《MobileNets: EfficientConvolutionalNeuralNetworksforMobileVision Applications》论文阅读
《MobileNets: EfficientConvolutionalNeuralNetworksforMobileVision Applications》论文阅读
一、引言
- 本篇论文提出了一种称为MobileNets的高效模型,用于移动和嵌入式视觉应用。MobileNets体系结构使用深度可分离卷积来构建轻型深度神经网络
- 引入两个超参数:
- 宽度乘数 [Width Multiplier]:减少输入和输出的channels
- 分辨率乘数[Resolution Multiplier]:减少输入和输出的feature maps的大小
- MobileNets模型最终目标:
- 减少参数量和计算量
- 允许开发人员为他们的应用程序专门选择一个匹配资源限制的小型网络。
二、详细内容
2.1 概念扫盲
-
通道(channels)
输入样本中的channels(Tensorflow解释文档):一般的RGB图片,channels数量为3(红,绿,蓝);monochrome图片,channels的数量为1;
channels的含义(mxnet解释文档):每个卷积层中卷积核的数量。
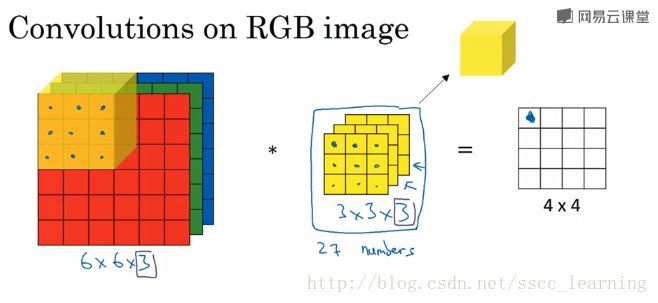
以下图为例:图片样本为6×6×3,卷积核为3×3×3
此时,输入图片的channels为3,卷积核中的in_channels与channels一致。
-
卷积(convolution)
-
卷积在二维上的计算:(原始边长-核边长+2*padding)/步长+1
-
继续以上图为例,进行卷积操作,卷积核中的27个数字分别与样本对应相乘,再求和,得到结果。
由于,只有一个卷积核,所以最终得到的结果为4×4×1,out_channels为1。
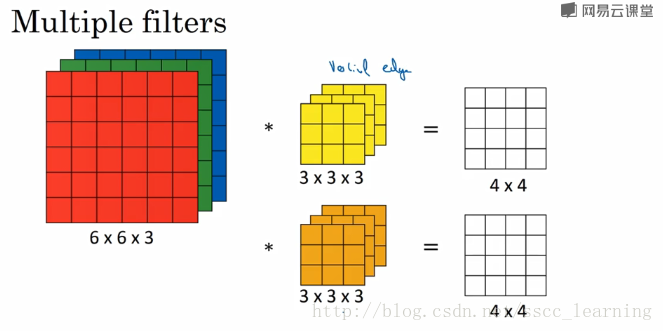
- 在实际应用中,会使用很多卷积核,如果再加一个卷积核,那么结果为4×4×2,out_channels为2。
-
-
卷积核(kernel)
-
过滤器 = 卷积核(kernel)
-
每个卷积核都具有长、宽、深三个维度;长和宽是认为指定的,卷积核的尺寸=长×宽。
-
卷积核的深度(即通道数)= 当前图像的深度。
-
-
特征图(feature map)
- 在每个卷积层中,数据都是以三维形式存在的,可以把它看成多个二维图片叠在一起,每一个称为feature map。层与层之间会有若干个卷积核(kernel),上一层和每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map。
-
滤波器(filter)
- 多个卷积核(kernel)组成的三维矩阵,多出的一维是通道。
-
深度可分卷积(Depthwise Separable Conv)
将标准的卷积(Standard Convolution)分为两部分:
- 第一部分(Depthwise Convolution):对输入的特征图的每一个通道单独做卷积,因此这里的卷积核通道数都是1,卷积核的大小不变。
- 第二部分(Pointwise Convolution):对第一部分得到的特征图做1×1卷积。
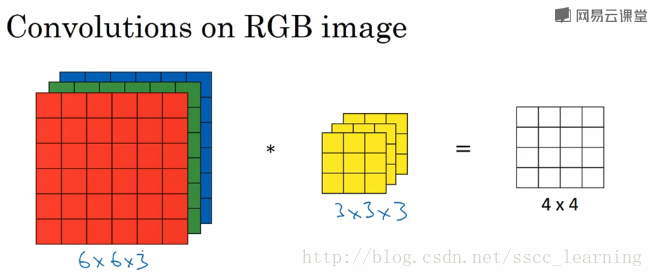
2.2 核心内容
1. 深度可分卷积(Depthwise Separable Conv)详细流程
按照前文所述,深度可分卷积将标准卷积分解为一个深度卷积(Depthwise Convolution)和一个1×1的卷积(Pointwise Convolution)。
如下图所示,(a)标准卷积;(b)分离出来的深度卷积;(c)分离出来的1×1卷积。

假设,输入特征图的大小为D_F × D_F × M,输出特征图的大小为 D_F × D_F × N,卷积核大小为 D_K × D_K 。
则标准卷积的计算量为:
D_K × D_K × M× N× D_F × D_F
深度可分卷积的计算量为(深度卷积 + 1×1卷积):
D_K × D_K × **M **× D_F × D_F+ M× N× D_F × D_F
假设,输入为28×28×192,输出为28×28×256,卷积核大小为3×3,则
深度可分卷积的计算量 / 标准卷积的计算量 =0.115
2.标准卷积和深度可分卷积结构对比
下图中,左边是标准卷积,右边是深度可分卷积。

MobileNet整体结构如下,共有28个网络层:

3. 引入参数α,β进行优化
通过引入两个超参数减少深度可分卷积中参与计算的输入通道数量和输出通道数量。
加入超参数后的深度可分卷积的计算量为:
D_K×D_K× αM× βD_F× βD_F+ αM× αN× βD_F× αD_F
三、代码练习
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
创建DataLoader
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
创建 MobileNetV1 网络
32×32×3 ==>
32×32×32 ==> 32×32×64 ==> 16×16×128 ==> 16×16×128 ==>
8×8×256 ==> 8×8×256 ==> 4×4×512 ==> 4×4×512 ==>
2×2×1024 ==> 2×2×1024
接下来为均值 pooling ==> 1×1×1024
最后全连接到 10个输出节点
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
实例化网络
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
结果:Accuracy of the network on the 10000 test images:78.64%

