
HDFS 高可用(HA)故障转移工作机制
HDFS 高可用(HA)故障转移工作机制
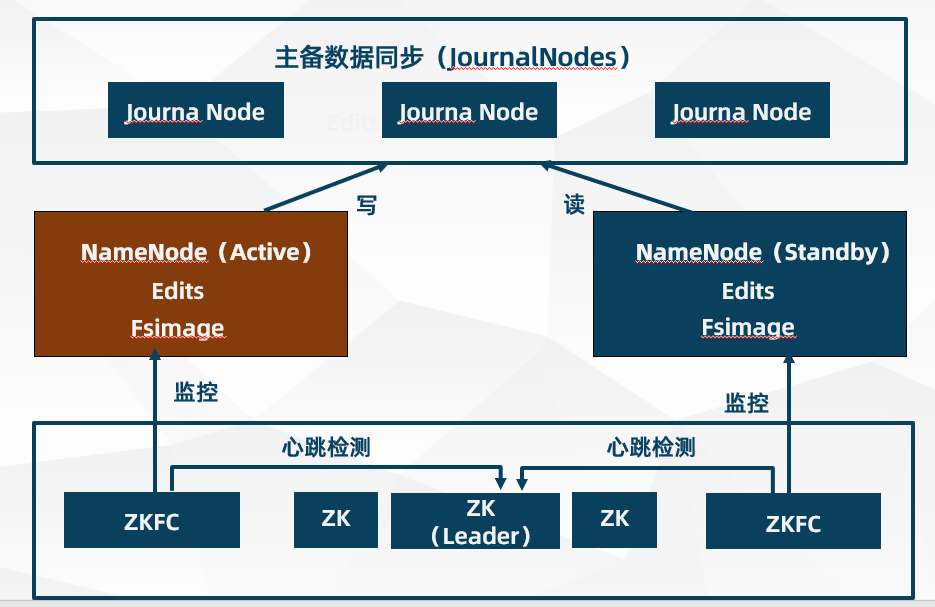
自动故障转移为 HDFS 部署增加了两个新组件:ZooKeeper(ZK) 和 ZKFailoverController(ZKFC)进程
ZooKeeper(ZK)进程
ZooKeeper 是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA 的自动故障转移依赖于 ZooKeeper 的以下功能:
故障检测
集群中的每个 NameNode 在 ZooKeeper 中维护了一个会话,如果机器崩溃,ZooKeeper 中的会话将终止,ZooKeeper 通知另一个 NameNode 需要触发故障转移
现役 NameNode 选择
ZooKeeper 提供了一个简单的机制用于唯一的选择一个节点为 active 状态。如果目前现役 NameNode 崩溃,另一个节点可能从 ZooKeeper 获得特殊的排外锁以表明它应该成为现役 NameNode。
ZKFailoverController(ZKFC)进程
ZKFC 是自动故障转移中的另一个新组件,是 ZooKeeper 的客户端,也监视和管理 NameNode 的状态。每个运行NameNode 的主机也运行了一个 ZKFC 进程,ZKFC 负责:
健康监测
ZKFC 使用一个健康检查命令定期地 ping 与之在相同主机的 NameNode,只要该 NameNode 及时地回复健康状态,ZKFC 认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
ZooKeeper 会话管理
当本地 NameNode 是健康的,ZKFC 保持一个在 ZooKeeper 中打开的会话。如果本地 NameNode 处于 active 状态,ZKFC 也保持一个特殊的 znode 锁,该锁使用了 ZooKeeper 对短暂节点的支持,如果会话终止,锁节点将自动删除。
基于 ZooKeeper 的选择
如果本地 NameNode 是健康的,且 ZKFC 发现没有其它的节点当前持有 znode 锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地 NameNode 为 Active。
HDFS 脑裂问题(brain split)
在实际中,NameNode 可能会出现这种情况,NameNode 在垃圾回收(GC)时,可能会在长时间内整个系统无响应,因此,也就无法向 zk 写入心跳信息,这样的话可能会导致临时节点掉线(假死),备 NameNode 会切换到 Active 状态,这种情况,可能会导致整个集群会有同时有两个 NameNode,这就是脑裂问题
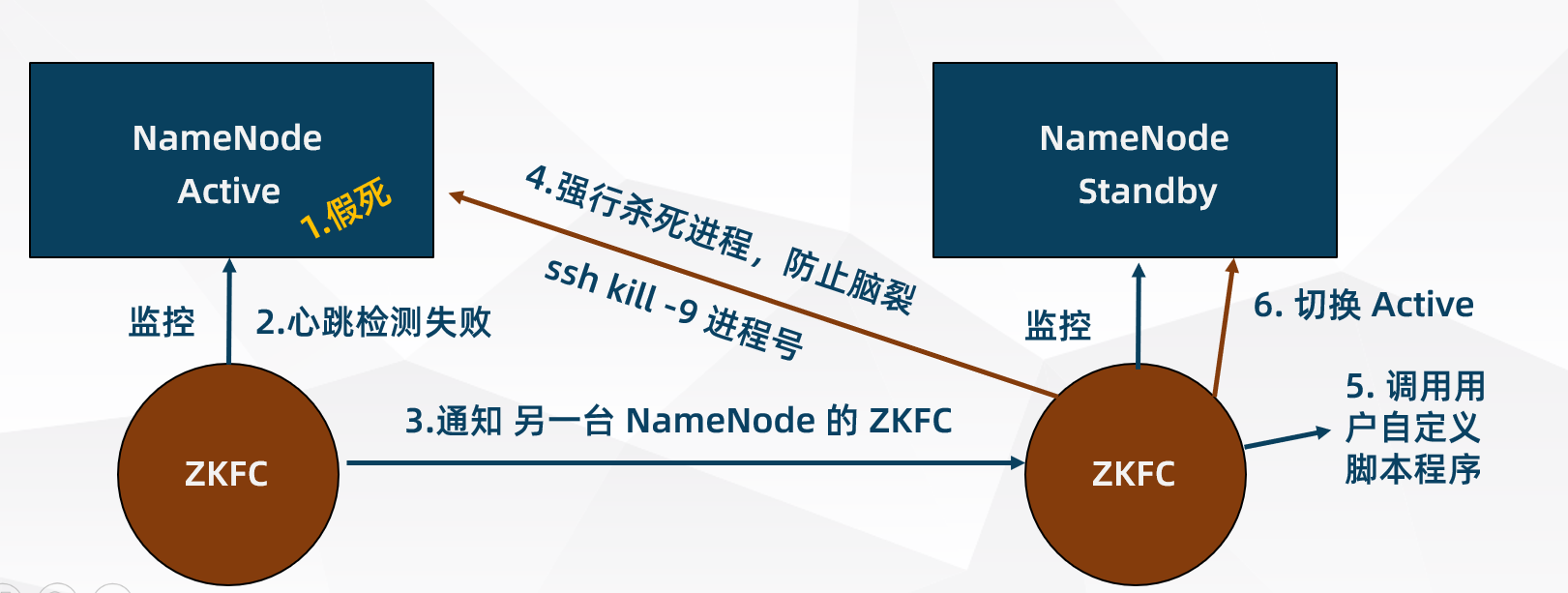
Hadoop 目前主要提供两种隔离措施(推荐第一种)
- sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死
- shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现