
myrocks复制中断问题排查
背景
mysql可以支持多种不同的存储引擎,innodb由于其高效的读写性能,并且支持事务特性,使得它成为mysql存储引擎的代名词,使用非常广泛。随着SSD逐渐普及,硬件存储成本越来越高,面向写优化的rocksdb引擎逐渐流行起来,我们也是看中了rocksdb引擎在写放大和空间放大的优势,将其引入到mysql体系。两种引擎的结构B-Tree(innodb引擎)和LSM-Tree(rocksdb引擎)很好地形成互补,我们可以根据业务类型来选择合适的存储。一般mysql默认是mysql+innodb引擎,而mysql+rocksdb引擎称之为myrocks。今天要讨论的就是myrocks复制中断问题,案例来源于真实的业务场景。
问题现象
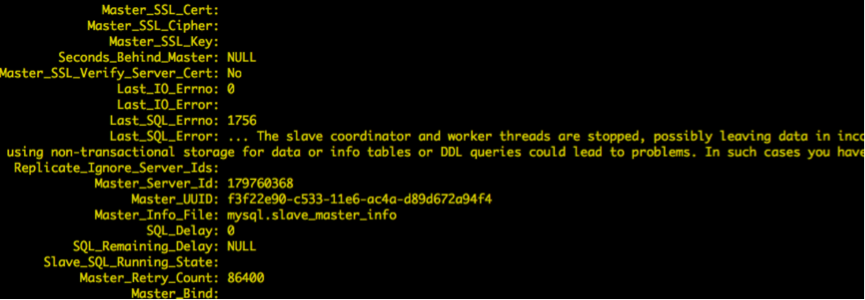
复制过程中,出现了1756错误,根据错误日志和debug确认是slave-sql线程在更新slave_worker_info表时出错导致,堆栈如下:
#7 0x0000000000a30104 in Rpl_info_table::do_flush_info (this=0x2b9999c9de00, force=<optimized out>) at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/sql/rpl_info_table.cc:171
#8 0x0000000000a299b1 in flush_info (force=true, this=<optimized out>) at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/sql/rpl_info_handler.h:92
#9 Slave_worker::flush_info (this=0x2b9999f80000, force=<optimized out>) at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/sql/rpl_rli_pdb.cc:318
#10 0x0000000000a29d95 in Slave_worker::commit_positions (this=this@entry=0x2b9999f80000, ev=ev@entry=0x2b9999c9ab00, ptr_g=ptr_g@entry=0x2b9999daca00, force=<optimized out>)
at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/sql/rpl_rli_pdb.cc:582
#11 0x00000000009d61f0 in Xid_log_event::do_apply_event_worker (this=0x2b9999c9ab00, w=0x2b9999f80000) at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/sql/log_event.cc:74
这里简单介绍下复制相关的位点表,在并行复制模式下,参与复制的主要有三个角色,slave_io线程负责将主库的binlog拉取到本地;slave_sql线程读取binlog并根据一定的规则分发给各个slave_worker;slave_worker线程回放主库的操作,达到与主库同步的目的。slave_io线程和slave_sql线程分别只有一个,而worker线程可以有1个或多个,可以依据参数slave_parallel_workers设置。如果将slave_parallel_workers设置为0,则表示关闭并行复制,slave_sql线程承担回放的工作。位点表主要有3张,包括slave_worker_info,slave_relay_log_info和slave_master_info表。slave_io线程更新slave_master_info表,更新拉取的最新位置;slave_sql线程更新slave_relay_log_info表,更新同步位点;而slave_worker线程更新slave_worker_info,每个worker线程在该表中都对应一条记录,每个worker各自更新自己的位点。
Slave_worker的工作流程如下:
1) 读取event,调用do_apply_event进行回放;
2) 遇到xid event(commit/rollback event),表示事务结束,调用commit_positions更新位点信息;
3) 调用do_commit提交事务。
从我们抓的堆栈来看,是worker线程在执行执行第2步出错,现在我们得到了初步的信息,更新位点表失败直接导致了错误。
问题定位与分析
接下来,我们要看看最终是什么导致了更新位点表失败?根据最后的错误码,我们调试时设置了若干断点,最终得到了如下堆栈
#0 myrocks::Rdb_transaction::set_status_error (this=0x2b99b6c5b400, thd=0x2b99b6c51000, s=..., kd=std::shared_ptr (count 18, weak 0) 0x2b997fbd7910,
tbl_def=0x2b9981bc95b0) at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/storage/rocksdb/ha_rocksdb.cc:1460
#1 0x0000000000a6da28 in myrocks::ha_rocksdb::check_and_lock_unique_pk (this=this@entry=0x2b997fbb3010, key_id=key_id@entry=0, row_info=...,
found=found@entry=0x2b9a58ca77ef, pk_changed=pk_changed@entry=0x2b9a58ca782f)
at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/storage/rocksdb/ha_rocksdb.cc:7092
#2 0x0000000000a6e8a8 in myrocks::ha_rocksdb::check_uniqueness_and_lock (this=this@entry=0x2b997fbb3010, row_info=..., pk_changed=pk_changed@entry=0x2b9a58ca782f)
at /home/admin/95_20161208115448428_15352432_code/rpm_workspace/storage/rocksdb/ha_rocksdb.cc:7250
#3 0x0000000000a7386a in myrocks::ha_rocksdb::update_write_row (this=this@entry=0x2b997fbb3010, old_data=old_data@entry=0x0
通过代码分析得到了如下信息:
更新位点表之所以失败是因为更新记录时发现已经存在了一条记录,这条记录的sequnceNumber比当前快照获取的sequnceNumber大,所以报错。这里简单介绍下sequenceNumber,sequenceNumber是全局递增的,内部存储为一个7字节的整数,Rocksdb依赖sequenceNumber实现MVCC。每条记录有一个唯一的sequenceNumber,rocksdb利用sequenceNumber进行可见性判断。事务在提交时,获取当前最大的sequenceNumber,并按照先后顺序为事务中的每条记录分配一个sequenceNumber,然后写入memtable。同一个key的多个不同的sequenceNumber记录按照逆序存放,即sequenceNumber最大的key放在最前面,最小的放在最后面。表1中key-n,key表示key值,n表示key对应sequenceNumber,假设key1<key2<key3<key4,则存储顺序如下:
|
Key1-100 |
Key1-50 |
Key2-120 |
Key2-80 |
Key3-70 |
Key4-150 |
|
ValueA |
ValueB |
ValueC |
ValueD |
ValueE |
ValueF |
进行读取时,会利用sequenceNumber建立一个快照,读取快照发生前的已经存在的记录,系统之后的变更与本快照无关。假设快照的sequenceNumber是150,执行get(key2)时,会找到(key2-120,ValueC);而如果快照sequenceNumber是100,执行get(key2)时,则会找到(key2-80,ValueD)。
回到问题本身,看看与问题相关的更新流程:
1.尝试对更新key加锁,如果没有并发更新,上锁成功 //TryLock
2.利用当前最大的sequenceNumberA生成快照
3.检查快照生成后,key是否被修改 // ValidateSnapshot
1)再次获取最大sequenceNumberB,构造key进行查找 // GetLatestSequenceForKey
2)查找是否存在相同的key的记录
4.若相同key的记录存在,且key的sequnceNumber大于sequenceNumberA,则认为有写冲突,报错。
我们碰到的错误正好就是遇到了写冲突报错,那么现在问题来了,明明这个key已经上锁了,并且获取了最新的sequencNumberA,为什么仍然会读到相同的key,且对应的seqeunceNumber比sequencNumberA大?结合之前分析的slave_worker_info表,我们可以作出以下猜测
大胆猜测:
- 行级锁并发没有控制好,导致多个线程同时更新
- 某些路径下,快照的sequenceNumber比较旧,不是最新
- slave_worker线程并发没有控制好,多个worker同时更新一条记录
小心求证:
现象看起来是这么的不合理,所有的假设感觉都是不攻自破,但是事实如此,唯有通过更多的信息来辅佐我们进一步判断。结合代码,我们对于上面怀疑的几个点,在相关路径下进行埋点验证。埋点主要为了得到以下信息:
- 具体哪个worker出错了,出错的是哪个key,sequence是多少?
- worker与key的映射关系
- 这个key在出错前被谁更新过?
- 每个事务包含的记录个数是多少?
获得日志如下:
Resource busy: seq:38818368818, key_seq:38818368817, index number is 0-0-1-2, pk is 0-0-0-10, thread is 46983376549632 映射关系: worker id is 10, thread is 46983367104256 //写memtable线程 worker id is 9, thread is 46983376549632 //出错线程 worker id is 11, thread is 46983359772416 //事务提交线程 写memtable线程: 2016-12-19 16:42:06 53743 [ERROR] LibRocksDB:In Memtable, index_num is 0-0-1-2, pk is 0-0-0-10, seq is 38818368818, thread is 46983367104256 2016-12-19 16:42:06 53743 [ERROR] LibRocksDB:In Memtable, index_num is 0-0-1-2, pk is 0-0-0-4, seq is 38818368665, thread is 46983367104256 2016-12-19 16:42:06 53743 [ERROR] LibRocksDB:In Memtable, index_num is 0-0-1-2, pk is 0-0-0-3, seq is 38818368675, thread is 46983367104256 提交线程: type is commit, write_start, thread is 46983359772416, seq is 38818368817 type is commit, write_end, thread is 46983359772416, seq is 38818368818, count is 1
报错的直接原因就是 已存在相同key的sequenceNumber 38818368818大于快照的squenceNumber 38818368817。这个冲突的key由worker 10写入memtable,但是由worker 11提交,并不是出错的线程。总结下来, 我们发现几个奇怪的现象:
1. 存在多个线程写一个key的情况,比如worker10曾经写过key为10,4,和3的记录
2. 对于出错的sequenceNumber(38818368818)的key,为什么会被worker11提交
3. 日志中发现SequenceNumber不连续,存在跳跃的现象
前两个问题很容易让我们陷入误区,存在多个worker写同一个key的情况,而事实上这两个问题都是源于group-commit机制,其它线程可能会代替你提交,导致你会看到同一个worker写不同key的现象。这里的group-commit包括两个层次,server层group-commit和rocksdb引擎的group-commit。
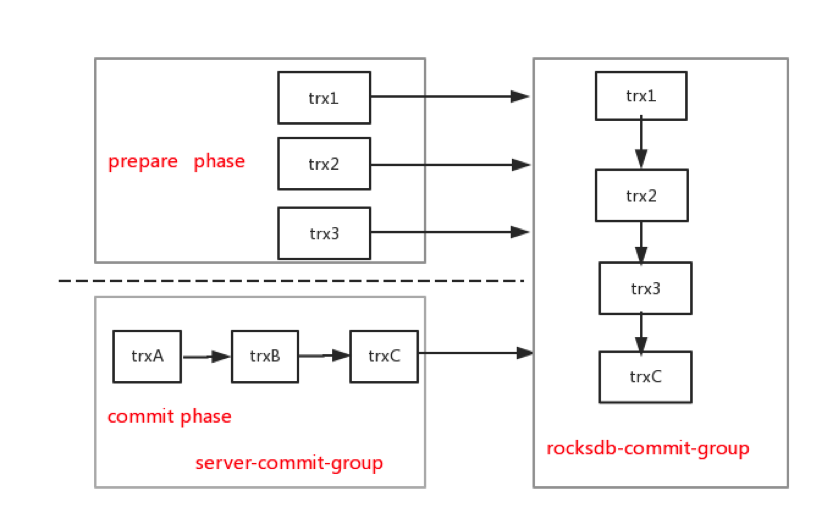
从图中可以看出,在server层group-commit机制下,流入到rocksdb引擎层commit接口的都是串行的,既然是串行的,为什么sequenceNumber会存在跳跃呢?这时候我想到了binlog_order_commits参数,之前为了提高性能,关闭了该参数,也就是在提交的最后一阶段,多个事务并发在引擎层提交,会不会与并发写memtable有关,因为在之前复现的过程中,我们发现关闭并发写memtable特性(rocksdb_allow_concurrent_memtable_write=0),问题不会复现。
但令人失望的是,在并发写memtable情况下,即使打开了binlog_ordered_commit(server层串行commit),事务串行在引擎层提交仍然会出现同样的问题。
到这里似乎陷入了死胡同,引擎层永远只有一个事务进来,为啥开启并发写memtable会影响正确性呢?因为一个事务没法并发。不知什么时候灵光一现,prepare阶段和commit阶段并发。因为rocksdb最终提交接口WriteImpl是prepare和commit公用的,通过传入的参数来区别。prepare阶段写wal日志,commit阶段写memtable和commit日志。那我们就重点来看prepare和commit并发进入WriteImpl时SequenceNumber相关的代码,果然发现了问题。这里我简单介绍下开启并发写memtable选项时,事务的提交逻辑。
1.每个事务都对应一个write-batch
2.第一个进入WriteImpl函数的线程为leader,其它线程为follower
3.leader和follower根据先后顺序串成一个链表
4.对于并发写memtable的情况,leader根据每个事务write-batch的count,计算每个事务的start-sequenceNumber。
5.leader写完wal日志后,follower根据各自start-sequenceNumber,并发写memtable
6.所有事务都写完memtable后,leader更新全局的sequenceNumber。
问题主要发生在第4个步骤,计算start-sequenceNumber时,忽略了prepare事务的判断,导致在prepare事务与commit事务成为一个group时,commit事务的sequence出现跳跃,而全局的sequenceNumber只统计了commit事务,最终导致了写入memtable的sequenceNumber比全局sequenceNumber大的现象,进而发生了后续的错误。下面列举一个错误的例子,假设slave_worker1和slave_worker2分别执行完事务trx1和trx2操作,更新位点后开始事务提交,trx1处于prepare阶段,trx2处于commit阶段,trx1和trx2组成一个commit-group, trx1是leader,trx2是follower,current_sequence 是101。
trx1: prepare phase, batch count is 3 put(user_key1,v1); put(user_key2,v2); put(user_key3,v3); trx2: commit phase, batch count is 2 put(user_keyA,v1); put(user_keyB,v2);
trx1是leader,因此trx2的start sequence 是101+3=104,写入memtable中的user_keyA的sequence是104,user_keyB的sequence是105。Current sequence推进到103。这个group结束后,对于新事务trx3, 如果Current sequnce为已经推进到120(全局任何事务提交都会推进sequence),trx3更新user_keyA,就会发现已经存在(user_keyA, 104),也就是我们遇到的错误;而另外一种情况,假设current Sequence没有推进,仍然为103,则会发生更新丢失,因为查不到(user_keyA,104)这条记录。这正好解释了,为啥我们在同步过程中,会发生丢失更新的问题。
while (w != pg->last_writer) {
// Writers that won't write don't get sequence allotment
if (!w->CallbackFailed()) {
sequence += WriteBatchInternal::Count(w->batch); # // BUG HERE: not check w-> ShouldWriteToMemtable, sequence out of bound.
}
w = w->link_newer;
w->sequence = sequence;
w->parallel_group = pg;
SetState(w, STATE_PARALLEL_FOLLOWER);
}
小插曲
到这里,我们已经回答了之前的所有疑问,问题也最终定位。但万万没想到,修改代码提交后,复制问题依旧存在,我感叹是不是不只一个bug。于是继续查,看了下日志,已经不是之前的slave_worker_info表出错了,而是一张业务表。后来才发现是因为替换mysqld后隔离级别没有设置,重启实例后,隔离级别变为Read-Repeatable级别导致。这里简单说下RR隔离下,并行复制下,导致上述错误的原因。首先明确一点,RR隔离是在事务的第一个语句获取快照,以后事务中所有语句都使用这个快照,而RC隔离级别则是事务的每个语句会单独获取快照。在并行复制模式下,假设这样一种情况:
|
时间轴 |
Trx1 |
Trx2 |
|
1 |
Begin |
Begin |
|
2 |
Update t1 set v=? where k=1 |
|
|
3 |
Update t2 set v=? where k=1 |
|
|
4 |
commit |
|
|
5 |
Update t2 set v=? where k=1 |
RR隔离级别下,trx1会在第一个update语句获取快照,更新t2表时,仍然使用之前的快照,而在这期间,t2表的k=1对应的记录可能被修改,导致记录的sequenceNumber大于trx1快照的sequenceNumber,进而导致更新t2失败。而如果是RC级别,trx1执行更新t2表时则会重新获取快照,不会存在问题。
问题解决
处理sequenceNumber逻辑不正确主要会导致两个问题,备库丢失更新和备库复制中断。定位到问题原因,并且对所有疑问都有合理的解释后,修改就比较简单了,在计算start-sequenceNumber函数LaunchParallelFollowers中,添加prepare事务的判断即可,随后还需要编写测试用例稳定复现,并进行回归测试才算是最终修复这个补丁。我们将问题反馈给官方https://github.com/facebook/mysql-5.6/issues/481,很快得到了官方的确认和回复。
总结
整个排查过程还是比较曲折,因为这个bug涉及到并发,并且是特定参数组合的并发才会出问题,所以对于这种复杂的场景,通过合理假设与日志埋点能逐步得到一些结论和依据,最后抽丝剥茧获取与问题相关的信息,才最终解决问题。我们在测试验证中过程中不断发现很多看似与预期不符的日志,也正是这些日志让我们把整个流程弄透彻,离解决问题越来越近,总之不要放过任何一个疑点,因为要坚信日志不会骗人,而代码逻辑可能因为你忽略了某些分支,导致会有错误的推断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号