
HDFS 联邦(Federation)
HDFS HA 的不足
虽然 HDFS HA 解决了“ NameNode 单点故障 ”问题,但是在系统扩展性、整体性能和隔离性方面仍然存在问题。
-
系统扩展性方面
元数据存储在 NameNode 内存中,受内存上限的制约
-
整体性能方面
吞吐量受单个 NameNode 的影响
-
隔离性方面
一个程序可能会影响其他运行的程序,如一个程序消耗过多资源导致其他程序无法顺利运行
HDFS HA 本质上还是单名称节点
HDFS 联邦模式
-
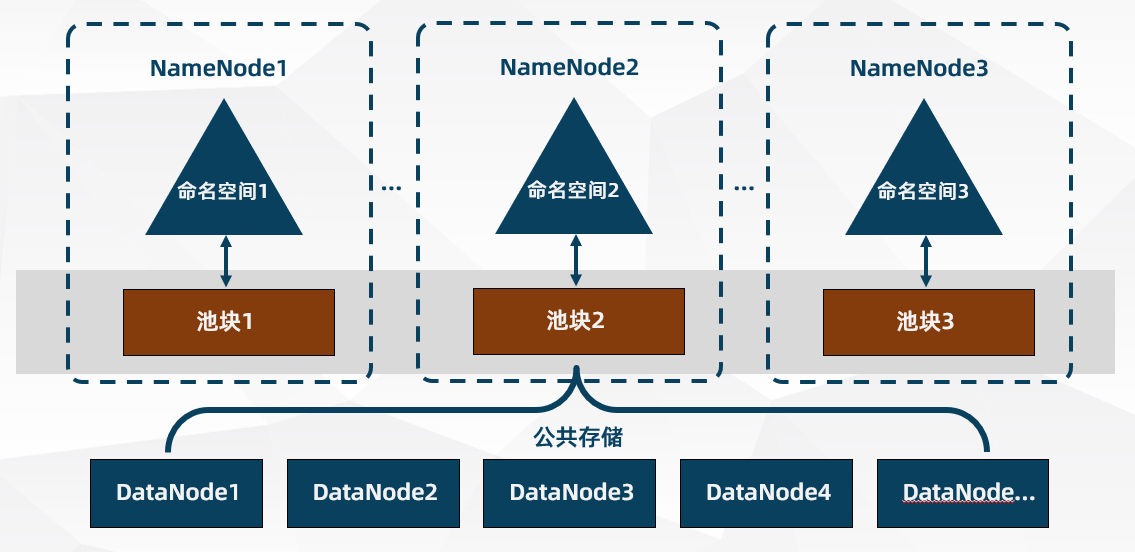
在 HDFS 联邦中,设计了多个相互独立的 NameNode,把元数据的存储和管理分散到多个节点中,使得 HDFS 的命名服务能够通过增加服务器来水平扩展。这样把单个 NameNode 的负载分散到多个节点中,在 HDFS 数据规模较大的时候不会也降低 HDFS 的性能。
-
多个 NameNode 分别进行各自命名空间和元数据的管理,不需要彼此协调,无法相互访问。每个 DataNode 要向集群中所有的 NameNode 注册,并周期性的发送心跳信息和文件数据块信息,报告自己的状态。
-
HDFS 联邦拥有多个独立的命名空间,其中,每一个命名空间管理属于自己的一组块,这些属于同一个命名空间的块组成一个“块池”。每个 DataNode 会为多个块池提供块的存储,块池中的各个块实际上是存储在不同 DataNode 中的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现