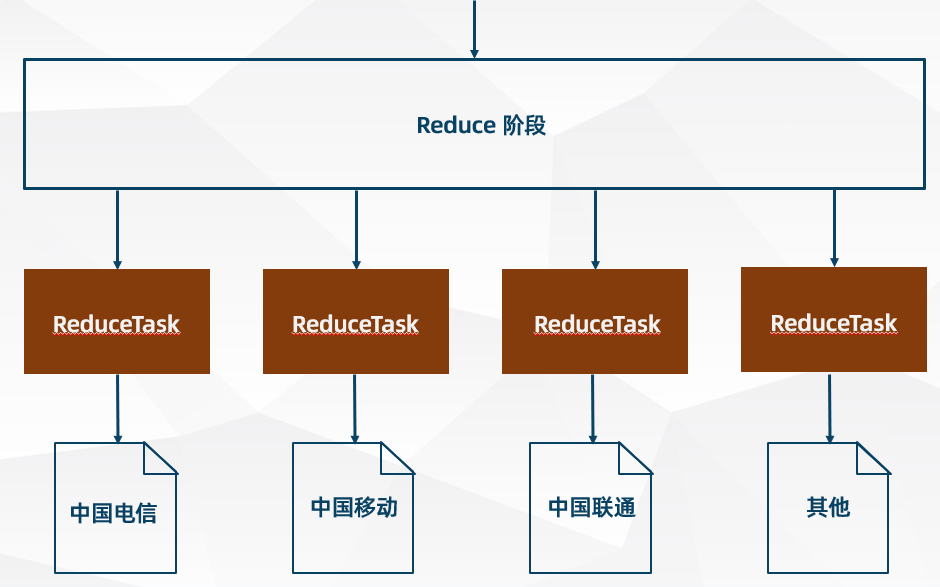
- MapTask 并行度的数量由切片数决定
- ResuceTask 并行度的数量是需要用户手动设置(如果不设置默认为 1)
- MapReduce 程序最终生成的结果文件 (part-r-xxxxx) 数量由 ReduceTask 并行度的数量决定
ReduceTask 并行度的数量设置
//设置 ReduceTask 并行度数量
job.setNumReduceTasks(4);
MapReduce 分区(Partition)
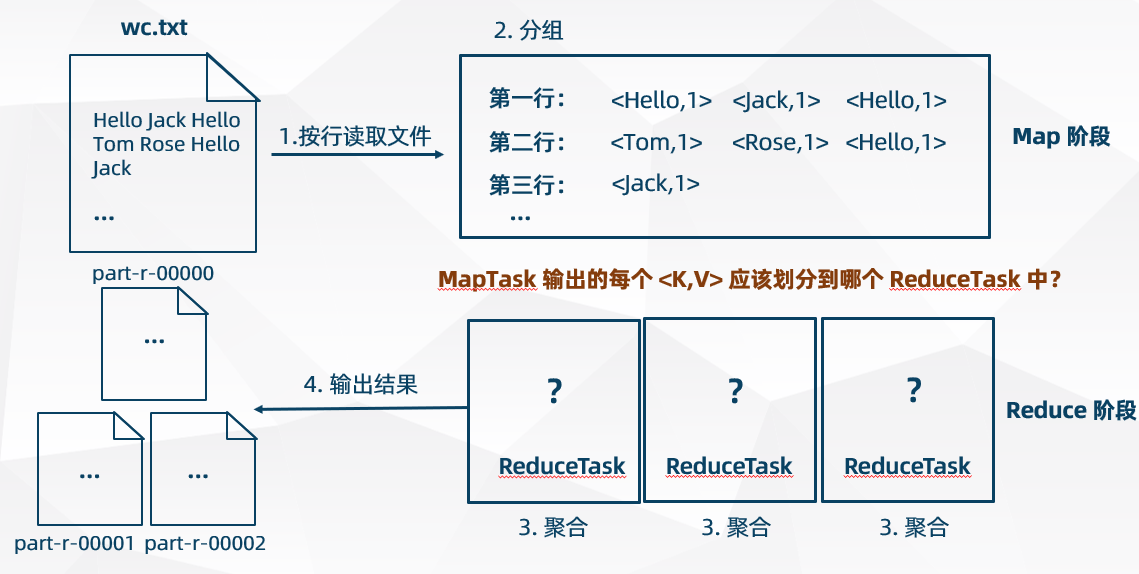
- MapReduce 程序的分区(Partition)由分区器(Partitioner)来控制
- 分区器(Partitioner)的作用是 MapTask 输出的时候确定应该划分到哪个 ReduceTask 任务中
- ReduceTask 并行度为默认数量 1 的时候,意味着只有一个 ReduceTask ,仅输出一个结果文件,这时不存在分区问题,分区器(Partitioner)也不起作用
HashPartitioner(MapReduce 默认分区器)
HashPartitioner 分区器源码解析:
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
numReduceTasks 是 ReduceTask 的并行度数量, 这段代码实现的目的很简单,就是将 key 均匀分布在 Reduce Tasks 上
自定义分区器(Partitioner)
如果 HashPartitioner(默认分区器)无法满足需求,用户可以自定义分区器,由自己编写分区规则
/**
* 自定义分区器
*/
public class MyPartitioner<K2,V2> extends Partitioner<K2,V2> {
//重写分区方法
@Override
public int getPartition(K2 key, V2 value, int numReduceTasks) {
//编写分区规则
return 0;
}
}
- 自定义分区类必须继承 Partitioner 分区父类,并重写 getPartition() 分区方法
- ReduceTask 的数量应该等于分区数,一个分区(即一个 ReduceTask 任务)输出一个文件
- 如果 ReduceTask 的数量小于分区数,则会抛出非法分区异常
- 如果 ReduceTask 的数量大于分区数,则产生空文件
Job 设置自定义分区
// 设置自定义分区(不设置默认使用 HashPartitioner)
job.setPartitionerClass(ProvincePartitioner.class);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号