软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 设计、开发一个疫情统计的程序;学习GitHub的使用 |
| 作业正文 | 作业正文 |
| 其他参考文献 | CSDN,附录教程,博客园,知乎,百度 |
Github仓库地址
https://github.com/fzuckl/221701308
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 70 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 540 | 645 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 200 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 15 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 45 | 60 |
| Coding | 具体编码 | 300 | 330 |
| Code Review | 代码复审 | 20 | 25 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 0 |
| Reporting | 报告 | 60 | 75 |
| Test Report | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 10 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| total | 合计 | 1505 | 1525 |
解题思路
对照作业要求,得知list命令需支持以下行参数:-log、-out、-date、-type、-province;需要处理的数据分为“<省> 新增 感染患者 n人”、“<省> 新增 疑似患者 n人”、“<省1> 感染患者 流入 <省2> n人”、“<省1> 疑似患者 流入 <省2> n人”、“<省> 死亡 n人”、“<省> 治愈 n人”、“<省> 疑似患者 确诊感染 n人”、“<省> 排除 疑似患者 n人”;最后的输出格式为“<省/全国> 感染患者a人 疑似患者b人 治愈c人 死亡d人”。
所以需要设置变量log、out、date,即字符串数组typ、pro处理行参数,二维数组Pro存储各省及全国四种患者人数(0为全国,接下来各省按首字母排序,应用函数进行初始化);设计函数分别处理main函数参数、文档读取、写入文档,负责写入文档的函数必须按负责处理main函数参数的函数所得结果进行分情况处理。
设计实现过程
-
大致流程
初始化变量→进行命令行参数处理dealARGS()→outpTo()检查目标输出文件是否存在(不存在则创建一个)→遍历log内文件并通过rTxt()对文件数据进行处理→outpTo()寻找-province要求的省份→out()根据-type输出内容
-
代码组织
命令行参数处理:
public static void dealARGS(String[] args);
文件处理函数:
public static void rTxt(String path);
public static void outpTo(String path);
输出函数:
public static void out(BufferedWriter buffO,int proN)
-
关键函数流程图
关键代码说明
命令行处理
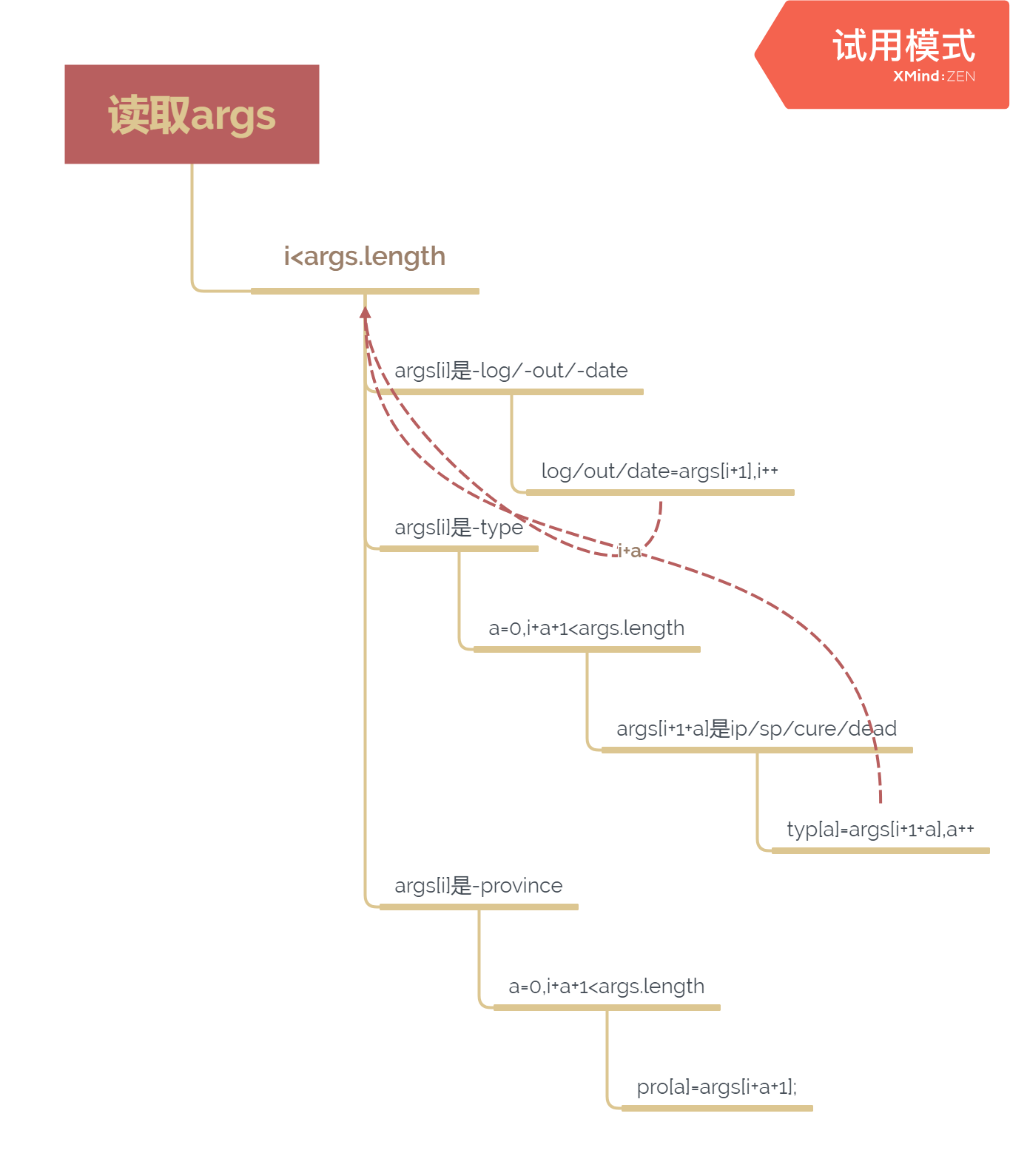
依次读取传入的参数,与log、out等关键字比对,符合则取其后字符为相应变量赋值;对于type后的字符,还需与ip、sp等依次比对;按序输入,province应为最后一个参数,将其后的全部字符赋值给字符串数组pro存储
for(int i=0;i<args.length;i++){
if(args[i].compareTo("-log")==0){
log=args[i+1];
i++;
}
else if(args[i].compareTo("-out")==0){
out=args[i+1];
i++;
}
else if(args[i].compareTo("-date")==0){
date=args[i+1];
i++;
}
else if(args[i].compareTo("-type")==0){
for(int a=0;(i+1+a)<args.length;){
if((args[i+1+a].compareTo("ip")==0)||(args[i+1+a].compareTo("sp")==0)||
(args[i+1+a].compareTo("cure")==0)||(args[i+1+a].compareTo("dead")==0)){
typ[a]=args[i+1+a];
a++;
if((i+2+a)<args.length){
continue;
}
else{
i+=a;
break;
}
}
else{
i+=a;
break;
}
}
}
else if(args[i].compareTo("-province")==0){
for(int a=0;a<Pro.length;a++){
if((i+1+a)<args.length){
if(args[i+1+a].length()!=0){
String b=args[i+1+a];
pro[a]=b;
}
}
}
}
}
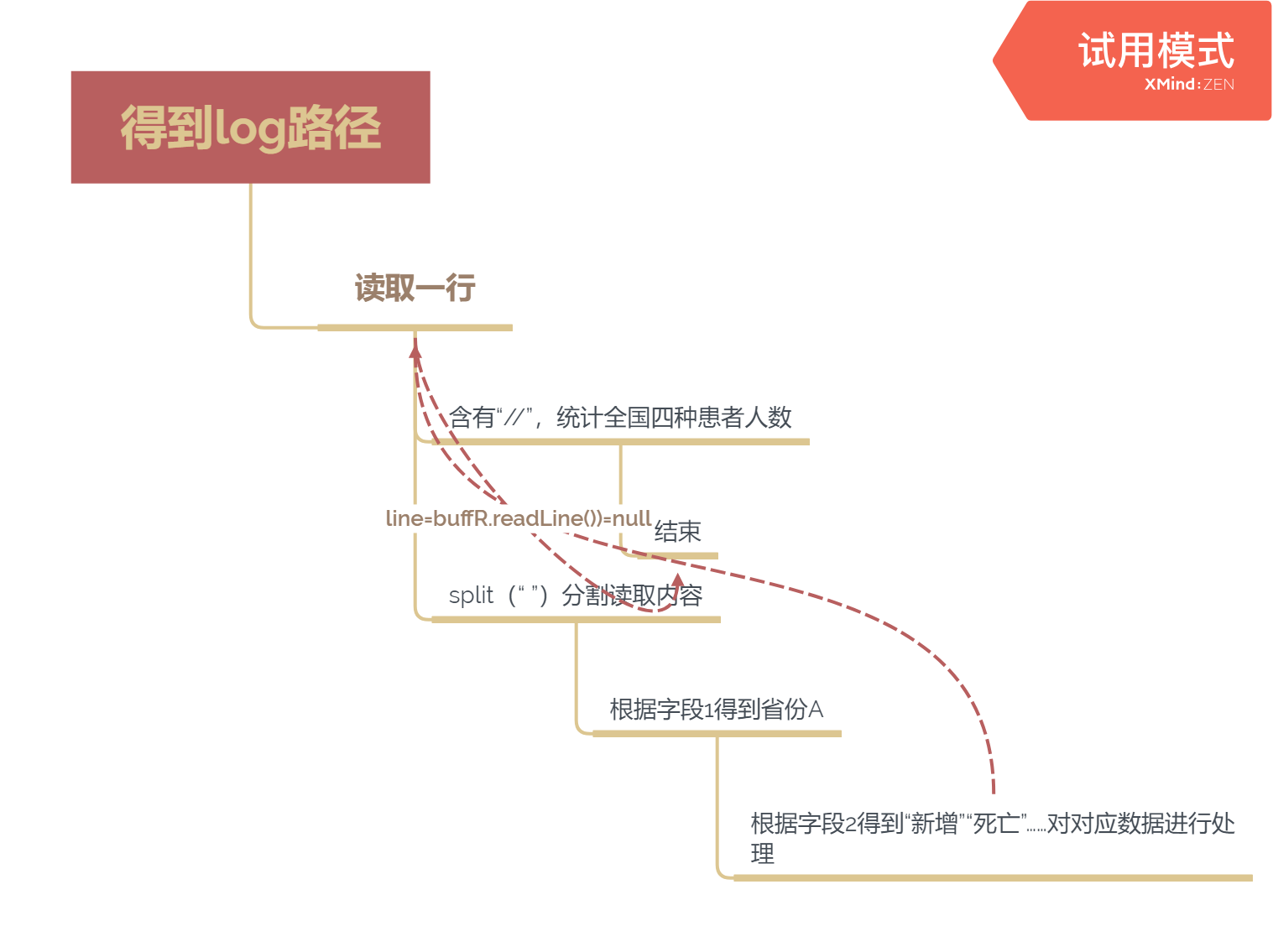
读取文档
“//”标记注释,即文档结尾,先判断;应用split将整行分割为字符串数组,根据文档中可能句式“<省> 新增 感染患者 n人”、“<省> 新增 疑似患者 n人”、“<省1> 感染患者 流入 <省2> n人”、“<省1> 疑似患者 流入 <省2> n人”、“<省> 死亡 n人”、“<省> 治愈 n人”、“<省> 疑似患者 确诊感染 n人”、“<省> 排除 疑似患者 n人”判断数据类型,并进行处理
while((line=buffR.readLine())!=null){ //读取文档并处理文档内数据
if(line.contains("//")){ //文档结尾,统计全国感染、疑似、治愈、死亡人数
for(int i=1;i<Pro.length;i++){
for(int j=0;j<4;j++){
humC[0][j]+=humC[i][j];
}
}
break;
}
String[] s=line.split(" ");//分割读进来的字符串
for(int i=1;i<Pro.length;i++){
if((s[0].compareTo(Pro[i]))==0){ //识别省份名称
if(s[1].compareTo("新增")==0){
if(s[2].compareTo("感染患者")==0){
humC[i][0]+=Integer.parseInt(s[3].substring(0,s[3].length()-1));
}
else if(s[2].compareTo("疑似患者")==0){
humC[i][1]+=Integer.parseInt(s[3].substring(0,s[3].length()-1));
}
}
else if(s[1].compareTo("死亡")==0){
humC[i][3]+=Integer.parseInt(s[2].substring(0,s[2].length()-1));
humC[i][0]-=Integer.parseInt(s[2].substring(0,s[2].length()-1));
}
else if(s[1].compareTo("治愈")==0){
humC[i][2]+=Integer.parseInt(s[2].substring(0,s[2].length()-1));
humC[i][0]-=Integer.parseInt(s[2].substring(0,s[2].length()-1));
}
else if(s[1].compareTo("排除")==0){
humC[i][1]-=Integer.parseInt(s[3].substring(0,s[3].length()-1));
}
else if(s[1].compareTo("疑似患者")==0){
if(s[2].compareTo("流入")==0){
for(int j=0;j<Pro.length;j++){
if(s[3].compareTo(Pro[j])==0){
humC[i][1]-=Integer.parseInt(s[4].substring(0,s[4].length()-1));
humC[j][1]+=Integer.parseInt(s[4].substring(0,s[4].length()-1));
}
}
}
else if(s[2].compareTo("确诊感染")==0){
humC[i][1]-=Integer.parseInt(s[3].substring(0,s[3].length()-1));
humC[i][0]+=Integer.parseInt(s[3].substring(0,s[3].length()-1));
}
}
else if(s[1].compareTo("感染患者")==0){
if(s[2].compareTo("流入")==0){
for(int j=0;j<Pro.length;j++){
if(s[3].compareTo(Pro[j])==0){
humC[i][0]-=Integer.parseInt(s[4].substring(0,s[4].length()-1));
humC[j][0]+=Integer.parseInt(s[4].substring(0,s[4].length()-1));
}
}
}
}
}
}
}
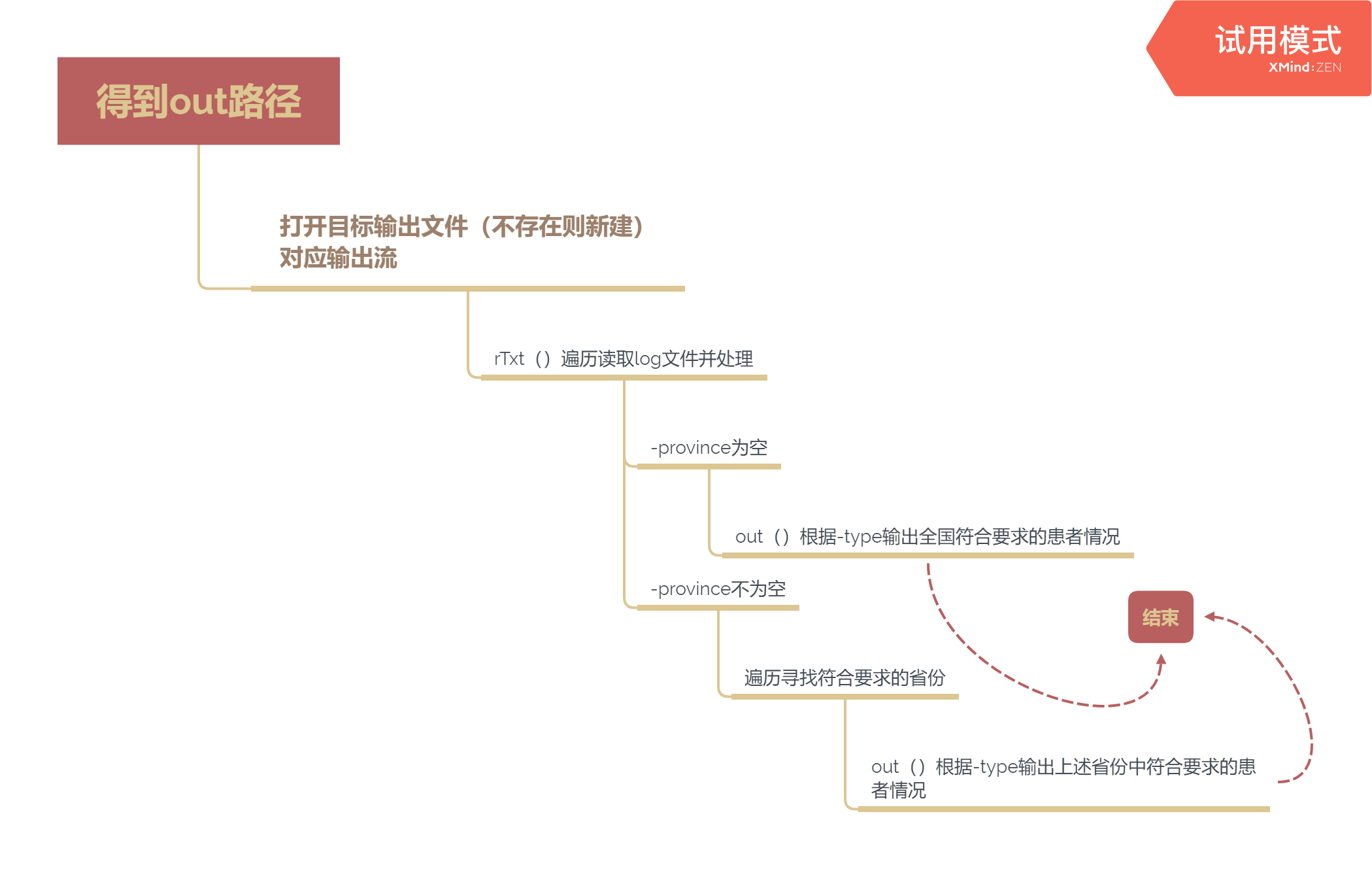
文档输出
判断-province
province未输入时默认仅显示全国疫情,根据对province处理得到的字符串数组pro判断符合要求的省份
if(pro[0]==null){ //没有输入任何省份只输出全国
buffO.write(Pro[0]+" ");
out(buffO,0);
buffO.newLine();//换行
}
else{
for(int i=0;i<pro.length;i++){
int proN;
for(int j=0;j<Pro.length;j++){
if(pro[i]==Pro[j]){ //寻找对应省份
buffO.write(Pro[j]+" ");
proN=j;
out(buffO,proN);
buffO.newLine();
}
}
}
}
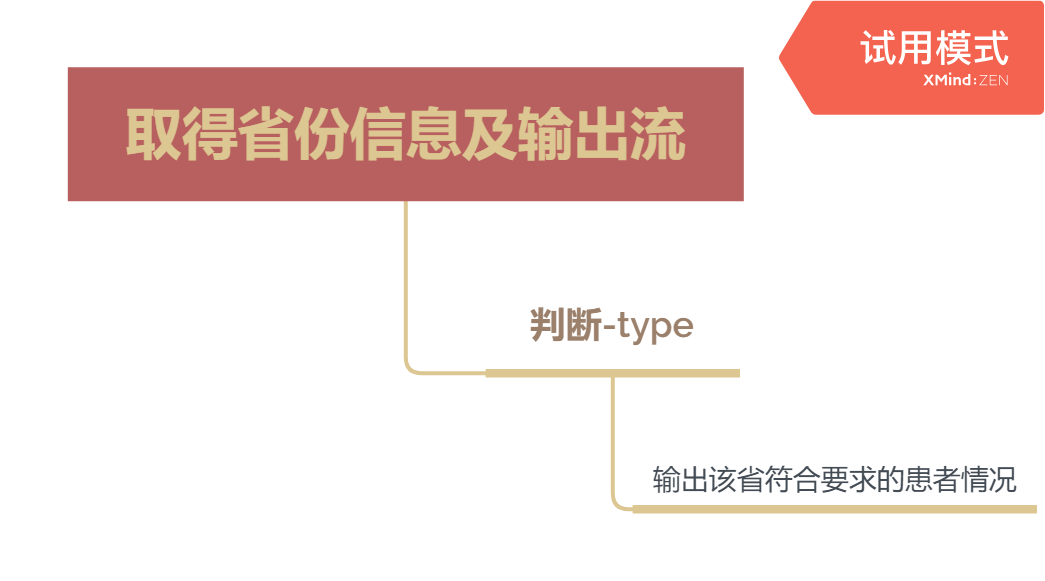
判断-type
type未输入时默认显示所有患者状况,根据对-type处理得到的字符串数组typ判断符合要求的患者类别
if(type[0]!=null){
for(int i=0;i<typ.length;i++){
if(typ[i]=="ip"){
String a="感染患者"+humC[proN][0]+"人 ";
buffO.write(a);
}
else if(typ[i]=="sp"){
String a="疑似患者"+humC[proN][1]+"人 ";
buffO.write(a);
}
else if(typ[i]=="cure"){
String a="治愈"+humC[proN][2]+"人 ";
buffO.write(a);
}
else if(typ[i]=="dead"){
String a="死亡"+humC[proN][3]+"人 ";
buffO.write(a);
}
}
}
else{
String a="感染患者"+humC[proN][0]+"人 "+
"疑似患者"+humC[proN][1]+"人 "+
"治愈"+humC[proN][2]+"人 "+
"死亡"+humC[proN][3]+"人";
buffO.write(a);
}
单元测试截图和描述
单元测试覆盖率优化和性能测试
-
覆盖率测试
-
性能测试
代码规范
https://github.com/fzuckl/221701308/blob/master/codestyle.md
心路历程和收获
在本次的程序开发中,学习了GitHub的基础用法,明白了程序开发的大致流程,本次作业的困难主要在于对新工具的不适应以及熟练应用的困难,还有对带命令行参数的程序的不熟悉,这使我明白了学习的不可间断,我相信本次作业积累的经验会有助于我以后更好的完成相关课程作业。
另由于估计过于乐观、对自身能力未能准确认识、还沉浸在寒假的放松中未及时调整,本次作业部分未能及时完成,我一定知错就改!!!
学习路线相关五个仓库
https://github.com/CyC2018/CS-Notes
技术面试的一些知识总结
https://github.com/bzzd2333/JavaGuide
提供了JAVA的学习路线及知识点和面试技巧的总结
https://github.com/ZXZxin/ZXBlog
各种基础学习资料
https://github.com/qianguyihao/Web
适用于Web初学者
https://github.com/jobbole/awesome-python-cn
Phython资源大全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号