视频学习——《Expectation-Maximization Attention Networks for Semantic Segmentation》(《语义分割中的自注意力机制和低秩重建》)
视频学习——《Expectation-Maximization Attention Networks for Semantic Segmentation》(《语义分割中的自注意力机制和低秩重建》)
原文详细讲解,见《[ICCV 2019 Oral] 期望最大化注意力网络 EMANet 详解》
一、基础概念扫盲
- 语义分割:计算机视觉中的基础任务,在语义分割中我们需要将视觉输入分为不同的语义可解释类别。
- 语义的可解释性:分类类别在真实世界中是有意义的。
- 语义分割的目的:为每个像素预测类别标签。
- Nonlocal神经网络:非局部操作。使得每个像素可以充分捕获全局信息。
- 注意力机制:模仿生物观察行为的内部过程,将内部经验和外部感觉对齐从而增加部分区域的观察精细度的极值。
- 自注意力机制:注意力机制的改进,减少对外部信息的依赖,擅长捕捉数据或特征的内部相关性。
- 最大化注意力机制(EMA):
- 期望最大化算法(EM):目的在于找出潜在变量模型的最大似然解。
二、详细介绍
-
期望最大化算法(EM算法)
第一步:计算期望(E),利用对隐藏变量的现有估计值,计算最大似然估计值。
第二步:最大化(M),在(E)步上求得的最大似然值来计算参数的值。(M)步上找到的参数估计值被用于下一个(E)步计算中,整个过程不断交替进行,直到满足了拟合条件。
-
高斯混合模型
高斯混合模型使用高斯分布作为参数模型,并使用期望最大算法进行训练。详细介绍见《一文详解高斯混合模型原理》
-
非局部网络(Nonlocal)
将自注意力机制使用在计算机视觉中,核心算子是:
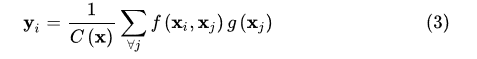
其中 表示广义的核函数,
是归一化系数。它将第
个像素的特征
更新为其他所有像素特征经过
变换之后的加权平均
,权重通过归一化后的核函数计算,表征两个像素之间的相关度。这里
,所以视为像素特征被一组过完备的基进行了重构。这组基数目巨大,且存在大量信息冗余。
-
期望最大化注意力
原理:摒弃了在全图上计算注意力图的流程,通过期望最大化算法(EM算法)迭代出一组紧凑的基,在这组基上运行注意力机制,从而大大降低了复杂度。
下图为期望最大化注意力模块(EMAU)的结构
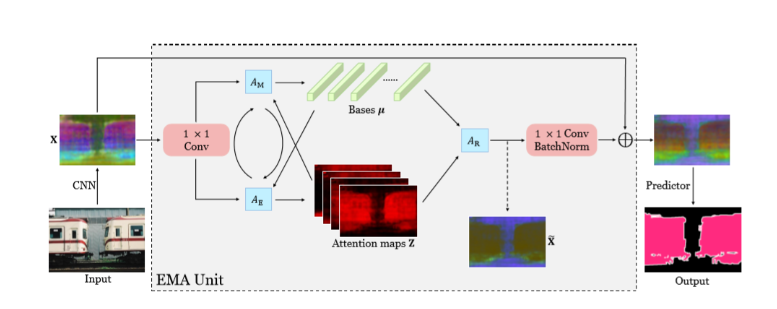
流程:
- 输入图片经过CNN网络,得到特征图X,经过1×1卷积降维
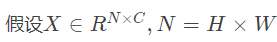 其中H和W是特征图X的分辨率尺寸
其中H和W是特征图X的分辨率尺寸- 初始化一个
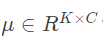 作为基,K为基的数量
作为基,K为基的数量 - E步(下面的分支):得到Attention maps Z。有K个Attention maps,每个map的尺寸是H×W
- M步(上面的分支):更新基Bases μ,得到的Attention maps Z
- 在每次M步之后,为了保证μ的学习是稳定的,选择L2Norm对μ做归一化处理
- E步和M步重复执行。
- 用得到的Attention maps Z和基μ重构X,得到
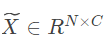
- 经过一个1×1卷积(+BN)reshape到C×H×W。
三、总结
个人认为,整个过程类似于CNN+RNN的一个组合。输入的图片先通过CNN生成特征图,再经过EMA结构进行语义分割。其中,EMA的迭代过程相当于是一个RNN。从作者的讲解中得知,RNN中采取LayerNorm(LN)来进行归一化,但是EMA中采用L2Norm来对基进行归一化,目的是避免LN改变基的方向,进而影响其语义。

