用户视频(UGC)质量评估数据集
数据集
无参考数据集 - 一无所知小白龙 - 博客园
谷歌推出UGC内容的盲视频质量评估方法和基准测试 - 知乎
UGC-VQA: Benchmarking Blind Video Quality Assessment for User Generated Content
针对用户生成内容的盲视频质量评估
同时VIDEVAL的代码已开源。
作者 | Zhengzhong Tu, Yilin Wang, Neil Birkbeck, Balu Adsumilli, Alan C. Bovik
单位 | 得克萨斯大学奥斯汀分校;YouTube媒体算法团队,谷歌公司
论文 | https://arxiv.org/abs/2005.14354
代码 | https://github.com/tu184044109/VIDEVAL_release
UGC-VQA Datasets
| BVQA Dataset | Download | Paper |
|---|---|---|
| KoNViD-1k (2017) | KoNViD-1k | Hosu et al. QoMEX'17 |
| LIVE-VQC (2018) | LIVE-VQC | Sinno et al. TIP'19 |
| YouTube-UGC (2019) | YouTube-UGC | Wang et al. MMSP'19 |
| ICME |
| 名称 | CVD2014 | KoNViD-1k | LIVE-Qualcomm | LIVE-VQC | ICME | YouTube-UGC |
|---|---|---|---|---|---|---|
| 数量 | 234 | 1200 | 208 | 585 | 6400训练+800验证 | 1500 |
| 长度(秒) | 11-28 | 8 | 15 | 10 | 20 | |
| 来源 | 实验室 | 众包 | 实验室 | 众包 | 比赛 | YouTube |
| 场景(个) | 5 | 1200 | 54 | 585 | UGC | UGC |
| 设备数量 | 78 | >164 | 8 | 101 | ||
| 分辨率 | 640×480,1280×720 | 960×540 | 1920×1080 | 320×240-1920×1080 | 各种 | |
| 分数 | 0-100 | 5个等级 | 0-100 | 0-100 | 0-5 | 0-5 |
| 下载地址 | CVD2014 - A database for evaluating no-reference video quality assessment algorithms | Zenodo | KonViD-1k Database - Visual Quality Assessment Databases, MMSP Konstanz (mmsp-kn.de) | Laboratory for Image and Video Engineering - The University of Texas at Austin (utexas.edu) | Laboratory for Image and Video Engineering - The University of Texas at Austin (utexas.edu) | http://ugcvqa.com/ | YouTube-UGC |
| 特点 | 现实用户生成视频,不同分辨率和帧率,设备和损失类型更多 | 数量大,内容多样性和畸变类型丰富 | 用户生成视频,高分辨率 | 数量较大,用户生成视频手机拍摄,不同分辨率和帧率,各种场景 | 参考视频是从实用的视频共享应用程序中收集的。每个参考视频都用H.264/AVC压缩成七个位流,以覆盖广泛的压缩级别。我们进行了主观测试,以收集MOS分数,以供参考和压缩剪辑。每个剪辑由至少50名志愿者主观投票。 | 该数据集目前包含大约 1500 个(YouTube 转码前)视频剪辑。每个视频的长度约为 20 秒。提供两个版本的原始视频:RAW YUV 和 H264 CRF 10。 我们还为游戏、体育和 Vlog 视频提供 VP9 变体。 |
| 缺点 | 场景少,实验方法不一致 | 内容包括过多类型,数据类型不够集中 | 场景多但不平衡,只有手机 | 有些分辨率数量很少,更多分布在MOS高的地方 |
BVQA
| Model | Download | Paper |
|---|---|---|
| VIIDEO | VIIDEO | Mittal et al. TIP'16 |
| V-BLIINDS | V-BLIINDS | Saad et al. TIP'14 |
| TLVQM | nr-vqa-consumervideo | Korhenen et al. TIP'19 |
| VSFA | VSFA | Li et al. MM'19 |
| NSTSS | NRVQA-NSTSS | Dendi et al. TIP'20 |
| VIDEVAL | VIDEVAL_release | Tu et al. CoRR'20 |
我们为这一挑战提供了一个UGC视频质量数据集。该数据集分别包含6400个用于培训的视频剪辑和800个用于验证的视频剪辑。我们额外保留了800个视频作为测试集,但公众无法使用。参考视频是从实用的视频共享应用程序中收集的。每个参考视频都用H.264/AVC压缩成七个位流,以覆盖广泛的压缩级别。我们进行了主观测试,以收集MOS分数,以供参考和压缩剪辑。每个剪辑由至少50名志愿者主观投票。
参与者将提交一个训练有素的模型,供组织者在测试集上衡量其性能。只要在提交的手稿中提及其他数据,就允许进行培训。
MOS/DMOS文件可以直接通过以下链接下载。然而,数据集的大小约为34 GB,可以通过单个下载链接进行多维数据集下载。我们准备了一个shell脚本,使用“wget”命令下载。
以下为笔记可忽略
描述
视频质量评估(VQA)在过去二十年里一直是学术界和行业的活跃研究领域。最近,视频共享应用程序和视频会议系统的日益普及正在给VQA领域带来新的挑战。事实上,这些应用程序中的用户生成内容(UGC)视频与专业生成内容(PGC)视频具有截然不同的特征。UGC视频通常由业余爱好者在各种拍摄条件下使用智能手机相机拍摄。捕获的视频通常在压缩并上传到视频共享应用程序之前使用特效和美学过滤器进行处理。
FR VQA指标假设原始PGC视频具有完美的质量,通过测量参考视频和处理视频之间的质量退化来预测加工视频的质量。然而,这一假设通常不适用于教资会视频,需要开发新技术来缩小教资会和教资会视频之间的差距。
这项挑战的重点是估计H.264/AVC压缩UGC视频的质量。有两条轨道取决于是否使用了参考资料
-
MOS轨道,一种预测压缩剪辑的平均意见得分(MOS)的算法。请注意,测试集包括此轨道中的“引用”及其压缩版本。
-
应预测DMOS轨道,参考剪辑和压缩剪辑之间的差分平均意见得分(DMOS)。
参考原文:
视频质量评价:挑战与机遇
质量评价在视频业务链路中的作用
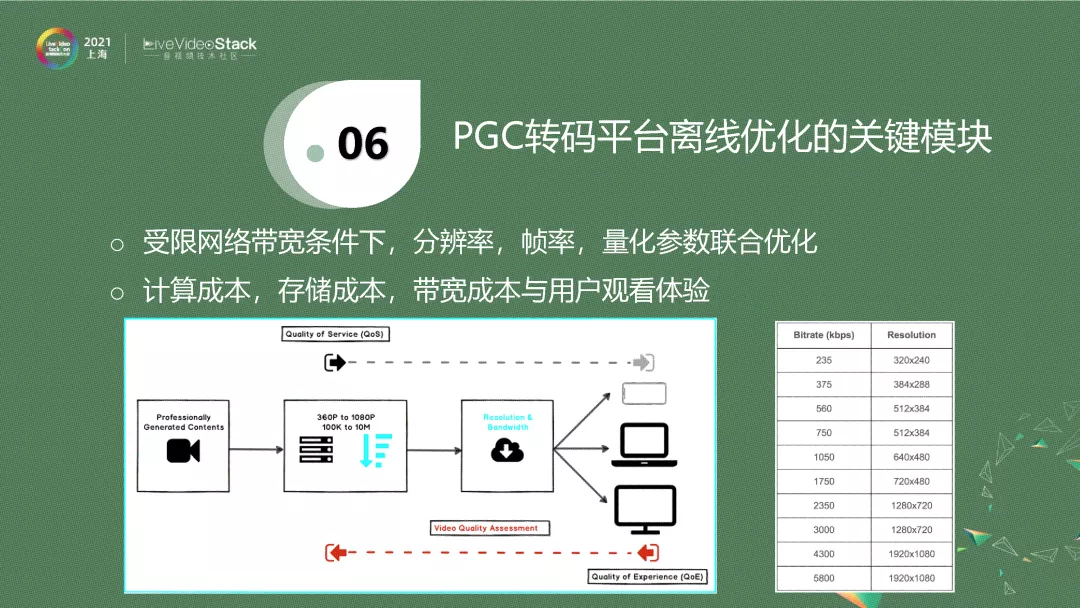
上图是一个简化版的PGC转码平台示意图。对于系统来说,拿到一个原始的、无损的、高分辨率、高帧率的源,一般将其采样成不同的分辨率,每一个分辨率会压缩成特定的码率,这样经过CDN,根据用户端可用带宽,自动选择一个码率,然后分发给用户。
图中右边是给出一个码表,它来自Netflix 2015年的技术帖子,即把一个视频压缩到对应的分辨率后,它的码率就是固定的。当你的可用带宽是200k~6Mb,每个码率点分发的视频分辨率也是固定的,这就是固定码表。这样一个系统是单向的,它根据用户的可用带宽,决定分发什么,而没有考虑到视频的差异性。譬如我刚才播放的视频,需要的码率要高一点。现在一个静止页面,需要的码率低一点。这种固定码给的形式完全忽略了视频本身的特性,没有一个从用户端去feedback的过程。就是说,在受限带宽下,是动态调整分辨率,还是调整帧率,还是调整具体的量化参数,我们需要一个更好的策略来达到我的目标的码率。
对于UGC来说,它的播放量有一个长尾效应,也叫作马太效应、二八效应。它大概类似于一个恐龙的形状,播放量和点击量最高的视频永远只有一小部分,后面有一个比较长的尾巴,这代表了有相当一部分视频其实是没有什么人去看的。如果统计一下,你就会发现,播放量最高的视频永远是内容、质量比较好,比较有趣,画面比较清晰等类似特性。而尾部视频要么拍摄得不好,要么画面很渣,要么趣味性不够。
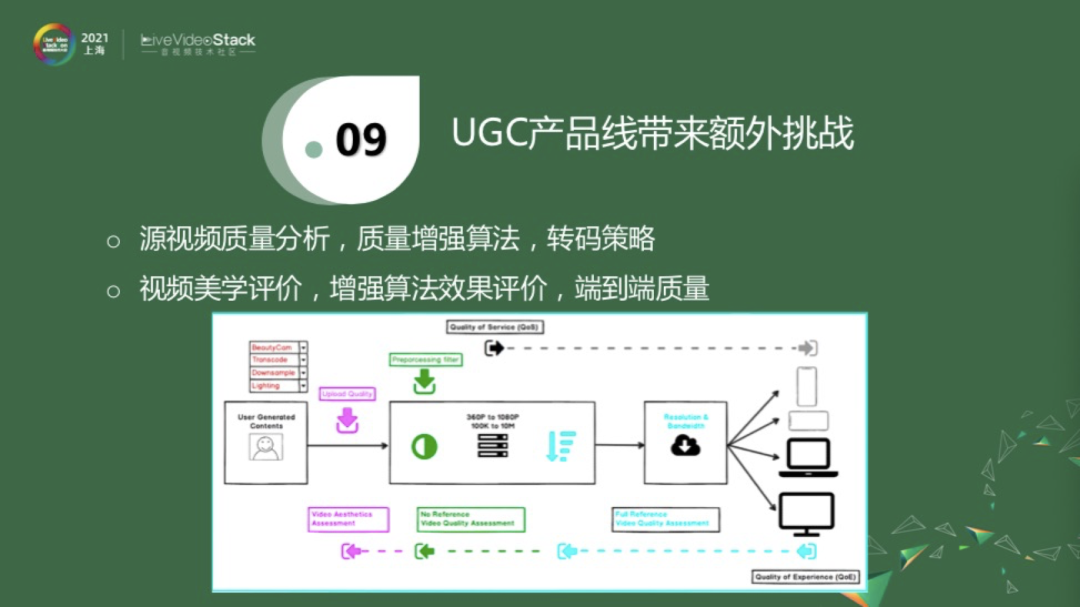
对于UGC视频来说,除了上面介绍的PGC转码平台,即得到一个上传的源进行降分辨率、降帧率的分发之外,还有一些额外的工作可以做。譬如说这是一个UP主或者用户上传的短视频,它可能经过了美颜相机处理。而且目前我们的手机是不支持无损拍摄的,手机自己会压缩一下,否则流量是非常可观的,而且手机会做一些其他的调整。这时候上传的视频质量已经不是无损的。我们在这里需要一个算法来衡量一下,用户上传的视频是不是很好的质量,它是属于头部、中部,还是尾部。如果检测到它是属于头部,那它的推送量就更高一些。如果它是属于脖子这一块,即不是最优质的视频,我们是否可以用一些方法将其增强一下,尽量把它变成头部视频。我可以选择性地加入一些处理手段,来进一步增强它的质量。实际情况往往没那么简单,我们也需要确认一下,这里是不是已经增强了它的质量。处理之后,后面就是一个类似PGC的转码平台。以上的讨论是对于单个模块的。如果我们把这一切串联起来,就是从用户上传到用户接收,当整个系统串联起来的时候,这就是一个比较大的视频质量评价范畴。因为对某一部分,我们有比较好的估计,那串联起来的情况,就可能变得复杂很多了。
质量评价在业界的挑战与机遇

目前来说,视频质量评价在业界经历了十几年的发展,但以我的了解,其实视频质量评价在业界用的还不是特别多。原因也是很客观的,有如下四点。第一是算力成本,因为视频质量评价从技术上来说还是相对比较难的问题。比如会议场景,发送端经过腾讯会议后台转码,然后分发到对面的接收端,我想衡量一下接收的视频质量是否还好。在源端和接收端去做这件事是比较有挑战性的,因为对于用户来说,可能百分之五、百分之十的CPU消耗都是很可观的、甚至是不能接受的一个指标。那么把计算放到转码服务器上进行相对来说会好一点,但是也有一定的问题,比如隐私问题,或者是如果算法过于复杂,后台的压力问题。第二,不同的业务场景具有不同的业务核心指标。如实时会议要求时延不能太高,不能两个人说话的时候,一个人等了好几秒对面才会听到,然后才回复。第三,虽然视频质量评估在学术界汇报的结果会比较高,但真正在业务场景下,各种各样的 bad case都会出现,即如果把一个指标放在线上跑完后就会发现,剩下的工作量可能就是解决各种bad case了。
最后,综合以上,作为领导或者负责人就会衡量一个问题,这么大的投入,对系统改变这么大,这到底能带来多少收益?以上问题,导致了视频质量评价在业界的应用不是很广泛,虽然感兴趣的人有很多。

但是,对于一个视频业务,不管是PGC还是UGC,竞争是比较激烈的。虽然在目前阶段,视频以内容为王,特别是优质内容,当解决了优质内容之后,你和竞品的差异究竟在哪儿,就是你有什么杀手锏,可以让你的视频比竞品更优秀,我们相信这个答案就是极致的用户体验。目前,UGC的视频质量评价在业界的情况是,现有算法较难满足业务需要,因为准确度是很有限的。而且大部分算法是对单个失真类型,而UGC视频是串联了多个失真视频类型,这样综合下来,它的性能比较有限。另外,新的算法大都处于起步阶段,特别是基于深度学习的算法。
04
基于深度学习的视频质量评价算法设计



 浙公网安备 33010602011771号
浙公网安备 33010602011771号