MapReduce 输入&输出数据组件
MapReduce 输入数据组件
MapReduce 提供的全部输入数据组件(Map 读入文件)都继承于 FileInputFormat 抽象类
MapReduce 内置常用输入数据组件
-
TextInputFormat(默认)
TextInputFormat 读取文件得到 InputSplit,然后 LineRecordReader 通过 InputSplit 得到 Key 和 Value。Key 是当前行的偏移量,而 Value 是当前行的内容
-
NLineInputFormat
NLineInputFormat 是将 N 行文本内容作为一个切片。覆写了父类的 getSplits()。LineRecordReader 通过 InputSplit 得到 Key 和 Value。Key 是当前N行的偏移量;Value 是当前 N 行的内容
//设置输入组件为 NLineInputFormat job.setInputFormatClass(NLineInputFormat. class); //配置 N 行数据为一个切片 <Key ,Value> NLineInputFormat.setNumLinesPerSplit(job, 2); -
KeyValueTextInputFormat
KeyValueTextInputFormat 的切片算法使用的是父类 FileInputFormat 的。使用 KeyValueLineRecordReader 获取数据的 Key 和 Value。
用于纯文本文件的 InputFormat。文件被分成几行。换行或回车都可用来表示行结束。每一行通过分隔符字节划分为键和值部分。如果不存在这样的字节,键将是整个行,值将为空。分隔符字节可以在配置文件中的属性名称
configuration conf = job.getConfiguration(); //默认是制表符(\t) conf.set("mapreduce.input.keyvaluelinerec ordreader.key.value.separator",","); job.setInputFormatClass(KeyValueTextInputFormat.class); -
CombineTextInputFormat
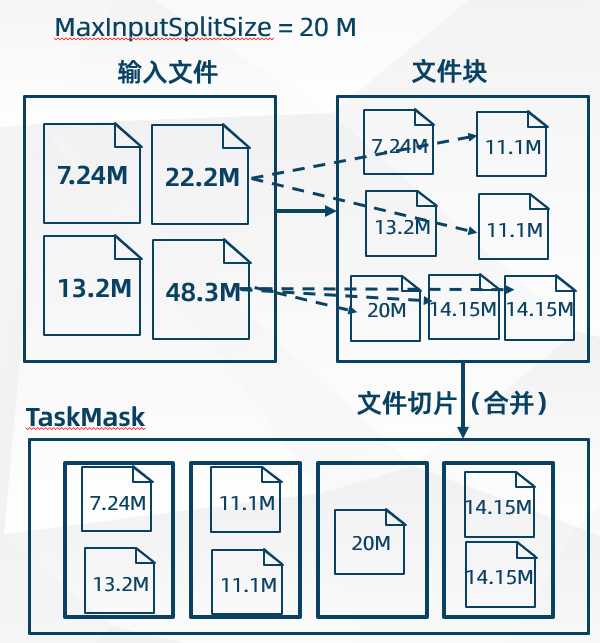
框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask,这样如果有大量小文件,就会产生大量的 MapTask,处理效率极其低下。
如果有小文件存在,可以使用 CombineTextInputFormat。CombineTextInputFormat 通过设置 MaxInputSplitSize
可以控制 split 的数量,也就是可以将多个小文件做成一个 split,减少 MapTask 的数量。![]()
切片规则:
-
文件大小与 MaxInputSplitSize 进行比较
-
文件大小 < MaxInputSplitSize,单独成为一个文件块
-
2 * MaxInputSplitSize > 文件大小 > MaxInputSplitSize,文件平均切分为两个文件块
-
文件大小 > 2 * MaxInputSplitSize,先按照 MaxInputSplitSize 划分一个文件块,剩余部分按照之前规则划分
-
最终将划分的文件块合并为文件切片,一个文件切片则对应一个 MapTask 任务
//设置输入数据组件 job.setInputFormatClass(CombineTextInputFormat.class); //设置 MaxInputSplitSize 4M CombineTextInputFormat.setMaxInputSplitSize(job,4 * 1024 * 1024); -
以上输入数据组件都是按行读取数据,每一行会形成一个 <K,V> 对,调用一次 map() 方法
自定义输入数据组件
自定义输入数据组件,需要继承 FileInputFormat 抽象类并重写 RecordReader() 方法(实现具体自定义读的逻辑)
MapReduce 输出数据组件
MapReduce 提供的全部输出数据组件(Reduce 写出文件)都继承于 FileoutputFormat 抽象类
MapReduce 内置常用输出数据组件
-
TextOutputFormat
Reducer 的结果直接以字符串格式按行写出到文件中
-
SequenceFileOutputFormat
Reducer 的结果按照 KV 键值对格式写出的序列化文件
SequenceFileOutputFormat 中写入的是 Reducer 输出的 KV 键值对且进行了序列化,因此更方便进行压缩;此外,一个 MR 流程得到的结果如果是 SequenceFileOutputFormat 格式写出,那么该结果能够很便利地作为下一个 MR 流程的输入,因为已经序列化封装好了 KV 键值对,作为输入时只需要进行反序列化读入即可
自定义输出数据组件
自定义输出数据组件,需要继承 FileOutputFormat 抽象类并重写 RecordWriter() 方法(实现具体自定义写的逻辑)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号