
Redis 数据结构
Redis 数据结构
Redis 多数据库
-
Redis 服务器拥有16 个数据库(0~15),默认使用 0 号数据库,可以使用 select 命令来切换数据库
注:16 个数据库之间是完成独立的,可以保存相同的键值对
-
清空当前数据库的数据,可以使用 flushdb 命令
-
清空 Redis 所有数据库的数据 ,可以使用flushall 命令
-
Redis不支持自定义数据库名字,默认是: 0、1、2、3、4 ... 15
-
Redis不支持为每个数据库设置不同的访问密码(默认密码为空)
Redis 基本操作命令
注:Redis 的 key 只能是字符串类型
-
set:插入数据
-
get:查询数据
-
set:修改数据
-
del:删除数据
Redis 通用操作命令
-
keys:查询所有 key
格式是keys pattern, pattern支持glob风格通配符格式:
?匹配一个字符
*匹配任意字符[]匹配中括号内的任一字符,可以用 - 来表示范围\x 匹配字符x,用于转义符号
-
exists: 判断键值是否存在
-
type: 获取键值的数据类型
-
rename:改名
-
renamenx: 改名(newKey不存在)
Redis核心对象
在Redis中有一个「核心的对象」叫做redisObject ,是用来表示所有的key和value的,用redisObject结构体来表示String、Hash、List、Set、ZSet五种数据类型。
redisObject的源代码在redis.h中,使用c语言写的,感兴趣的可以自行查看,关于redisObject我这里画了一张图,表示redisObject的结构如下所示:
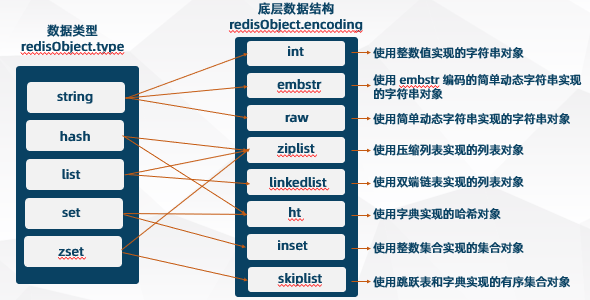
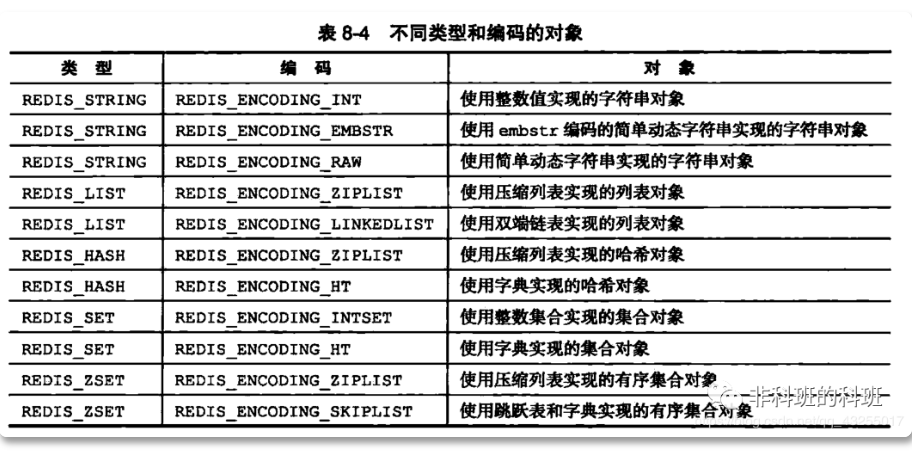
在redisObject中「type表示属于哪种数据类型,encoding表示该数据的存储方式」,也就是底层的实现的该数据类型的数据结构。
127.0.0.1:6379> set k1 234
OK
127.0.0.1:6379> set k2 3.200
OK
127.0.0.1:6379> type k1 #查看数据类型
string
127.0.0.1:6379> type k2
string
127.0.0.1:6379> object encoding k1 #查看底层存储的数据结构
"int"
127.0.0.1:6379> object encoding k2
"embstr"
Redis 数据库支持五种数据类型:
- strings(字符串)
- list(字符串列表)
- set(字符串集合)
- zset(有序字符串集合)
- hash(哈希)
key 命名注意事项:
- key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率;
- key也不要太短,太短的话,key的可读性会降低;
- 在一个项目中,key最好使用统一的命名模式,例如user:10000:passwd
Strings (字符串)
strings 类型是一个很基础的数据类型,也是任何存储系统都必备的数据类型,它可以存储二进制数据(最大存储 512 M)
127.0.0.1:6379> set mystr "hello,world!"
OK
127.0.0.1:6379> get mystr
"hello,world!"
127.0.0.1:6379> append mystr hahah #尾部追加
(integer) 17
127.0.0.1:6379> mset k1 11 k2 22 k3 33 #同时设置多个键的值
OK
127.0.0.1:6379> mget k1 k2 k3 #同时获取多个键的值
127.0.0.1:6379> set mynum "2"
OK
127.0.0.1:6379> get mynum
"2"
127.0.0.1:6379> incr mynum #递增
(integer) 3
127.0.0.1:6379> get mynum
"3"
127.0.0.1:6379> decr mynum #递减
(integer) 3
127.0.0.1:6379> get mynum
"2"
127.0.0.1:6379> incrby num 3 #递增(增量值)
(integer) 4
127.0.0.1:6379> decrby num 3 #递减(增量值)
(integer) 1
127.0.0.1:6379> incrbyfloat num 3.3 #递增/减(浮点数)
"7.3"
-
在遇到数值操作时,redis 会将字符串类型转换成数值
-
由于 INCR 等指令本身就具有原子操作的特性,所以我们完全可以利用 redis 的INCR、INCRBY、DECR、DECRBY 等指令来实现原子计数的效果
Hash(哈希)
hashes 存的是字符串和字符串值之间的映射
127.0.0.1:6379> hmset user name antirez password P1pp0 age 34 #建立哈希,并赋值
OK
127.0.0.1:6379> hgetall user #列出哈希的内容
1) "username"
2) "antirez"
3) "password"
4) "P1pp0"
5) "age"
6) "34"
127.0.0.1:6379> hset user password 12345 #更改哈希中的某一个值
(integer) 0
127.0.0.1:6379> hkeys user #获取所有field值
1) "id"
2) "name"
3) "age"
4) "gender"
127.0.0.1:6379> hvals user #获取所有value值
1) "2"
2) "wu"
3) "23"
4) "male"
127.0.0.1:6379> hget user name #获取某个field的value值
"wu"
127.0.0.1:6379> hmget user age gender ##获取多个field的value值
1) "23"
2) "male"
127.0.0.1:6379> hdel user name #删除某个field
(integer) 1
127.0.0.1:6379> hlen user #查询hash长度
(integer) 3
127.0.0.1:6379> hincrby user id 1 #field的value值自增
(integer) 12
List (字符串列表)
redis 中的 lists 在底层实现上并不是数组而是链表,也就是说对于一个具有上百万个元素的 lists 来说,在头部和尾部插入一个新元素,其时间复杂度是常数级别的。虽然 lists 有这样的优势,但同样有其弊端,那就是,链表型 lists 的元素查询会比较慢,而数组查询就会快得多。
127.0.0.1:6379> lpush mylist "1" #新建一个list并列表头部插入元素
(integer) 1 #返回当前mylist中的元素个数
127.0.0.1:6379> rpush mylist "2" #在mylist头部插入元素
(integer) 2
127.0.0.1:6379> lpush mylist "0" #在mylist尾部插入元素
(integer) 3
127.0.0.1:6379> lrange mylist 0 1 #列出mylist中从编号0到编号1的元素
1) "0"
2) "1"
127.0.0.1:6379> lrange mylist 0 -1 #列出mylist中从编号0到倒数第一个元素
1) "0"
2) "1"
3) "2"
127.0.0.1:6379> lindex mylist 0 #获取指定索引的值
"1"
127.0.0.1:6379> lset mylist 0 11 #设置指定位置索引的值
OK
127.0.0.1:6379> lpop mylist #头部弹出值
"1"
127.0.0.1:6379> rpop mylist #尾部弹出值
"2"
127.0.0.1:6379> llen mylist #获取list中元素个数
(integer) 1
127.0.0.1:6379> lrem mylist 2 2 #删除list中的元素(参数1:0表示删除所有值 参数2:list中指定的值)
(integer) 0
127.0.0.1:6379> linsert mylist before 1 111 #在指定位置before/end插入元素
(integer) 3
Set(字符串集合)
Redis 的集合是一种无序的集合,集合中的元素没有先后顺序。
127.0.0.1:6379> sadd myset "one" #向集合myset中加入一个新元素"one"
(integer) 1
127.0.0.1:6379> smembers myset #列出集合myset中的所有元素
1) "one"
127.0.0.1:6379> sismember myset "one" #判断元素1是否在集合myset中,返回1表示存在
(integer) 1
127.0.0.1:6379> sadd yourset "1" "2"#新建一个新的集合yourset(可以添加多个元素)
(integer) 1
127.0.0.1:6379> sunion myset yourset #对两个集合求并集
1) "1"
2) "one"
127.0.0.1:6379> srem myset v1 #删除集合元素
(integer) 1
127.0.0.1:6379> scard myset #获取集合元素个数
(integer) 7
127.0.0.1:6379> srandmember myset 2 #随机获取指定个数的集合元素(负数有重复)
1) "5"
2) "1"
127.0.0.1:6379> spop myset 2 #从头部开始弹出指定集合个数
1) "3"
2) "4"
ZSet(有序字符串集合)
redis 不但提供了无序集合(sets),还很体贴的提供了有序集合(sorted sets)。有序集合中的每个元素都关联一个序号(score),这便是排序的依据。
127.0.0.1:6379> zadd myzset 1 baidu.com #新增一个有序集合并加入一个元素 baidu.com,给它赋予的序号是1
(integer) 1
127.0.0.1:6379> zadd myzset 3 360.com #向myzset中新增一个元素360.com,赋予它的序号是3
(integer) 1
127.0.0.1:6379> zadd myzset 2 google.com #向myzset中新增一个元素google.com,赋予它的序号是2
(integer) 1
127.0.0.1:6379> zrange myzset 0 -1 with scores #列出myzset的所有元素,同时列出其序号(有序)
1) "baidu.com"
2) "1"
3) "google.com"
4) "2"
5) "360.com"
6) "3"
127.0.0.1:6379> zrange myzset 0 -1 #只列出myzset的元素
1) "baidu.com"
2) "google.com"
3) "360.com"
ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。
skiplist(跳跃表)
跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。
skiplist有如下几个特点:
- 有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
- 每一层都是一个有序链表,至少包含两个节点,头节点和尾节点。
- 每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
- 如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
具体实现的结构图如下所示:
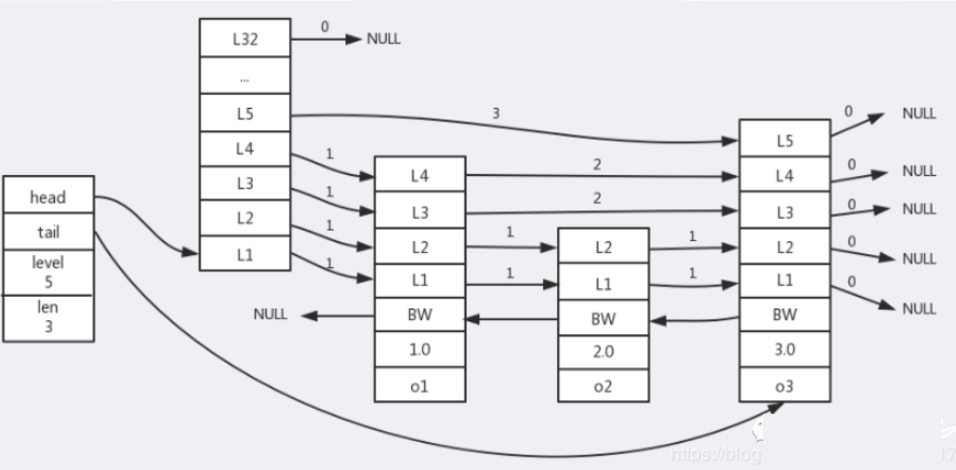
在跳跃表的结构中有 head 和 tail 表示指向头节点和尾节点的指针,能快速的实现定位。level 表示层数,len 表示跳跃表的长度,BW 表示后退指针,在从尾向前遍历的时候使用。
BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。
跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。
跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。
跳跃表的本质就是建立多级索引,以提高查询效率


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现