Jmeter性能平台
Jmeter配置
后端监听器参数设置
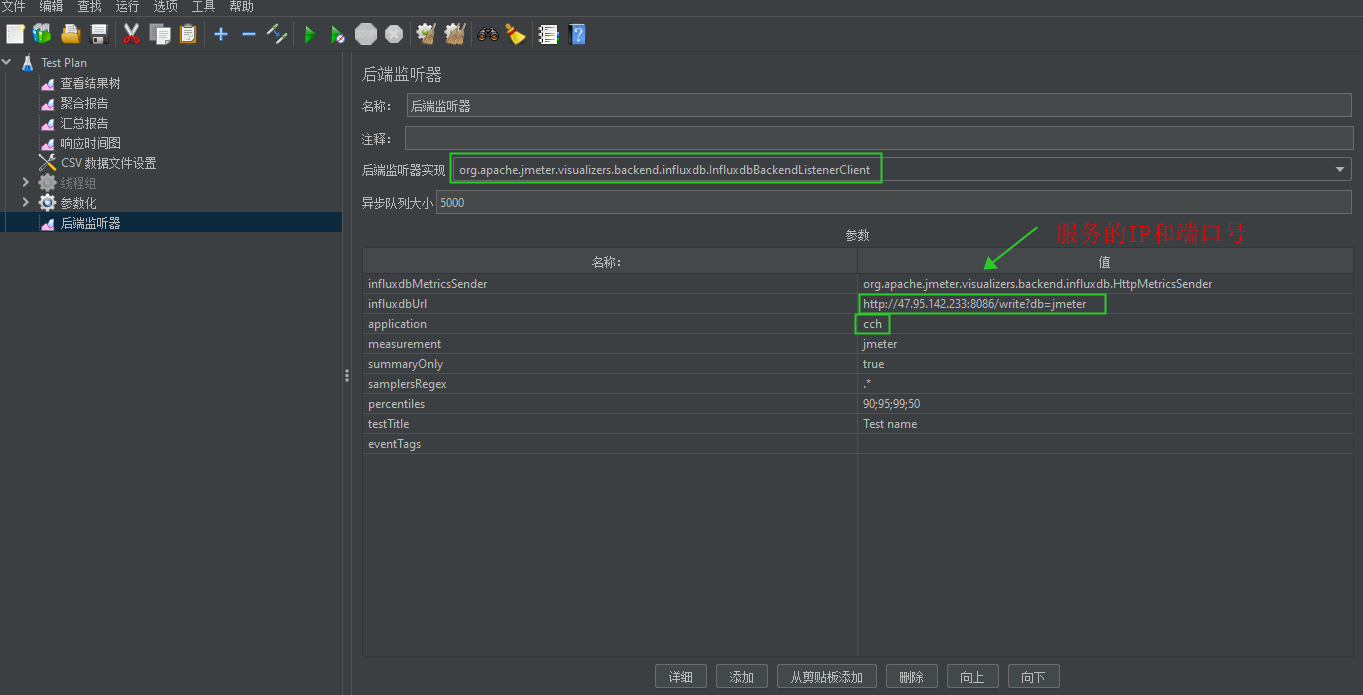
后端监听器实现原理图

Grafana可视化展示
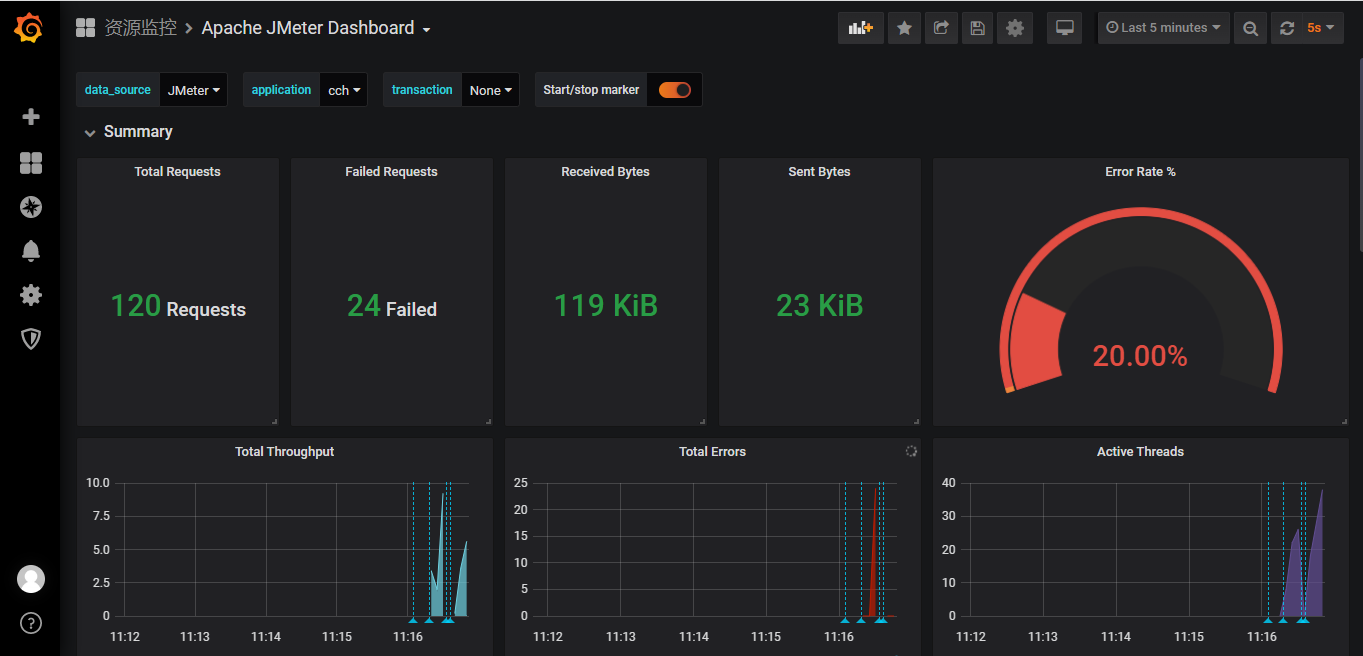
JMeter通过后端监听器把测试中的数据(响应时间,总的请求数,吞吐量等数据)写入到influxDB的时序数据库,最后grafana的平台从influxDB时序数据库获取数据,可视化展示在平台上。这样就能够看得出各个不同维度数据的变化趋势图。

2、环境变量配置
把JMeter设置到path的环境变量
3、执⾏命令
控制台进入存放.jmx脚本的路径,然后输入jmeter -n -t loginServer.jmx -l login.jtl -e -o report/(运行脚本,并生成报告)
-n 非GUI模式->在非GUI模式下运行JMeter
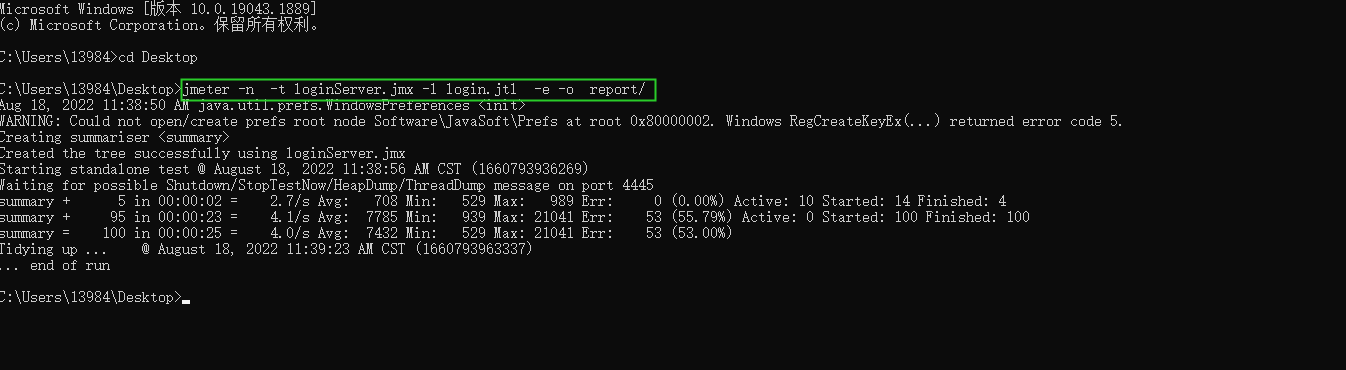
4、测试报告查看

JVM监控
JVM概述
跨平台

控制台输入java -version,查看jdk环境是否搭建好

Jvisualvm
Jvisualvm也是jdk⾃带的可视化的JVM监控⼯具,⽀持本地和远程。
Jvisualvm本地监控
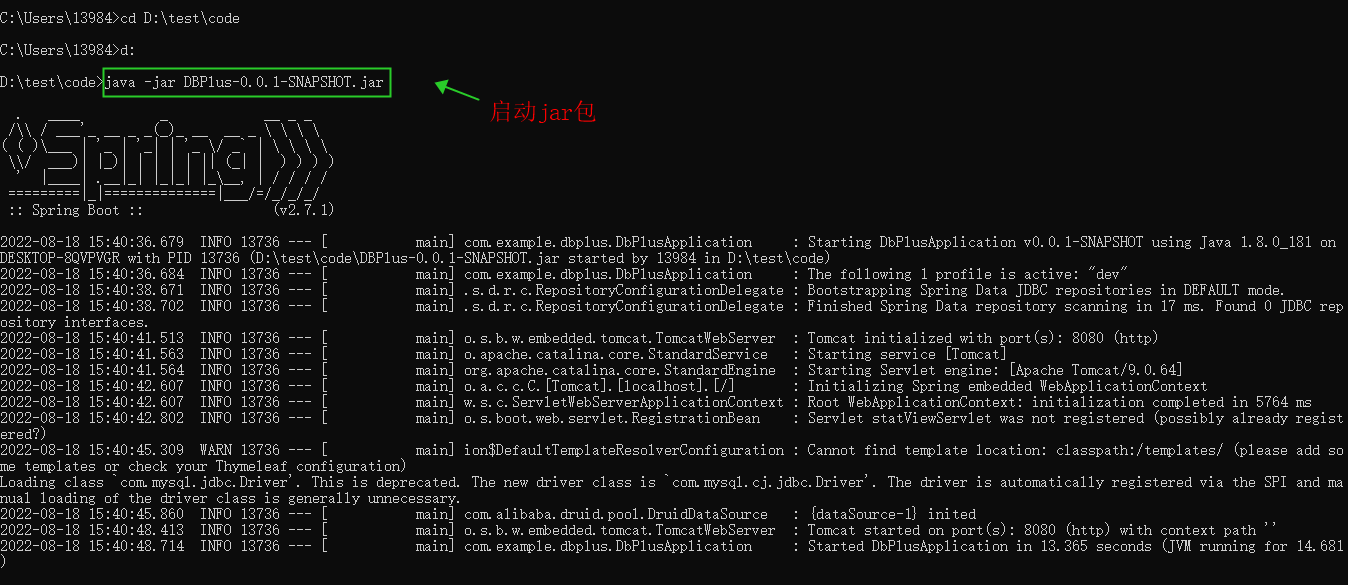
1、控制台进行入到jar包的目录下,然后输入java -jar DBPlus-0.0.1-SNAPSHOT.jar,运行jar包,如下图所示:
2、控制台输入Jvisualvm
启动后,主界⾯如下图所示:

3、启动jmeter,在新建线程组,并添加http请求。

4、进行高并发的请求,线程组参数设置如下:

5、运行任务后,查看本地的CPU的使用情况。
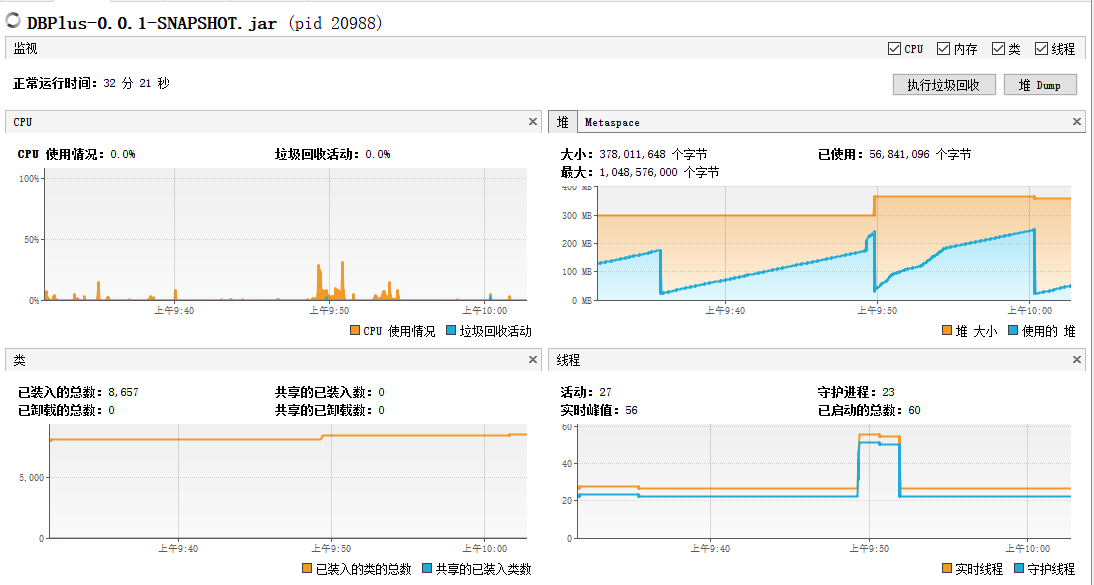
系统的CPU的资源情况


高并发请求发送后,系统CPU突然上升到100%,之后处于动态变化之中。一段时间之后可以看到内存处于下降趋势,内存的资源能够得到很好的释放,也就不会存在内存溢出的问题了。
指定运行程序的最小、最大程序以及显存
控制台输入java -jar -Xms1M -Xmx1M -XX:MaxMetaspaceSize=10m DBPlus-0.0.1-SNAPSHOT.jar
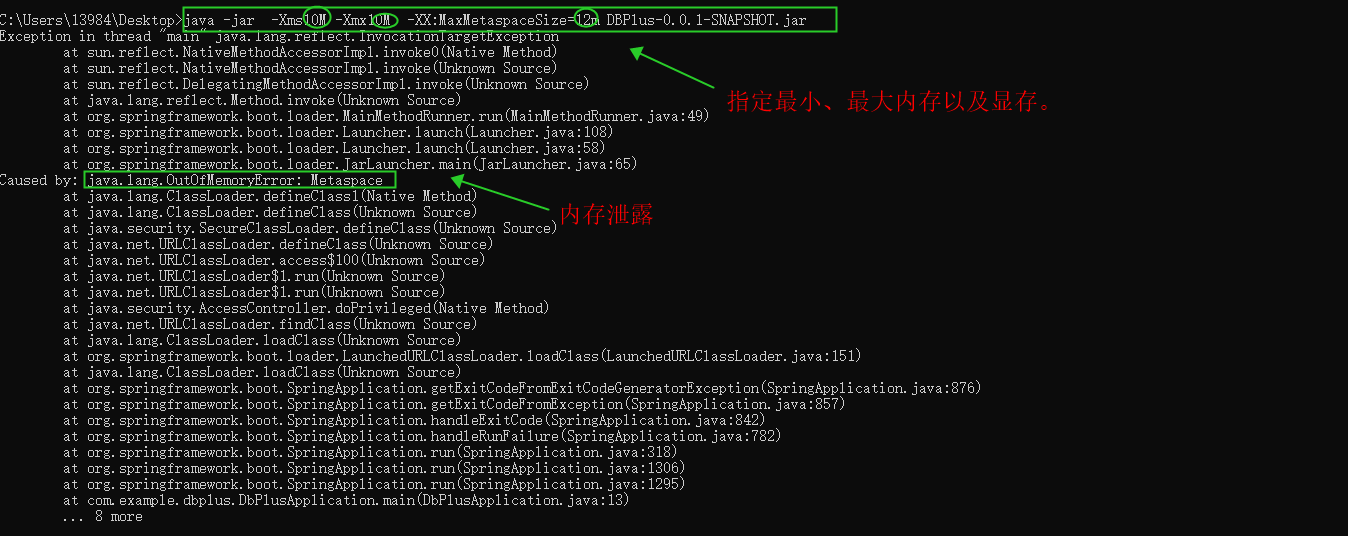
-Xms:堆内存初始大小
-Xmx:堆内存最大值
Jvisualvm远程监控
1、Jvisualvm运程监控应用程序,需要在执行的是否指定运程服务器的主机名和端口号
java -Djava.rmi.server.hostname=101.43.158.84 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -jar -Xms8m -Xmx512m -XX:PermSize=512M -XX:MaxPermSize=1G DBPlus-0.0.1-SNAPSHOT.jar
-Xms:堆内存初始大小
-Xmx:堆内存最大值
-XX:PermSize:永久内存初始大小
-XX:MaxPermSize:永久内存最大值
2、远程启动后,再需要开启随机监听的端口:lsof -i | grep java
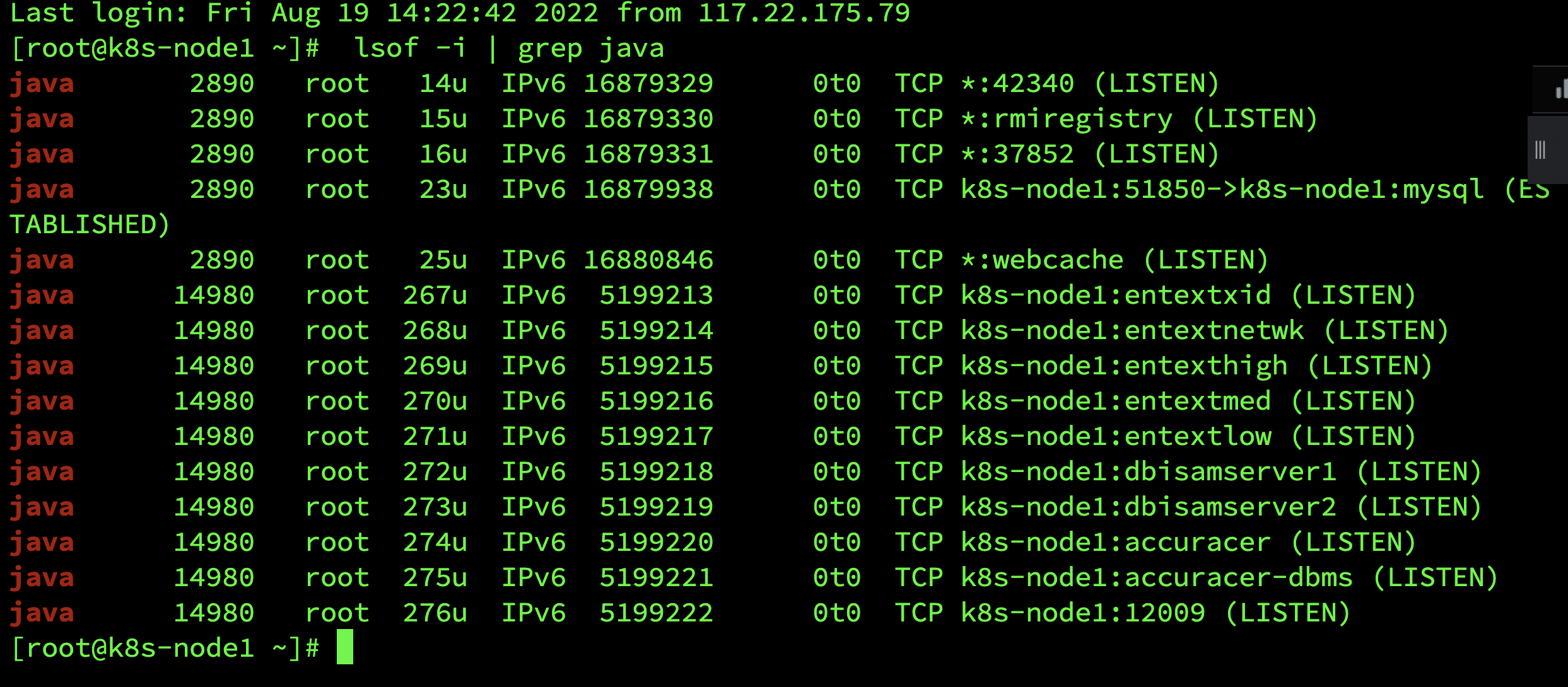
云服务器端口需手动开放
3、在远程添加远程主机


4、添加JMX连接

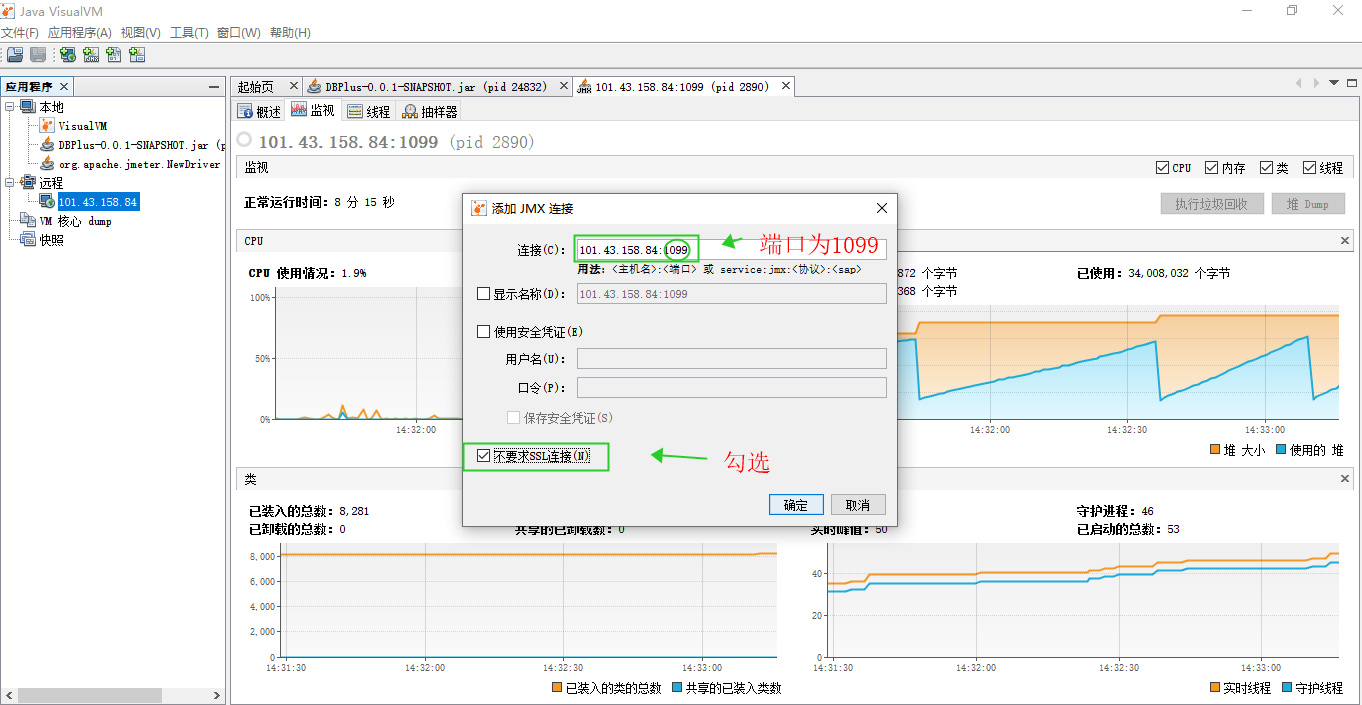
JVM远程监控添加成功如下:
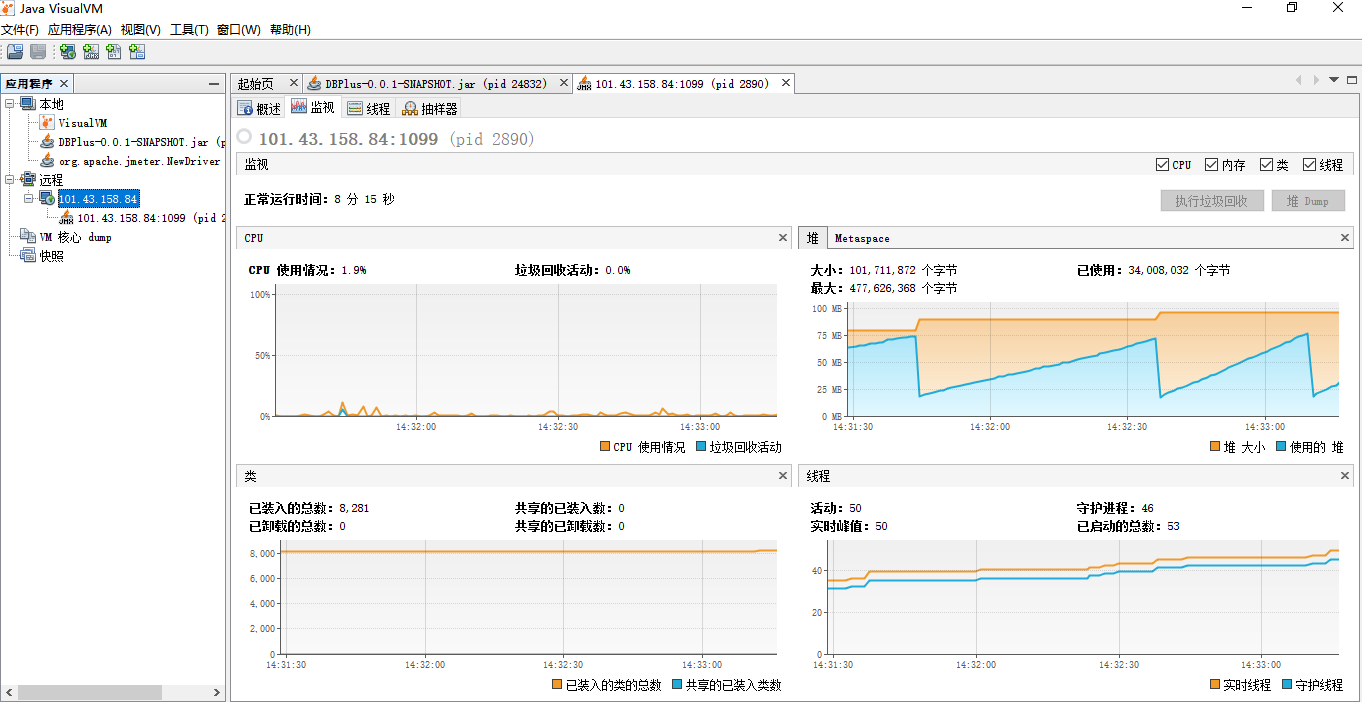
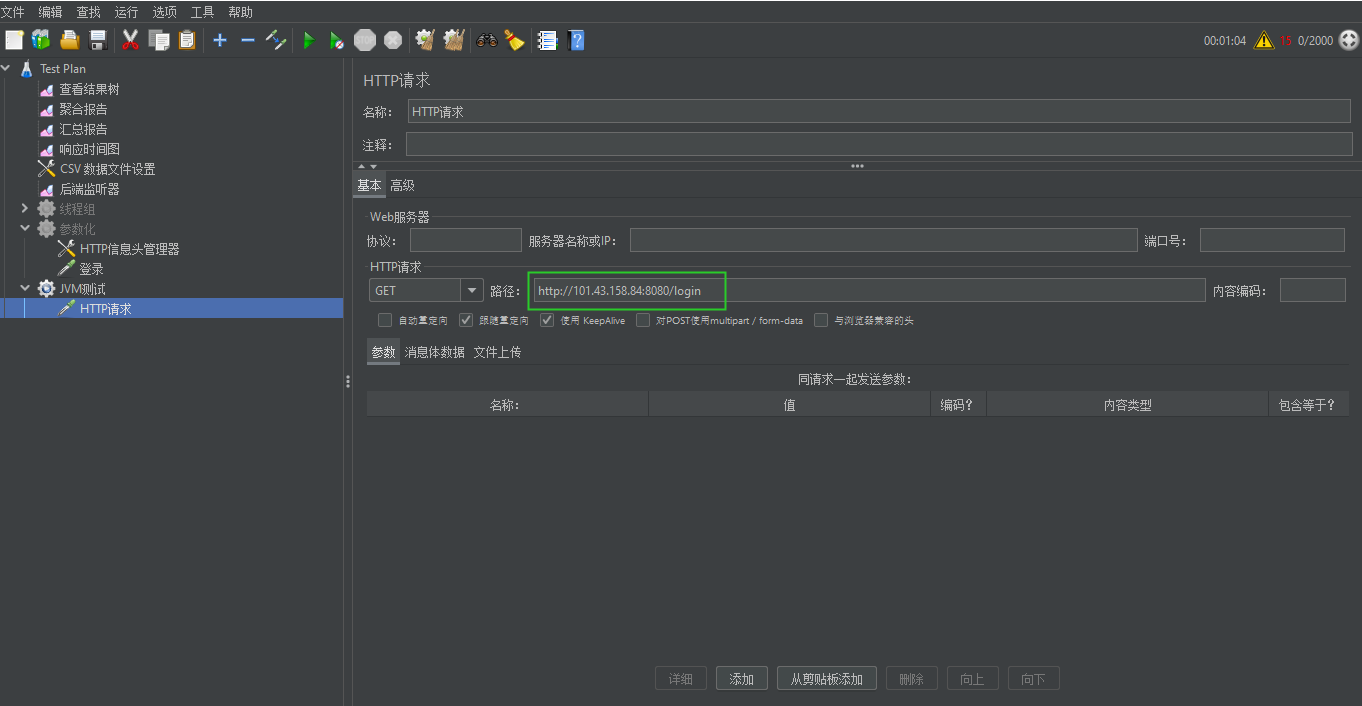
在jmeter的JVM测试线程组中设置参数如下:
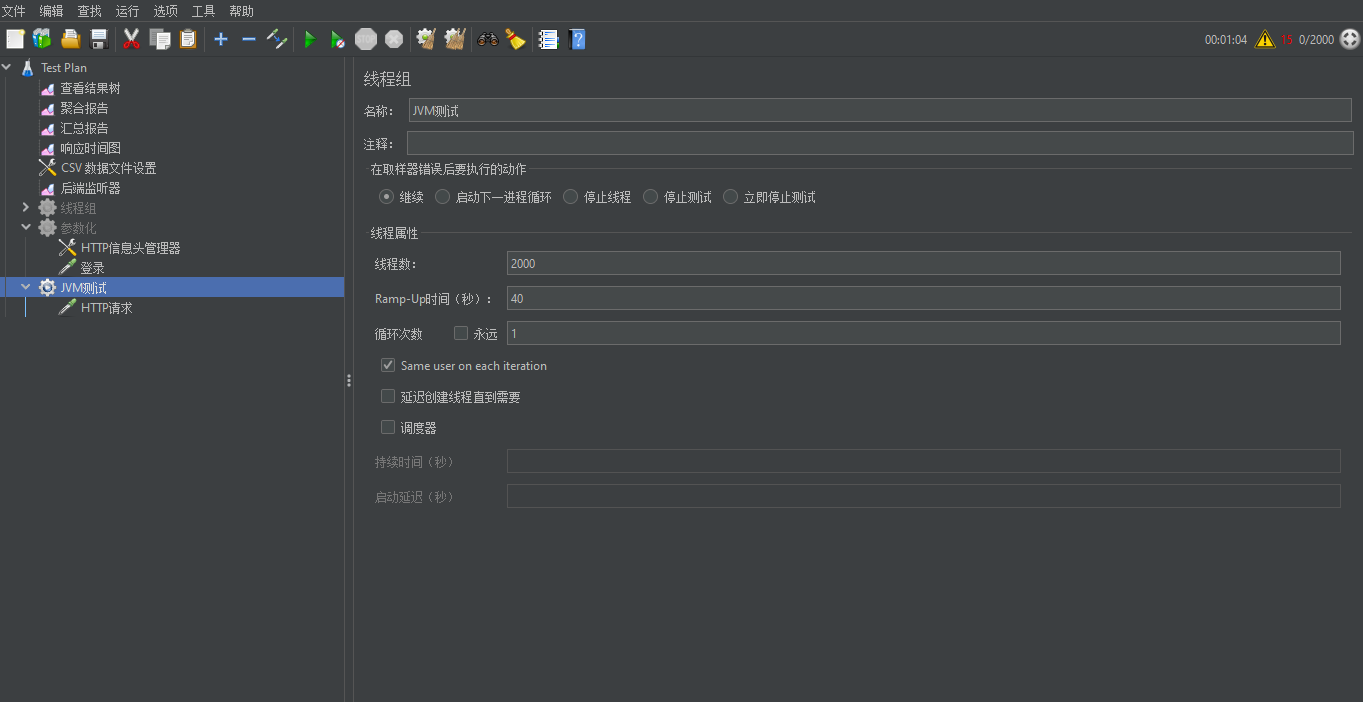
http请求地址如下:
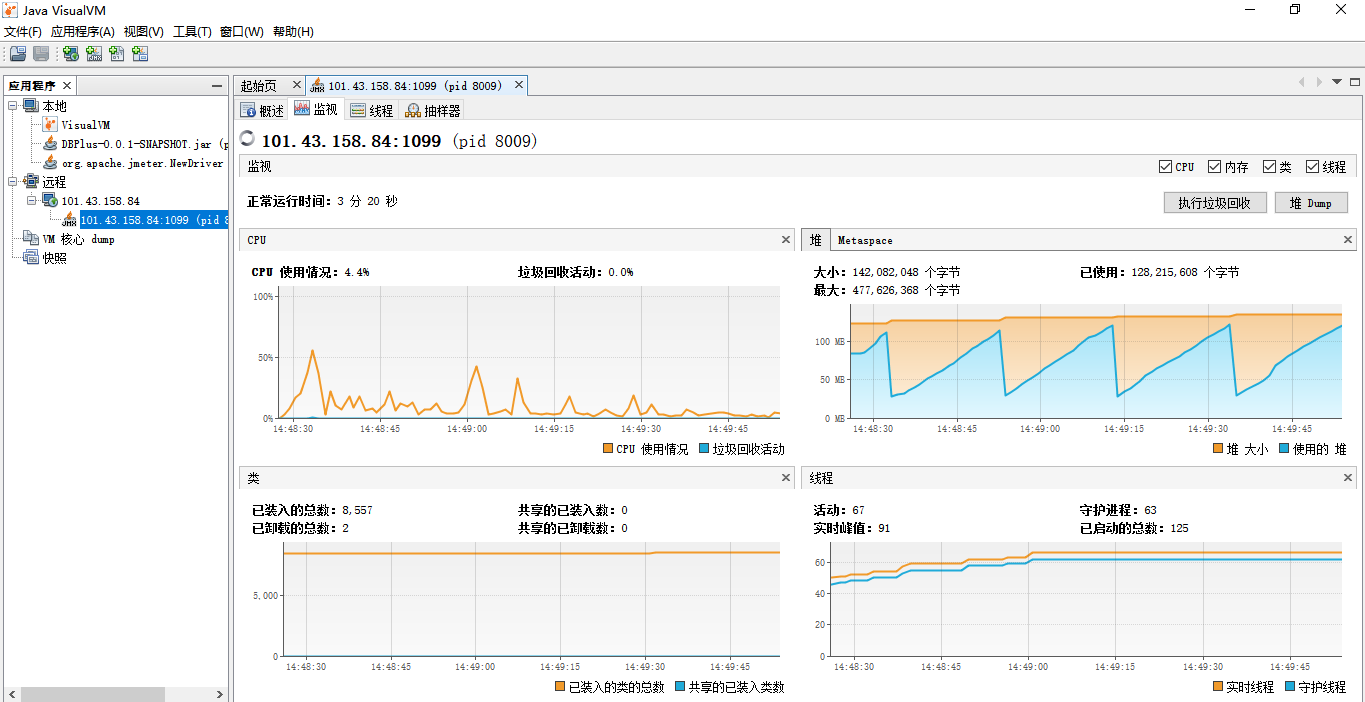
高并发请求发送后,在Jvisualvm的监控如下:
locust实战
locust概述
locust:是基于Python语言的性能测试工具,它是基于协程的思想来进行设计的。Python语言是没有办法利用多核的优势,所以了Python为了解决这个问题,设计了协程,作为协程的任务,遇到IO堵塞就立刻切换。 协程可以简单的来说就是微线程。
locust主要做负载测试和稳定性测试,也可以做压力测试。
1、安装locust,控制台输入pip3 install locust,安装成功后如下图所示:


WEB模式
以登录服务为例
2、编写locustfile文件,并保存在桌面
1 import time 2 from locust import HttpUser,task,between 3 class QuickStartUser(HttpUser): 4 wait_time = between(1,2.5) 5 @task 6 def index(self): 7 r=self.client.get('/login') 8 assert r.status_code==200
在@task⾥⾯,我们使⽤装饰器定义了微线程的⽤户请求,也就是模拟⽤户请求路由地址为/login的接⼝信息。wait_time是模拟每个⽤户耗时是在1⾄2.5秒之间。
3、控制台进入桌面输入命令:locust -f locustfile.py

下⾯具体针对界⾯的⽂字设置进⾏解释,具体如下:
Number of total users to simulate:设置模拟的⽤户总数
Spawn rate (users spawned/second):每秒启动的⽤户虚拟数
Host (e.g. http://www.example.com):被测的⽬标服务器的地址信息
5、编写具体的数据后,然后点击Start swarming后,⽬标服务器就会收到⼤量的请求,也就像现实⽣活中 发过⼀ 个地⽅,基本就会造⼤⾯积的破坏,下⾯具体显示点击后,界⾯展示的信息,具体如下:

下⾯具体看这些信息展示的含义,具体总结如下:Type:请求类型(也就是请求具体是那个=⽅法)
Name:请求的路径地址信息
Requests:当前已完成的请求数量(协程方式,指总的请求数)
Fails:当前失败的数量
Mediam(ms): 响应时间的中位数
90%ile (ms):90%的请求响应时间
Average (ms):平均响应时间
Min (ms):最⼩响应时间
Max (ms):最⼤响应时间
Average size (bytes):平均请求的数据量
Current RPS:每秒中处理请求的数量,也就是RPS
菜单栏具体为:
New test:点击该按钮可对模拟的总虚拟⽤户数和每秒启动的虚拟⽤户数进⾏编辑;
Statistics:聚合报告
Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟⽤户数;
Failures:失败请求的展示界⾯;
Exceptions:异常请求的展示界⾯;
Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions;
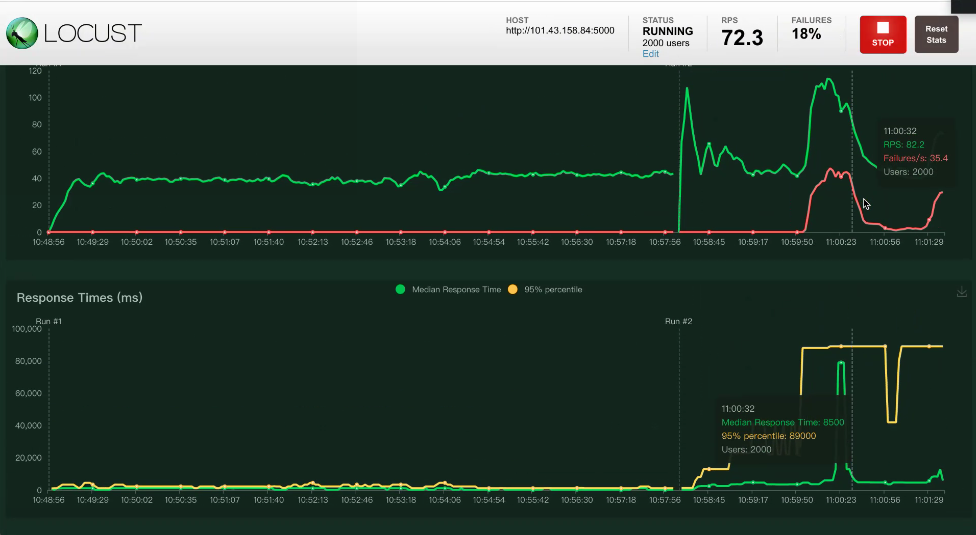
每秒的请求数与响应时间的图同一时间点的请求数、虚拟用户数、响应时间是一一对应的。
负载测试
1 import time 2 from locust import HttpUser,task,between 3 class QuickStartUser(HttpUser): 4 host = 'http://127.0.0.1:5000' 5 min_wait = 3000 6 max_wait = 6000 7 @task 8 def index(self): 9 r=self.client.get('/login') 10 assert r.status_code==200
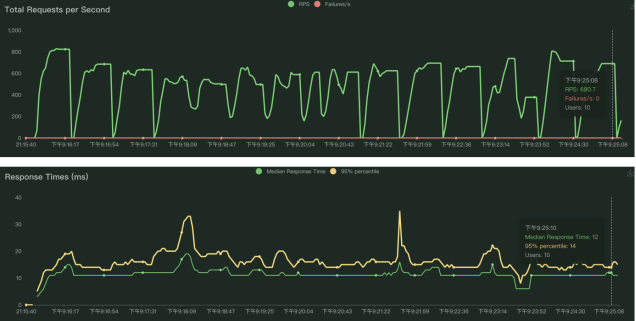
2、控制台进入桌面输入命令:locust -f locustfile.py

1、Test and Report informations
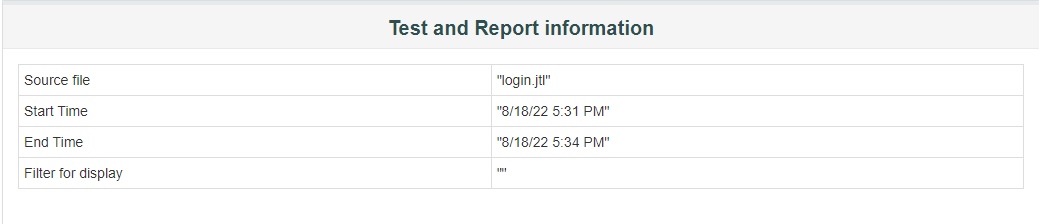
可获得报告运行结果文件为login.jtl,此报告对应运行开始时间(8/18/22 5:31 PM)和结束时间(8/18/22 5:34 PM)。
2、APDEX (Application Performance Index)

APDEX:应用程序性能指标。Apdex(Application Performance Index)是一个国际通用标准,Apdex是用户对应用性能满意度的量化值。
Apdex:性能结果,范围0-1,0表示没有满意用户,1表示所有用户都满意。
T:满意阈值(toleration threashold:耐受阈值),小于或等于该值,表示满意。
F:失败阈值(frustration threashold:挫折门槛),大于或等于该值,表示不满意。
处于T与F之间,表示可容忍。
Apdex 定义了 3 个用户满意度区间(默认定义的 T 值为 0.5 秒):
满意:这样的响应时间让用户感到很愉快,响应时间少于 T秒钟。
容忍:慢了一点,但还可以接受,继续这一应用过程,响应时间 T~3T 秒。
失望:太慢了,受不了了,用户决定放弃这个应用,响应时间超过3T 秒。
计算Apdex需要用到数据:Statistics中请求对应的samples数和Response Time Percentiles中达到满意阈值对应的百分比(取下限)。
3、Requests Summary
所有Request的成功和失败比例,OK表示成功,KO表示失败。

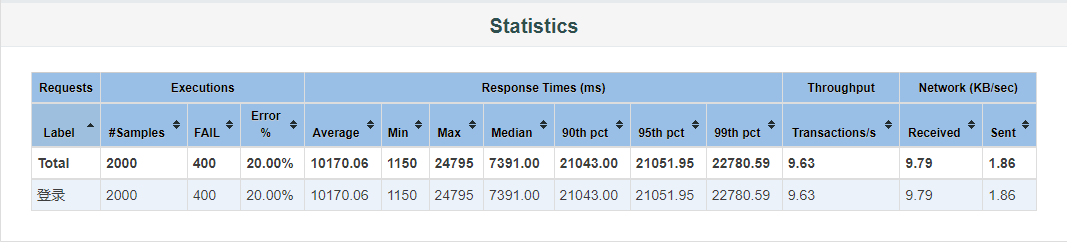
4、Statistics
Samples:测试过程中发出的请求数
KO:失败数量
Error:失败率
Average:平均响应时间,单位毫秒
Min:最小响应时间,单位毫秒
Max:最大响应时间,单位毫秒
90th/95th/99thpct:请求响应时间按照从小到大排序后第90%、95%、99%的线程响应时间,代表90%/95%/99%的请求的响应时间在这个范围之内
Throughput:吞吐量,每毫秒完成的请求数量
Received:每秒从服务器端接收到的数据量,以kb为计算的单位
Sent:每秒向服务器端发送的数据量,以kb为计算的单位
5、Errors
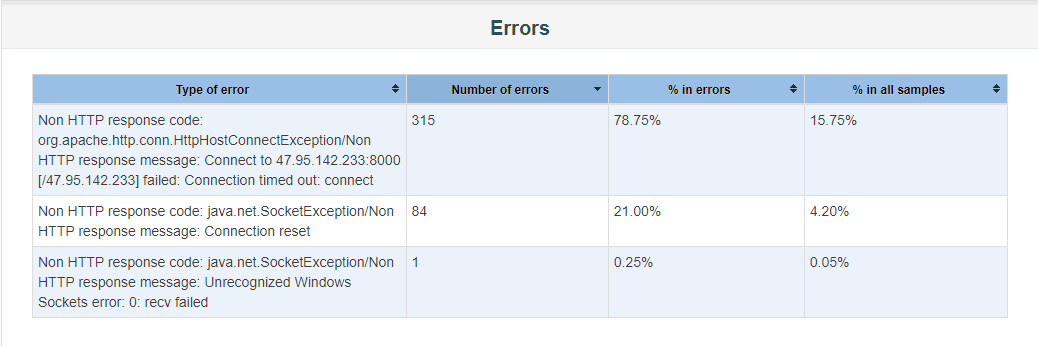
6、Top 5 Errors by sampler
排名前五的Error。

二、Charts
1、OverTime
(1) Response Time Over Time(脚本运行期间的响应时间变化趋势图)
随时间变化,每个时间节点上的线程平均响应时间。
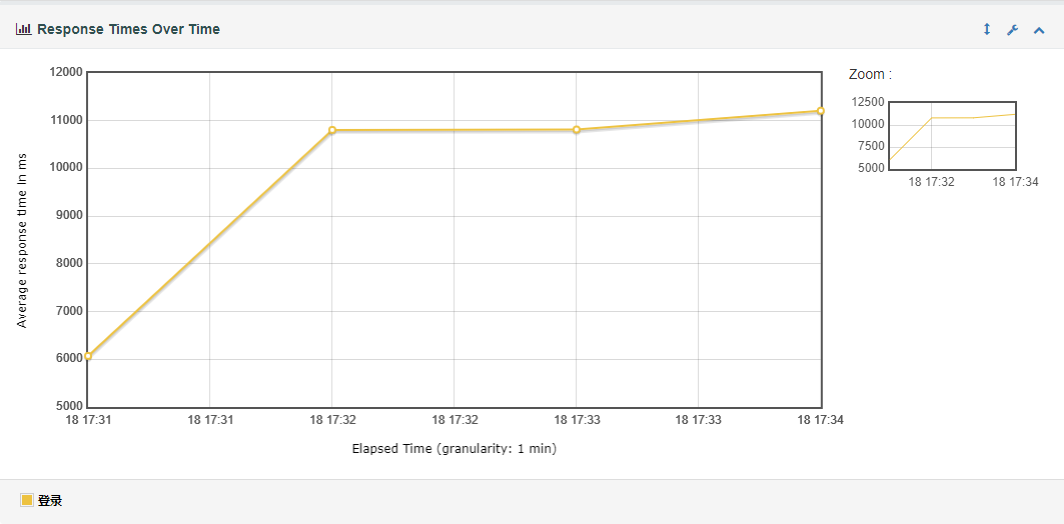
说明:可以根据响应时间变化和TPS以及模拟的并发数变化,判断性能拐点的范围。
(2) Response Time Percentiles Over Time (successful responses)
随时间变化,每个时间节点上的最长/最短/90%/95%/99%的线程响应时间。

说明:脚本运行期间成功的请求响应时间百分比分布图,可以理解为聚合报告里面不同%的数据,图形化展示的结果。
(3) Active Threads Over Time
随时间变化,每个时间节点上的活动线程数。

(4) Bytes Throughput Over Time(脚本运行期间的吞吐量变化趋势图)
随时间变化,每个时间节点上接收和发送的数据量(byte)。

说明:在容量规划、可用性测试和大文件上传下载场景中,吞吐量是很重要的一个监控和分析指标。
(5) Latencies Over Time(脚本运行期间的响应延时变化趋势图)
随时间变化,每个时间节点上的平均响应延时。

说明:在高并发场景或者强业务强数据一致性场景,延时是个很严重的影响因素。
(6) Connect Time Over Time
随时间变化,每个时间节点花费在连接上的平均时间。

2、Thoughput
(1) Hits Per Second (excluding embedded resources-排除嵌入式资源)
每秒钟向服务器发送的请求数量。

(2) Codes Per Second (excluding embedded resources-排除嵌入式资源)
每秒钟服务器返回的Response Code数量。

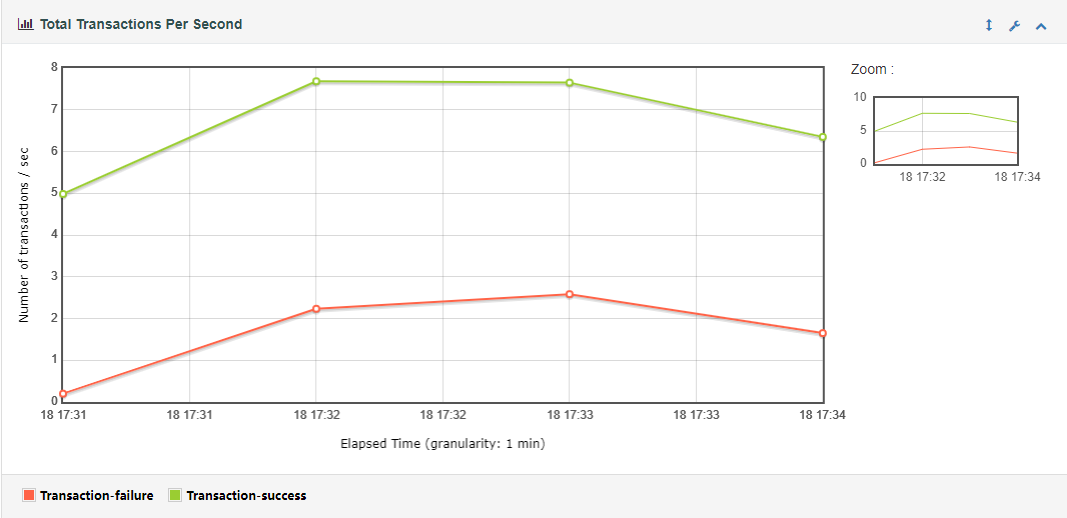
(3) Transactions Per Second(每秒事务数)
服务器每秒钟处理的事务数量。
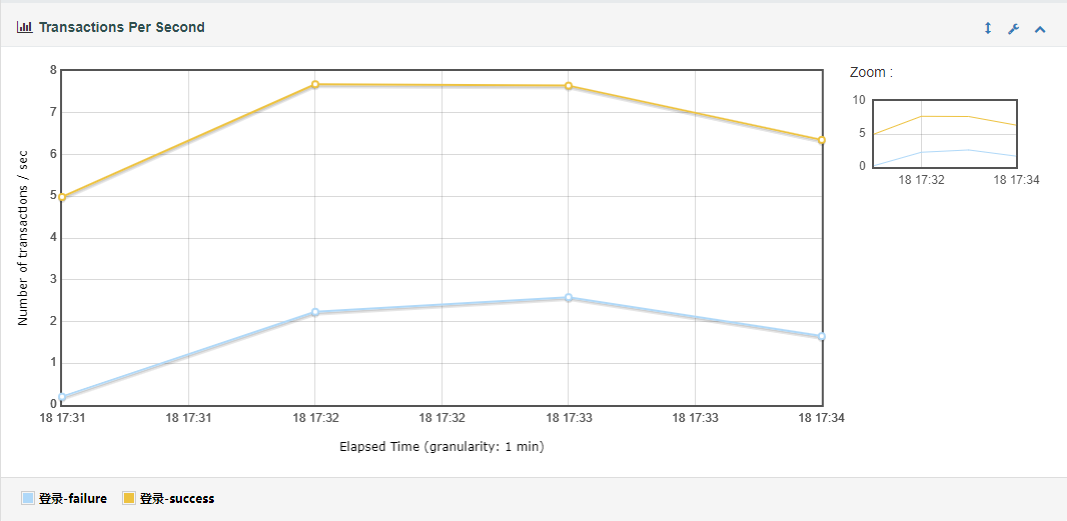
说明:每秒事务数,即TPS,是性能测试中很重要的一个指标,它是用来衡量系统处理能力的一个重要指标。
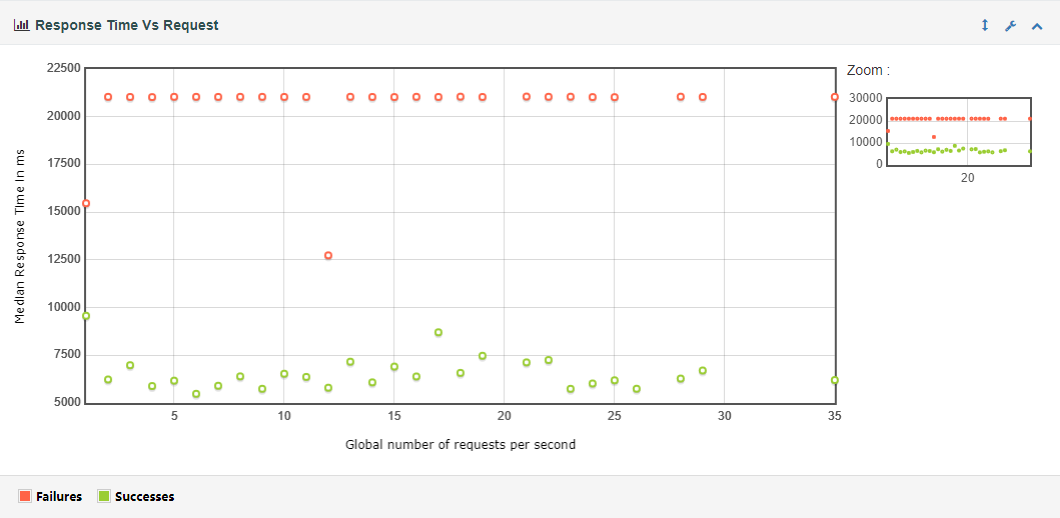
(4) Response Time Vs Request
每秒发送多少个请求时,所对应的平均响应时间。
(5) Latency Vs Request
每秒发送多少个请求时,所对应的平均延时。
3、Response Times
(1) Response Time Percentiles(响应时间百分比分布曲线图)
响应时间与百分比的对应关系,即有百分之多少的线程花费了某一响应时间。
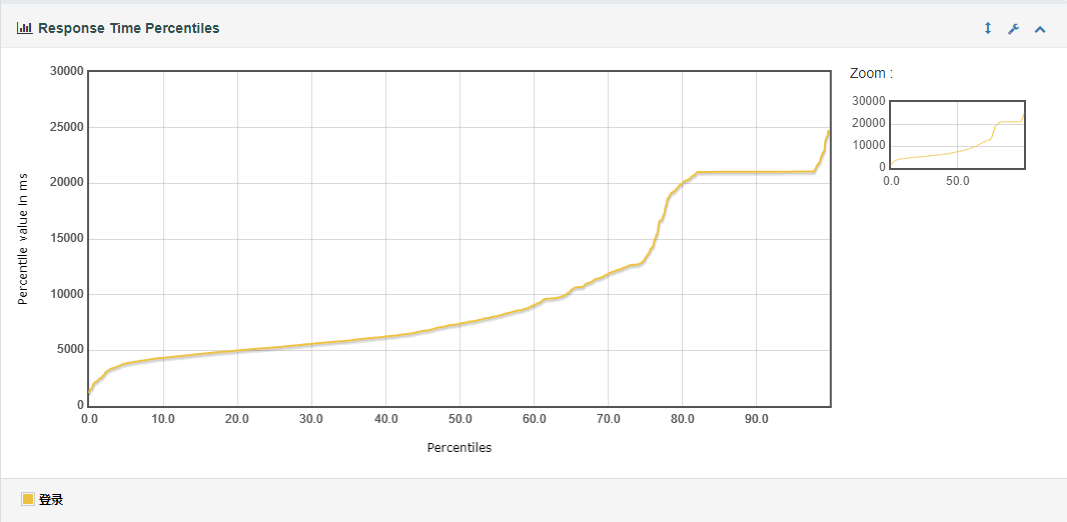
说明:即响应时间在某个范围内的请求在所有请求数中所占的比率,相比于平均响应时间,这个值更适合用来衡量系统的稳定性。
(2) Response Time Overview
小于T,大于T小于F,大于F的线程数各有多少。

(3) Time Vs Threads(平均响应时间和线程数的对应变化曲线)
N个活动线程情况下的平均响应时间。

说明:可以通过这个对应的变化曲线来作为确定性能拐点的一个参考值。
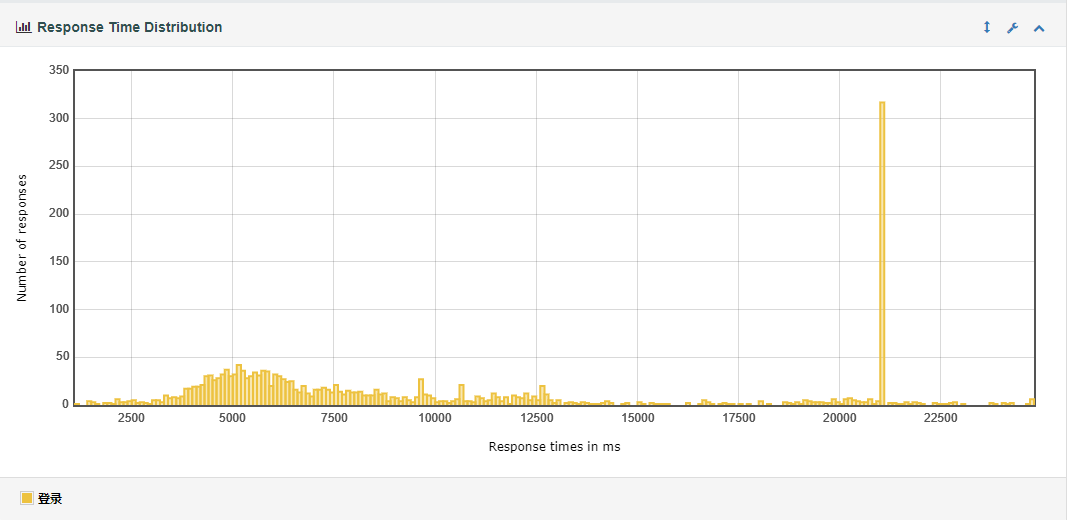
(4) Response Time Distribution
在某一响应时间段内的线程响应数量。
Linux主机详情

CPU使用率
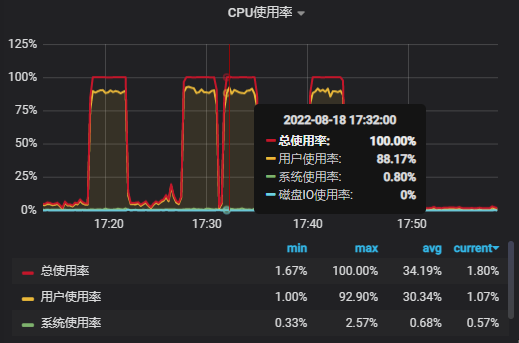
系统平均负载

每秒网络带宽使用

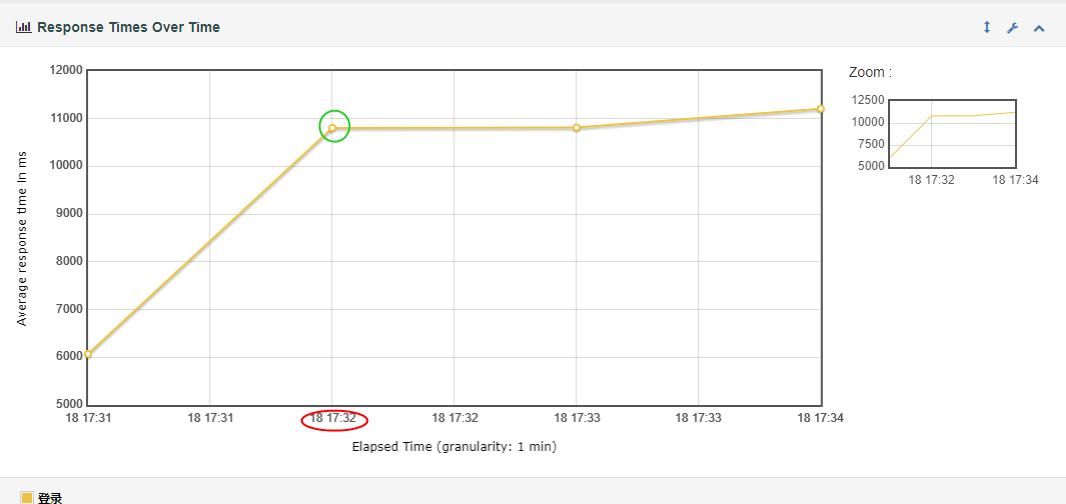
在性能17:32的时候是性能的第一个的拐点,此时响应时间呈上升趋势,遇到性能瓶颈,CPU占满,平均负载增长。
思考:
1、虚拟用户数是:1000用户数 每秒并发50用户
1)监控哪些资源 2)怎么测?
通过Jmeter添加线程组,线程属性中设置线程数分别为500、800、1200、1500,ramp-up的时间分别是10s、16s、24s、30s,然后添加http信息头管理器和http请求,并添加后端监视器,然后通过jmete执行测试用例,将测试过程中的数据(请求书、响应时间、吞吐量等)写入influxDB时序数据库,然后Grafana平台通过从influxDB时序数据库中获取数据,进行可视化展示,就可以通过可视化的方式查看各个指标比如系统的CPU、内存以及请求书、响应时间、吞吐量的数据。
2、需求:1G内存,1500w(目标值)发送请求是否出现内存泄漏?
结合等价类划分法,考虑到发送1800w、2000w、2500w请求时是否出现内存泄漏,假如出现内存泄漏,应该寻求何种解决方案?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号