
OO_Unit1_blog
1. 作业分析
1.1 第一次作业
1.1.1 设计思路
第一次作业中,我采用递归下降的方法构建表达式,并且将表达式转换成结构简洁的多项式,最终转化成输出的字符串。考虑到后续迭代开发的需要,本次作业已经实现嵌套的括号调用。
作业中的类主要分为三种: 文本解析类:Parser、Lexer。将控制台输入的文本解析成一段段的数字或者运算符号。 因子类:Expr、Term、Number、X。可由上一类解析后的字符串生成,而它们存在共同的toPoly()方法将自身转化为对应的多项式,因此这四个类继承Factor接口。 多项式类:Power、Polynomial。分别表示幂函数和多项式,可由因子类产生。最终答案要求的多项式可由顶层表达式调用toPoly()方法产生,而Polynomial内添加化简方法、覆写toString()方法,可将表达式多项式转化成最终输出的字符串。
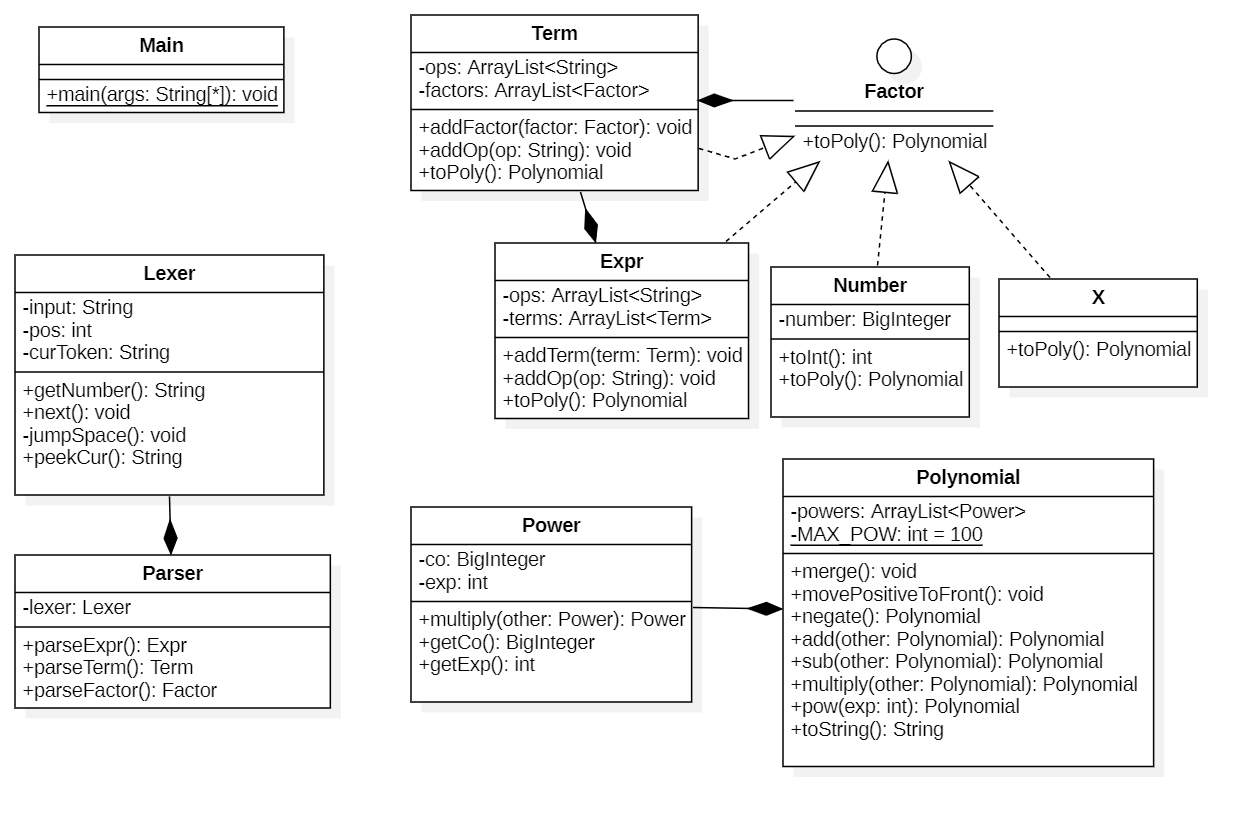
1.1.2 UML类图
本次作业中类的关系如下,其中空心箭头表示接口实现的关系,实心菱形表示类的组成的关系。
1.1.3 类复杂度分析
表头含义如下。
OCavg : Average opearation complexity
OCmax :Maximum operation complexity
WMC :Weighted method complexity
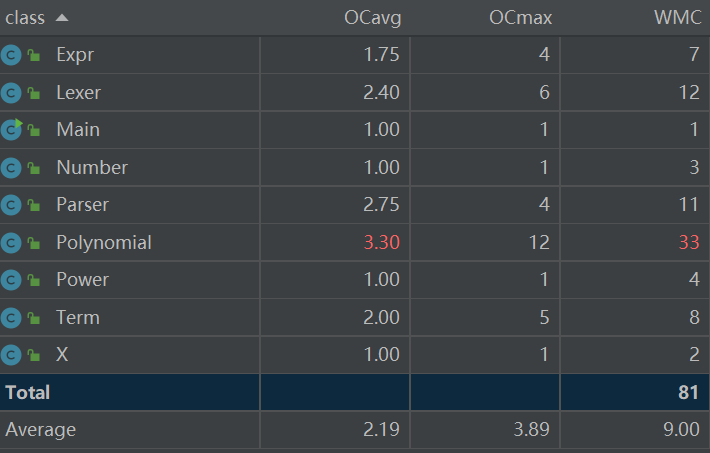
表中Polynomial类的复杂度较高,我认为这是由于该类内部的toString()方法复杂度过高造成的,具体原因和改进策略见下一部分方法复杂度的分析。
1.1.4 方法复杂度分析
表头含义如下。
CogC : Cognitive complexity
ev(G) : Essential cyclomatic complexity
iv(G) : Design complexity
v(G) : cyclonmatic complexity
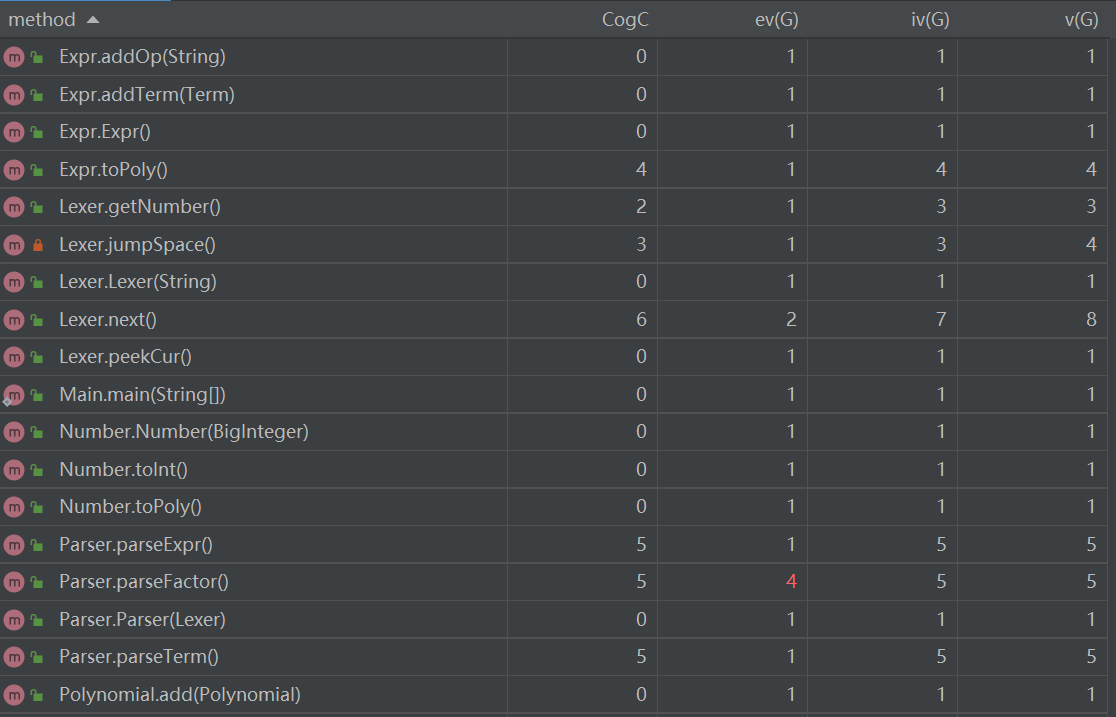
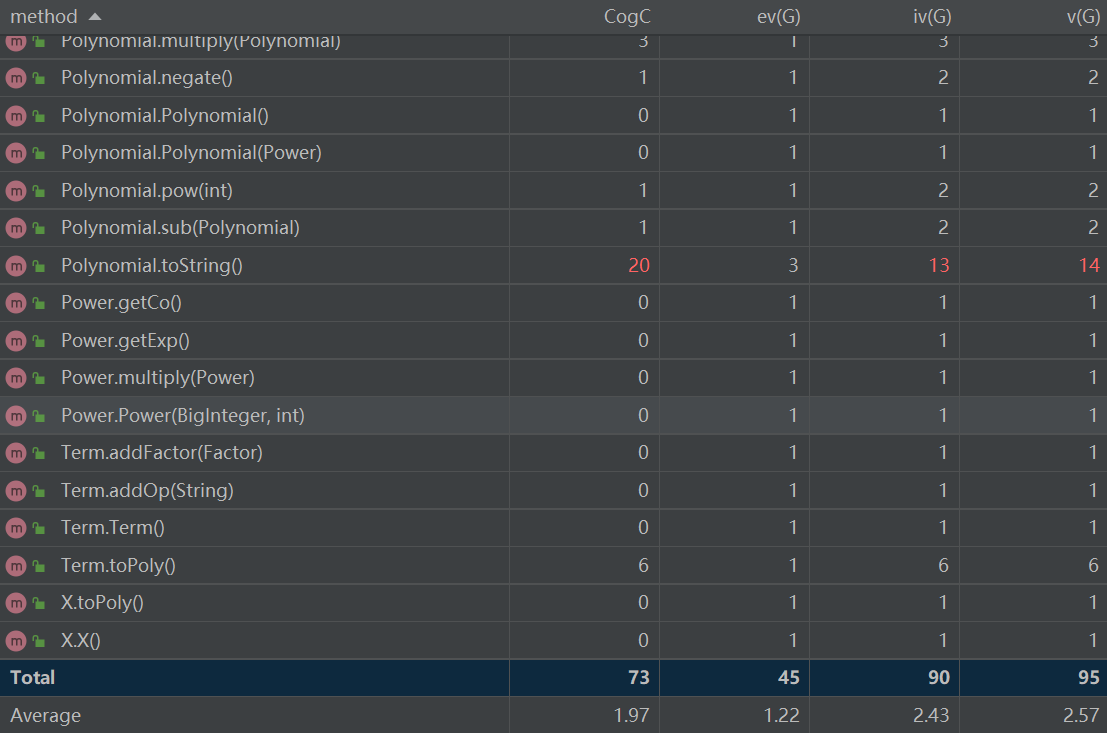
可以看到Polynomial类的toString()的方法复杂度远远高于其它方法,算上注释这段代码有40行。我认为这是我将整个题目的字符串输出代码全部放入Polynomial类中的这一方法所导致的,编程风格较面向过程。因此后续我在Power类中也覆写toString()方法,于是我在Polynomial类覆写toString()时,大段的代码可以由一行Power中的toString()方法替换,更具面向对象的风格。
1.1.5 细节处理与技巧
-
返回结果为0时需要特判,否则会输出空串。
-
x*x比x**2更短。 -
a**b转化成
1*a*..(b个a)..*a,这样不需要特判0次方。 -
可以调整项的顺序,将不带负号的项提到表达式开头,可以提高性能。
-
符号处理时,将符号分为三个优先级进行匹配:项之间的运算的加减号/表达式开头的正负号,项之前的正负号,有符号整数携带的正负号。并且在没有匹配到符号时,将符号默认为为正号。 这样既能保证加减运算可以正确进行,而且由于最多连续出现三次
+/-、因此这样能保证出现的每一个+/-都能被正确匹配。 例如--1,按照如上匹配原则,第一个-为项-1之前的符号,第二个-为因子1之前的符号,由于不存在第三个+/-,因此有符号数1符号默认为正。
1.2 第二次作业
1.2.1 设计思路
第二次作业允许括号嵌套的数据,第一次作业的架构已经实现。此外还增加了三角函数、自定义函数和求和函数,因此第二次作业主要实现这三方面的功能。
三角函数:本次作业需要实现三角函数运算,因此添加了Cos、Sin两个类分别代表余弦函数和正先函数,并实现Factor接口。而Sin和Cos又有许多共同的方法,因此我构造了它们的共同父类Tri减少代码量,并且后续的迭代中无需在Sin类和Cos类中重复更改,减少工作量。 此外我将第一次作业中的Power类和Polynomial类做了修改,名字更新为MixPower和MixPoly,而在MixPower类字段中ArrayList<Sin>和ArrayList<Cos>两个列表储存三角函数因子,并对加、减、乘、合并等方法进行修改,以支持带三角函数基本运算。
自定义函数:本次作业中构造了Functions类储存声明的自定义函数。在利用Parser类解析自定义函数时,解析目标函数在Functions类中储存的字符串,并且在遇到形式参数时使用实际参数生成的表达式因子替换。采用此种策略即可在解析字符串时解决自定义函数调用的问题。
求和函数:思路与自定义函数类似:将求和函数表达式看成关于i的一元函数,将i在循环中的值看作实际参数,参照自定义函数中的方法进行表达式替换即可。
由于采用表达式替换的方法,并且在字符串解析时实现了实参形参对应关系的向下传递,第二次作业完成时已经可以实现自定义函数的嵌套调用和求和函数的嵌套调用。
1.2.2 UML类图
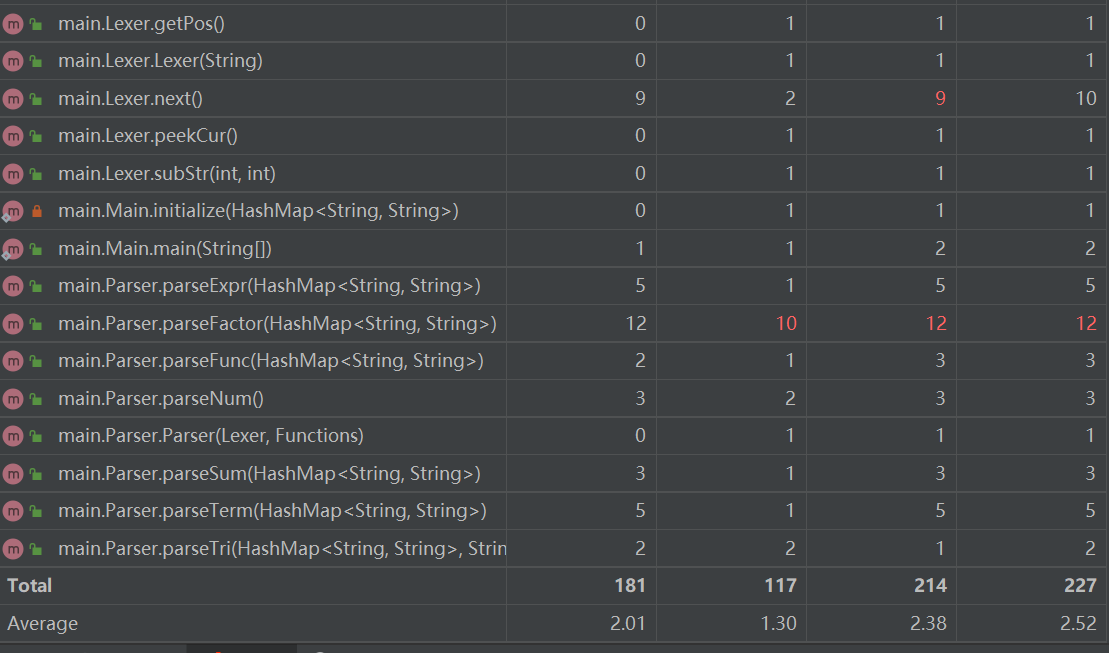
本次作业由于继承因子的类较多,因此将这些类统一放入expr的包中。expr包的关系如下,其中实线空心箭头表示接口实现的关系,虚线空心箭头表示类的继承的关系,实心菱形表示类的组成的关系。
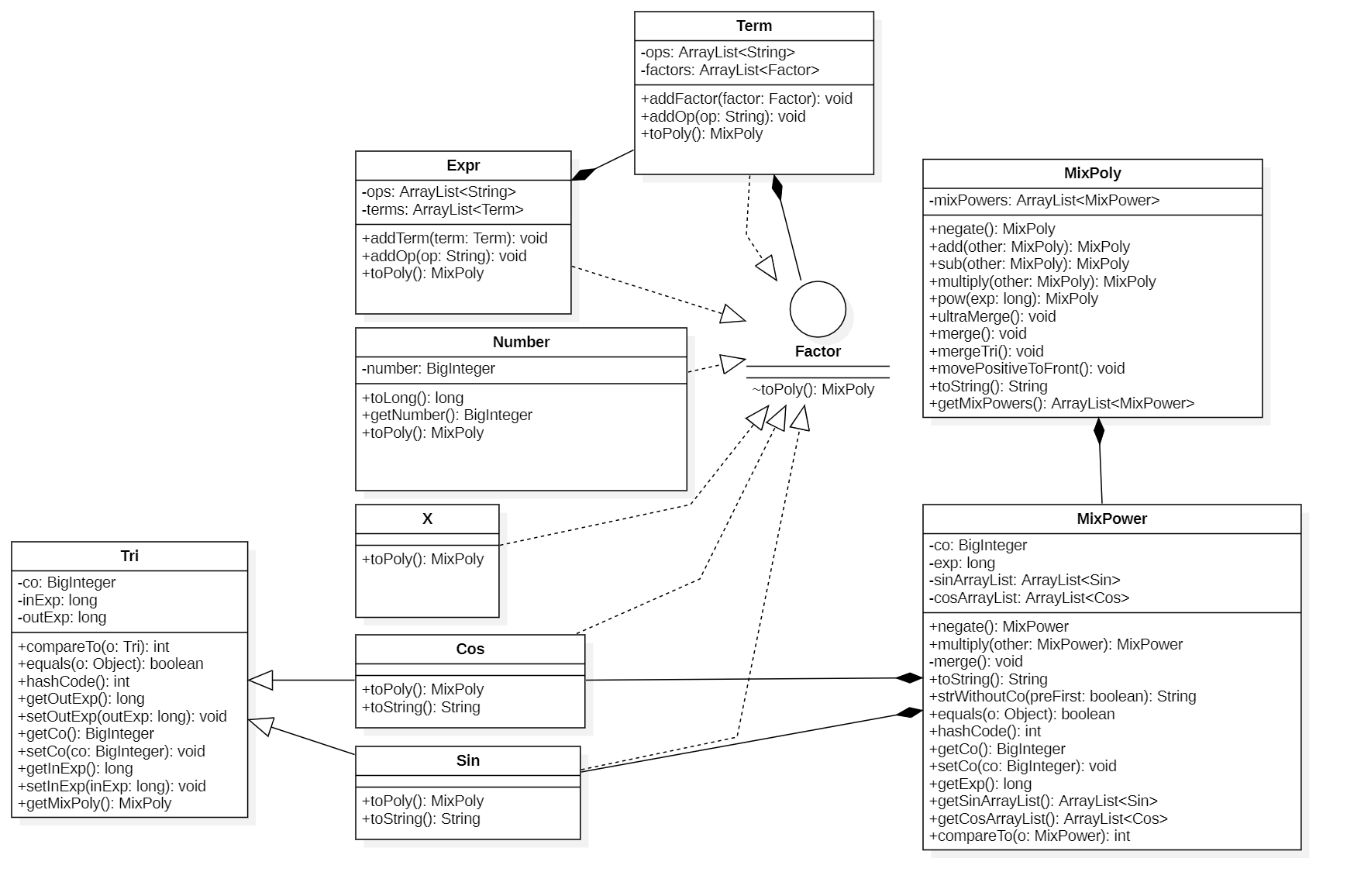
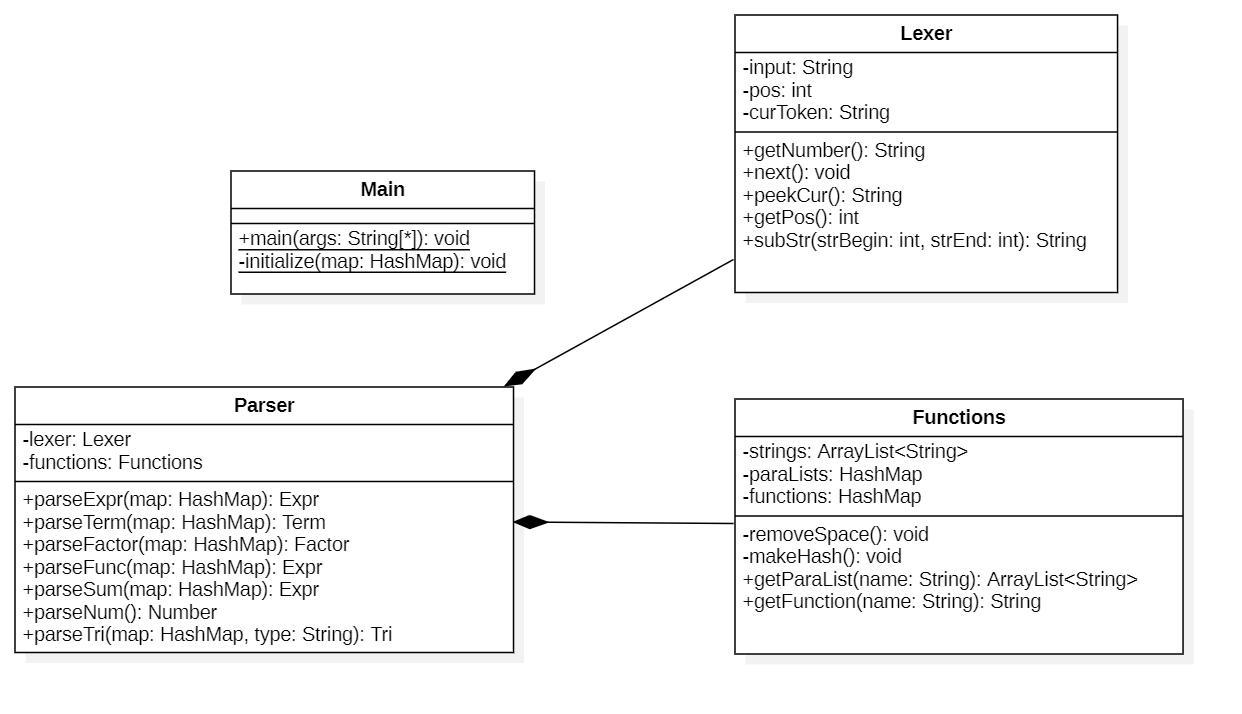
主函数包的类关系图如下,相比第一次添加了Functions类。而在Parser解析器中也增加了转化自定义函数、三角函数、求和函数的方法。
1.2.3 类复杂度分析
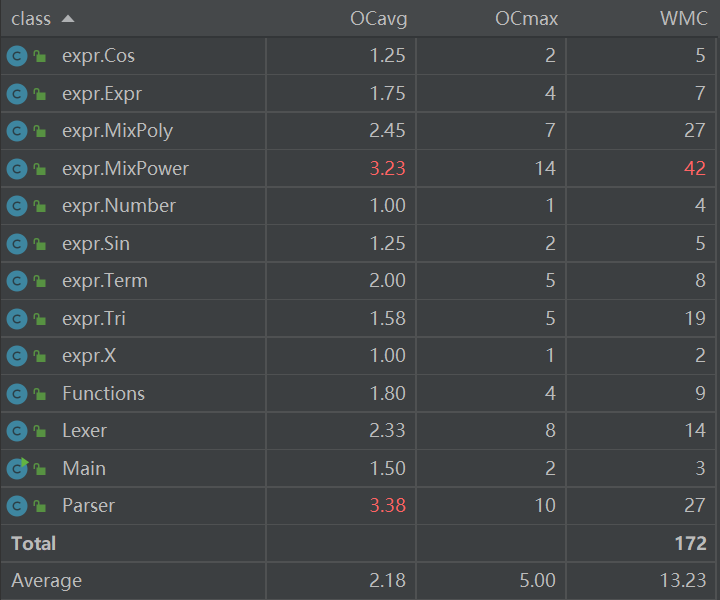
由于Parser需要多返回三种复杂的因子类,因此复杂度有所提高。
1.2.4 方法复杂度分析
由于本次作业方法较多,故在此处只放置复杂度较高的方法。
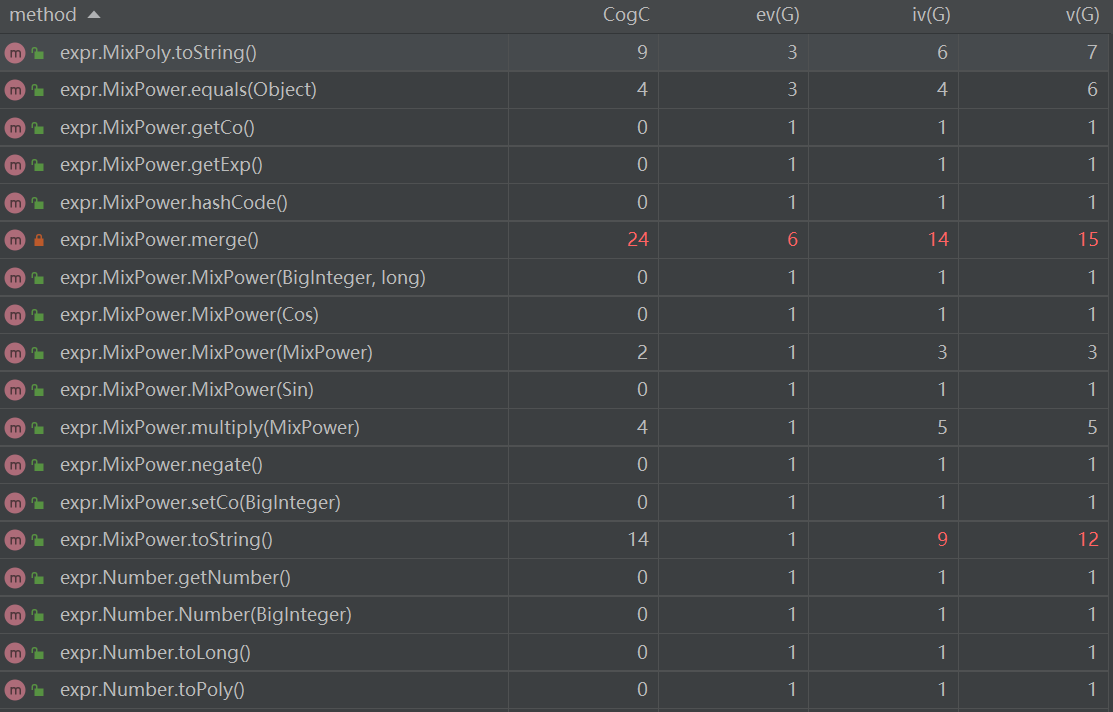
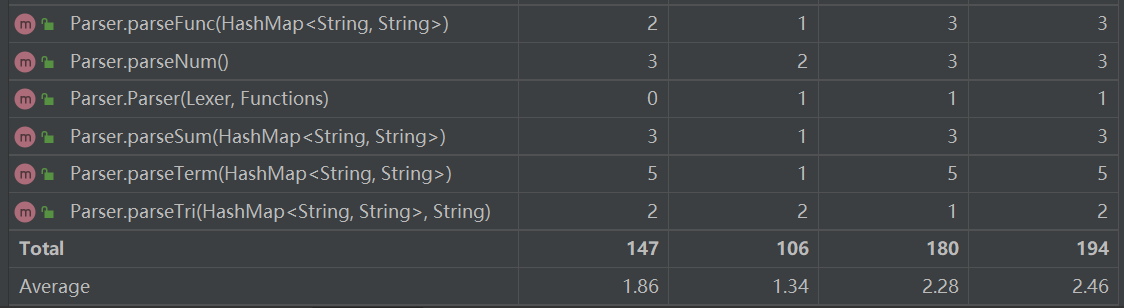
在经过toString()方法的递归改进后,该方法的复杂度较第一次相比降低不少。但是由于三角函数的引进,对带三角函数的幂函数项中进行化简过程变得复杂许多,因此MixPower类中的merge()函数复杂度较高。 其实这里可以拆成去负号、三角函数边界值转化、同类三角函数合并等几步,每一步调用一个函数执行,更好地进行封装,无奈本人比较懒,这个问题留到第三次中测过了之后就没管它了TAT。
1.2.5 细节及处理技巧
-
最基础的化简,
sin(0)=0,cos(0)=1。 -
将所有三角函数内部的幂函数化为正数,注意负号提取到三角函数之外的条件。
-
采用ArrayList<>数据结构储存三角幂函数中的三角函数因子,对三角函数定义排序关系。化简时继承Comparable接口对列表排序,可以将可合并的因子排序到一起,方便合并。
-
需要对类进行深度克隆时,可以从底层递归定义构造自身的构造方法:
//拷贝Sin时
public Sin(Sin sin) {
this.co = sin.co;
this.inExp = sin.inExp;
this.outExp = sin.outExp;
this.mixPoly = new MixPoly(sin.mixPoly);
}
//拷贝包含Sin类的MixPower类时
public MixPower(MixPower mixPower) {
this.sinArrayList = new ArrayList<>();
for (Sin sin : mixPower.sinArrayList) {
this.sinArrayList.add(new Sin(sin));
}
}
1.3 第三次作业
1.3.1 设计思路
第三次作业的功能大部分已经在第二次作业实现了,只需对三角函数内部做一些小修改。
由于三角函数内部可以任何表达式,为了实现合并,需要实现对等价表达式的归一化简。因此我实现了三角幂函数的排序和三角函数之间的比较。
具体实现时,三角函数内部不再存储幂函数的系数和指数,而是存储内部表达式因子化简的字符串和该因子取负时所对应的最简字符串,将诸如sin(x+1)、sin(1+x)、sin(-1-x)这些三角函数统一化简成系数*sin(1+x)的形式,再进行化简。
此外由于三角函数括号内输出的正确性判定有括号的要求,只需修改三角函数内toString()方法,即可保证正确性。
1.3.2 UML类图
由于只有三角函数方面的变动,expr的类图与第二次作业相比只有Tri类中的字段和方法发生了变化。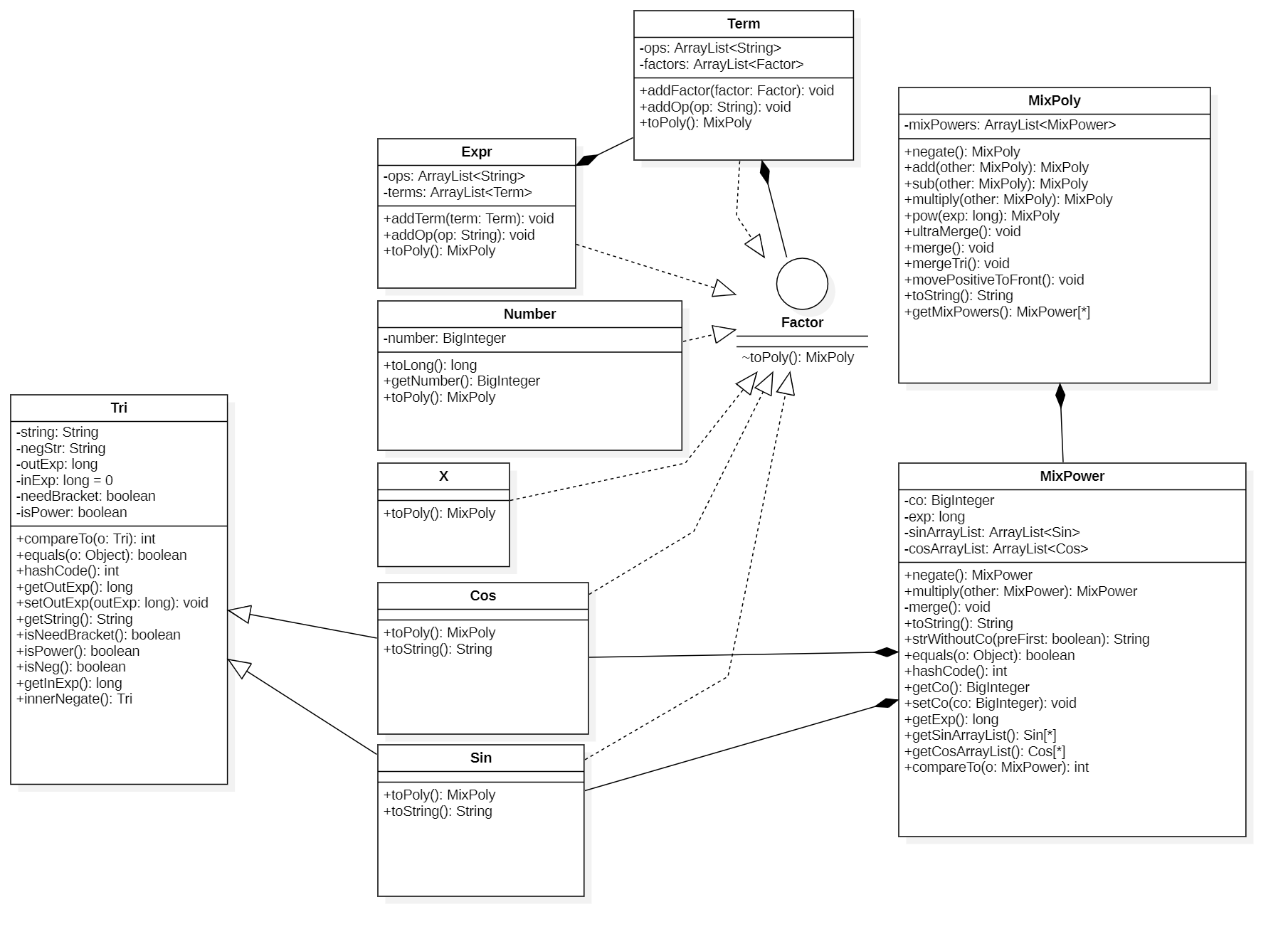
而main包的类图并没有任何改变,就不在此展示了~
1.3.3 类复杂度分析
由于第三次作业中对MixPoly类中toString()方法进行了进一步的分解,因此该类的复杂度降低到了3以下。

1.3.4 方法复杂度分析
即使第三次三角函数内部的表达式更复杂,但是由于将三角幂函数类的toString()的方法进行了分解,因此它的复杂度没有变得太高。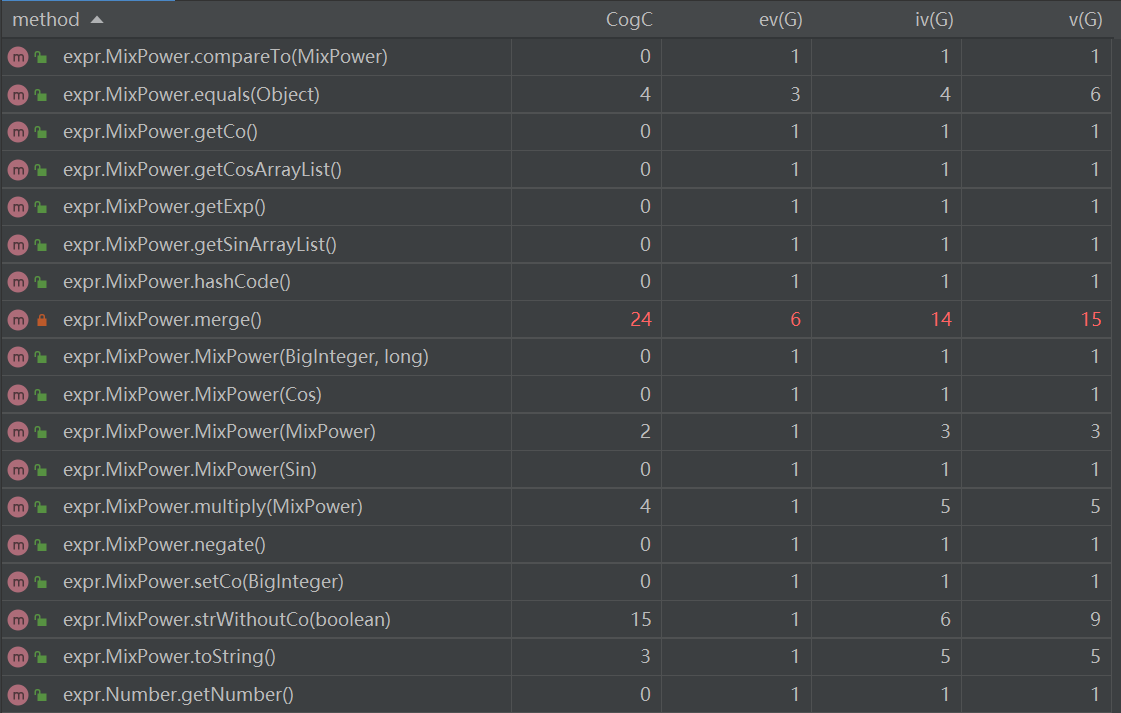
1.3.5 细节及处理技巧
这次作业我在三角函数内部的取负使用了小技巧。 我在三角函数中存储了内部表达式化简后的字符串,其中string表示原字符串,negStr表示表达式取负后的字符串,两者均在初始化时赋值。 取负时,只需要利用构造方法,将字符串与取负后的字符串换位,即可高效地进行取负操作,而无需再对表达式进行解析。 代码如下:
//构造方法
public Sin(String string, String negStr, long outExp, long inExp,
boolean needBracket, boolean isPower) {
this.string = string; //字符串
this.negStr = negStr; //取负后的字符串
this.outExp = outExp;
this.inExp = inExp;
this.needBracket = needBracket;
this.isPower = isPower;
}
//取负函数
public Sin innerNegate() {
return new Sin(negStr, string, outExp, inExp, needBracket, isPower);
}
此外对于一个复杂的表达式,按照常规方法深度克隆时需要进行递归操作,十分不便。因此我在对表达式进行深度克隆时(如sum中关于i的求和表达式需要克隆多次),可以将表达式字符串提取进行多次调用Lexer和Parser类中的方法进行解析,以此可以得到多个完全相同,但互不干扰的表达式。
2. BUG分析
2.1 别人找到的bugs
三次作业中强测都没有出现bug。
而互测在第三次时,由于sum的开始和结束的循环下标设置得只能在int范围,因此如果出现超过int的开始下标和结束下标,结果就会出错。因此第三次互测时因为这个bug被hack了8次,成为了我们房间的经验包TAT。
2.2 自己找到的bugs
此外每次作业刚写完时会有一些粗心的bug,在此列举:
第一次作业:
-
toString时乘号打印的条件出错。
-
在读取因子之后忘记调用Lexer中的next()函数。
-
多项式取负时忘记对系数去负号。
第二次作业:
-
sin内部提取负号到外部时,忘记考虑偶次幂的情况。
-
for循环的bug:
for (Cos cos : cosArrayList) {
if(/*condition*/){
cosArrayList.remove(cos);
}
}如果像上面的语句块一样进行元素的移除,会出现跳过元素的bug。
因此可以这样更改,以移除列表中满足特定条件的元素。
for (int i = 0; i < cosArrayList.size(); ) {
if(/*condition*/){
cosArrayList.remove(i);
}else{
i++;
}
}
第三次作业:
-
第三次作业对于系数为-1的幂函数和三角函数,虽然系数最后会转换为1去掉,但是去括号标记没有传导到取负后的三角函数,因此会导致部分三角函数的括号没有去掉。
-
第三次作业有做将非负项移动到开头的优化,但是一开始将每一层三角函数内的表达式都优化,但是这和取负化简的操作会冲突,将导致等价表达式化简成不同的字符串。解决方案:仅在顶层的表达式做将非负项移动到开头的优化,即可将表达式化简到最短,又可以保证正确性。
3. HACK策略
互测时主要抱着学习的心态,并没有花太多时间构造复杂的数据,每次只砍中了一刀就润了。
第一次作业中我尝试了0数据和带前导零的数据进行hack,最终成功的数据是(x+1)**00。第二次作业主要是对三角函数负号提取入手,尝试-(sin(-1)**2)hack成功。最后一次互测加入了sum函数,互测开始到一半想到了爆int的问题(结果发现房间里就我自己有这个bug QAQ),后来尝试了带三角函数负数的sum循环,最终使用sum(i,-1,2,sin((i*x))**2)hack成功。
此外每次互测时将此前互测房间成功hack到别人的数据测一遍,有较大概率找到此前作业遗留的bug。
4. 架构设计体验
4.1 赞美ArrayList
这三次作业最大的体验就是ArrayList永远地神!!相较于HashMap,ArrayList的遍历多一种使用下标的方法,可以些for循环一次性删除多个满足某种特性的元素。此外ArrayList还可以通过对元素的类继承Comparable接口,方便地使用库函数的排序方法!!最后ArrayList在库函数直接覆写了内部的equals方法,直接可以进行整个数组的比较。因此三次作业中能使用ArrayList的我都使用了ArrayList,尝尽了甜头。 不过这也可能我是对HashMap底层实现理解不够,还得向大家的博客多多学习。
4.2 迭代开发有感
4.3 三角函数反思
此外虽然我三次强测都通过了,但是关于自己的架构还是有反思的地方。其中关于三角函数,我构造了Sin、Cos、Tri三个类,其中Tri定义、实现三角函数共同的字段、方法,而Sin和Cos继承Tri,分别实现正弦和余弦函数各自的方法。后来想到Sin和Cos唯一的区别就是输出字符串时是输出sin还是cos,其实完全可以在Tri中添加一个boolean的字段来表示它是正弦函数还是余弦函数,就不需要定义Cos和Sin两个类,使得expr包简洁许多。
5.结语
这第一个月来的作业真的不容易,一些思想和细节处理也是从与同学的交流和讨论区的帖子学习的。不过上OO课真的跟上学期java课中瞎子摸黑走路感受很不一样,三次作业让我对面向对象编程的迭代开发思想和有了十分初步的认识,希望我能在接下来的学习中能对java的理解更上一层楼!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号