
solr 排序与文档分数计算
solr
何为文档?
solr是一个文档存储与检索引擎,提交给solr处理的每一份数据都是一份文档。在solr的schema文件中我们可以指定字段的名称和类型,一个文档我们通过定义schema,映射为特定类型的字段集合,文档的每个字段都根据其字段类型进行内容分析,分析的结果保存在索引中,这样在发起查询的时候就能检索到相关结果。
倒排索引:
在传统的数据库模型中,都是文档映射至内容,而solr使用了索引将内容映射至文档的方式。

模糊查询机制:
当通配符搜索执行时,倒排索引中的所有词项与第一个通配符之前的查询词部分进行匹配。接下来,检查每个候选词项是否与查询中的通配符模式相匹配。
一般通配符前指定越多的词查询速度越快,如engineer*的执行花销不大,但是e*执行花销很大。在solr不建议用首位通配符,如*ing,这个会导致严重的性能问题。
默认相似度:
solr的相关度得分是基于similarity类的,默认的similarity实现及理论基础如下:
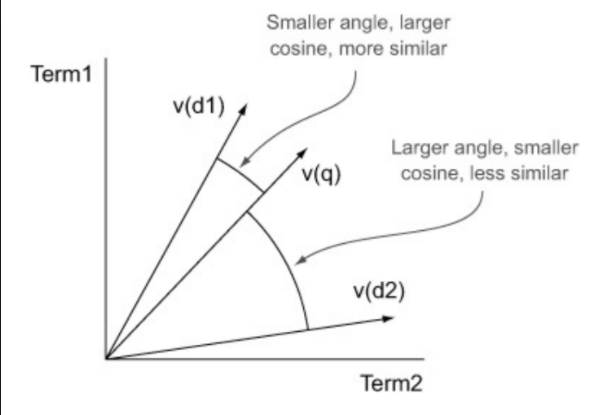
它会去检查词项向量的余弦相似度,如果词项向量的余弦相似度和文档向量的余弦相似度更接近,那么我们认为它们的相似度越高。
那么如何用构造合理的向量来表征它们呢?

词项频次tf(term frequency):
我们认为一个查询词项在一个文档中出现的越多,那么我们认为它和这个文档越相关。但是如果一个词在文档中出现10次,我们并不认为相关度应该提高10倍,所以这里开了平方根来减少查询词项多次出现的额外加分。
反向文档频次idf(inverse document frequency):
一般来说在查询匹配中我们认为较少见的词比常见的词有更好的区分度,它惩罚了在多个文档中普遍出现的词项。(感觉要视实际情况而定)
词项权重:
在实际的搜索中我们不必完全依赖与solr去计算分数,根据我们的一些经验我们可以自己去调节词项的权重,以符合我们的预期。
规范化因子:
solr默认的相关度公式计算了三种规范化因子:字段规范、查询规范和协调因子
(1)字段规范:
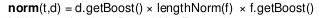
其中d.getBoost()为文档的权重,
f.getBoost()表示字段权重
lengthNorm(f)表示长度归一参数取值等于字段中词项数量的平方根,目的是消除特定词项在较长文档中出现次数较多的优势,
(2)查询规范:
queryNorm应用于所有的文档,它不会影响总体的相关性排序,它仅仅作为查询之间进行比较时得分计算的规范化因子。
(3)协调因子:
它的作用是衡量每个文档匹配的查询数量,如果查询词项是4个词,那么如果4个词全匹配到,则协调因子是4/4;匹配到3个,那么协调因子是3/4,以此类推。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号