数据结构与算法——冒泡排序及其各种优化变形详解
版权声明:本文为Heriam博主原创文章,遵循CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://jiang-hao.com/articles/2020/algorithms-algorithms-bubble-sort.html
定义
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
算法原理
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
算法复杂度是 O(n^2),空间复杂度是常数 O(1)。但可以记录一个不需要交换的位置,把最好情况的时间复杂度降到 O(n)。详细可以参考下文优化部分的实现。
算法实现
public static int[] bubble_sort_original(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int count = 0, swap_count = 0;
for (int i = 0; i < arr.length-1; i++) {
for (int j = 0; j < arr.length-1-i; j++) {
count++;
if (arr[j] > arr[j+1]) {
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
swap_count++;
}
}
}
System.out.println("bubble_sort_original: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr)); //打印运行次数、交换次数,以及排序检验
return arr;
}
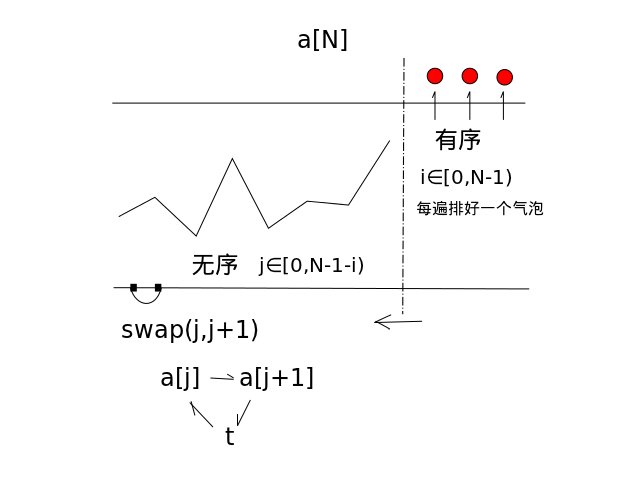
助记码
i∈[0,N-1) //循环N-1遍
j∈[0,N-1-i) //每遍循环要处理的无序部分
swap(j,j+1) //两两排序(升序/降序)
算法优化
优化1:一轮遍历未发生交换可提前结束
数据的顺序排好之后,冒泡算法仍然会继续进行下一轮的比较,直到arr.length-1次,后面的比较没有意义的。
设置标志位flag,如果发生了交换flag设置为true;如果没有交换就设置为false。
这样当一轮比较结束后如果flag仍为false,即:这一轮没有发生交换,说明数据的顺序已经排好,没有必要继续进行下去。
public static int[] bubble_sort_quit_if_sorted(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int tmp;
int count = 0, swap_count = 0;
for (int i = 0; i < arr.length-1; i++) {
boolean head_sorted = true;
for (int j = 0; j < arr.length-1-i; j++) {
count++;
if (arr[j] > arr[j+1]) {
tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
head_sorted = false;
swap_count++;
}
}
if (head_sorted) break;
}
System.out.println("bubble_sort_quit_if_sorted: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr));
return arr;
}
优化2:记录上一轮最后一次交换的位置
在传统的实现中有序区的长度和排序的轮数是相等的。比如第一轮排序过后的有序区长度是1,第二轮排序过后的有序区长度是2 ......实际上,数列真正的有序区可能会大于这个长度,比如有可能在第二轮,后面5个元素实际都已经属于有序区。因此后面的许多次元素比较是没有意义的。
我们可以在每一轮排序的最后,记录下最后一次元素交换的位置,那个位置也就是无序数列的边界,再往后就是有序区了。
public static int[] bubble_sort_mark_last_swap(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int count = 0, swap_count = 0;
int sorted_border = arr.length;
int tmp;
while (sorted_border > 1) {
int last_swap = 0;
for (int i = 0; i < sorted_border -1; i++) {
count++;
if (arr[i] > arr[i+1]) {
tmp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = tmp;
last_swap = i+1;
swap_count++;
}
}
sorted_border = last_swap;
}
System.out.println("bubble_sort_mark_last_swap: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr));
return arr;
}
上述代码中维护了一个已排好序的序列:[sorted_border,N)(N是数组大小),每次冒泡会记录最大的那个泡泡的位置作为sorted_border。 直到sorted_border == 1时,说明整个序列已经排好。
因为冒泡排序中每次冒泡都相当于选最大值放到序列结尾,所以[sorted_border,N)不仅是有序的,而且位置是正确的。 所以sorted_border == 1时,[1,N)已经获得了正确的位置,那么元素0的位置自然就确定了(它已经没得选了)。
优化3:鸡尾酒排序(双向冒泡排序)
鸡尾酒排序也就是“定向冒泡排序”、“双向冒泡排序”和“改进冒泡排序”, 鸡尾酒搅拌排序, 搅拌排序 (也可以视作选择排序的一种变形), 涟漪排序, 来回排序 or 快乐小时排序, 是冒泡排序的一种变形。此算法与冒泡排序的不同处在于排序时是以双向在序列中进行排序。算法先找到最小的数字,把他放到第一位,然后找到最大的数字放到最后一位。然后再找到第二小的数字放到第二位,再找到第二大的数字放到倒数第二位。以此类推,直到完成排序。
(1)时间复杂度:鸡尾酒排序的效率还是很低的,两层循环,时间复杂度为 O(n^2) 。
(2)空间复杂度:由于只需要几个临时变量,所以空间复杂度为 O(1) 。
那么何以见得鸡尾酒排序比冒泡排序好一点呢?
考虑这样的一个序列:(2,3,4,5,1) 。如果使用鸡尾酒排序,一个来回就可以搞定;而冒泡排序则需要跑四趟。
其根本原因在于冒泡是单向的,如果从左向右冒泡,对于小数靠后就会很不利(一趟只能挪一个位置,那就需要多次循环。这种数又被称之为乌龟);相应的,如果从右向左冒泡,对于大数靠前又会很不利(靠前的一只大乌龟)。鸡尾酒排序的优点就在于这里,由于在序列中左右摇摆(为此鸡尾酒排序又称之为 shaker sort),两种较差的局面就能得到规避,以此在性能上带来一些提升。
public static int[] cocktail_sort_original(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int i, tmp, left=0, right=arr.length-1;
int count = 0, swap_count = 0;
while (left < right) {
for (i=left; i < right; i++) {
count++;
if(arr[i] > arr[i+1]) {
tmp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = tmp;
swap_count++;
}
}
right--;
for (i=right; i > left; i--) {
count++;
if(arr[i-1] > arr[i]) {
tmp = arr[i];
arr[i] = arr[i-1];
arr[i-1] = tmp;
swap_count++;
}
}
left++;
}
System.out.println("cocktail_sort_original: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr));
return arr;
}
对于鸡尾酒排序,算法的时间复杂度与空间复杂度并没有改进。不同的是排序的交换次数。某些情况下鸡尾酒排序比普通冒泡排序的交换次数少。总体上,鸡尾酒排序可以获得比冒泡排序稍好的性能。但是完全逆序时,鸡尾酒排序与冒泡排序的效率都非常差。
优化4:一轮遍历未发生交换可提前结束的双向冒泡排序
public static int[] cocktail_sort_quit_if_sorted(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int i, tmp, left=0, right=arr.length-1;
int count = 0, swap_count = 0;
while (left < right) {
boolean middle_sorted = true;
for (i=left; i < right; i++) {
count++;
if(arr[i] > arr[i+1]) {
tmp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = tmp;
middle_sorted = false;
swap_count++;
}
}
if (middle_sorted) break;
right--;
for (i=right; i > left; i--) {
count++;
if(arr[i-1] > arr[i]) {
tmp = arr[i];
arr[i] = arr[i-1];
arr[i-1] = tmp;
swap_count++;
}
}
left++;
}
System.out.println("cocktail_sort_quit_if_sorted: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr));
return arr;
}
优化5:记录上一轮最后一次交换的位置的双向冒泡排序
public static int[] cocktail_sort_mark_last_swap(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
int i, tmp, left=0, right=arr.length-1;
int count = 0, swap_count = 0, last_swap = left;
while (left < right) {
for (i=left; i < right; i++) {
count++;
if(arr[i] > arr[i+1]) {
tmp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = tmp;
last_swap = i+1;
swap_count++;
}
}
right = last_swap;
for (i=right; i > left; i--) {
count++;
if(arr[i-1] > arr[i]) {
tmp = arr[i];
arr[i] = arr[i-1];
arr[i-1] = tmp;
last_swap = i-1;
swap_count++;
}
}
left = last_swap;
}
System.out.println("cocktail_sort_mark_last_swap: run " + count + ", swap " + swap_count + ", isSorted: " + isSorted(arr));
return arr;
}
两个方向都同时跳着走,是目前可以想到的效果最好的优化。
优化性能测试
通过运行力扣测试数据集https://leetcode-cn.com/submissions/detail/114474973/testcase/,得到各个变形的结果如下:
bubble_sort_original: run 1249975000, swap 622443661, isSorted: true
bubble_sort_quit_if_sorted: run 1249928029, swap 622443661, isSorted: true
bubble_sort_mark_last_swap: run 1249543883, swap 622443661, isSorted: true
cocktail_sort_original: run 1249975000, swap 622443661, isSorted: true
cocktail_sort_quit_if_sorted: run 934706395, swap 622443661, isSorted: true
cocktail_sort_mark_last_swap: run 828009788, swap 622443661, isSorted: true
优化5所进行的运算量最少。大多数运算都有效进行了元素交换(排序),而排除了大量无效的循环比较。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号