Kubernetes(二):编排介绍
一、Kubernetes简介
Kubernetes是Google于2014年开源的一个容器编排工具,使用Google自己的go语言编写,由Borg衍生而来。Borg是Google内部已经运行近十年的容器编排工具,由于docker的横空出世,导致Google原本准备作为秘密武器的容器技术胎死腹中。计划被打乱,容器层面已经痛失良机,慢人一步,只有在编排工具层面下手了,Google当机立断,基于Brog的逻辑编写了Kubernetes,开源并捐给了CNCF(云远程计算基金会),由于Google近十年的使用经验,所以Kubernetes一出世就横扫了其它编排工具,时至今日,地位依然稳固。
Kubernetes源于希腊语,有“舵”或“飞行员”的意思。k8s,是由Kubernetes中间的八个字母缩写为数字8得来的。Google采用这个名字的深意就是:既然你docker把自己定位成驮着集装箱在大海上遨游的鲸鱼,那么我就以Kubernetes掌舵大航海时代的话语权,鲸鱼必须按照我设定的路线巡游。
Kubernetes的一大亮点就是自动化,在Kubernetes的解决方案中,一个服务可以自我扩展、自我诊断,并且容易升级,在收到服务扩容的请求后,Kubernetes会触发调度流程,最终在选定的目标节点上启动相应数量的服务实例副本,这些实例在启动成功后会自动加入负载均衡器中并生效,Kubernetes会定时巡查每个服务的所有实例的可用性,确保服务实例的数量与预期的数量一致,当它发现某个实例不可用时,会自动重启或在其它节点上重建该实例,整个过程无需额外的人工操作。 ——来自《Kubernetes权威指南》

二、Kubernetes对象
k8s的api是一种RESTful风格的API,在这种设计风格下,数据也好、服务也罢,一切都可以称之为资源(resources)。在k8s中将这些资源实例化后称之为对象。比如Pod在没有使用之前就是一个抽象的概念,可以称之为资源,你指定为Pod创建了容器之后,就可以称之为对象。
基础对象
-
Pod:
-
k8s最小部署单元是Pod,一个Pod可以包含一个或多个容器。
-
每个Pod都会被分配一个集群内专用的IP地址,成为Pod IP,同一Pod内部的所有容器共享Pod对象的Network、IPC、UTS名称空间(主机名、网络设备、网络协议等),因此这些容器可以通过本地回环接口lo进行通信,而与Pod外的其它组件通信需要借助Service的Cluster IP机器相应的端口完成。此外,还可以通过共享存储卷(Volume)来完成同一Pod内容器的数据共享,利用持久化存储能保证容器被修改或者被删除后数据不丢失。
-
一个Pod对象代表一个应用程序的特定实例,如果需要扩展应用程序,比如需要多台做负载或者高可用,那就意味着要为这个应用程序创建多个Pod实例,也就是需要多个副本,这时候就需要借助控制器(Controller)实现,例如deployment控制器对象,这个后面有介绍。
-
Pod分为普通Pod和静态Pod。
- 普通Pod一旦被创建,就会被放入etcd中存储,随后会被Master调度到某个Node上并进行绑定,随后会被对应Node上的kubelet实例化成一组容器并启动起来。如果Pod所在的Node宕机了,Master会将这个Node上的所有Pod重新调度到其它Node节点上。
- 静态Pod不会存储到etcd中,而是存放在某个Node节点上的一个具体文件中,并且只在此Node上启动运行。
-
-
Service:Service是一组Pod的抽象,每个Service都拥有一个唯一指定的名字,并被分配一个虚拟IP(Cluster IP、Service IP或VIP),Service通过代理后端Pod对外或者对内提供访问,就好比nginx和后端服务的关系。来自这个IP的请求都会经过调度后转发给后端Pod中的容器。Service对象挑选、关联Pod对象的方式跟控制器一样,都要基于Label Selector进行定义。Service主要有如下三种类型,此三种类型中,每一种都要以前一种为基础才能实现,而且LoadBalancer类型需要协同集群外部的组件才能实现,且此外部组件不受k8s集群管控。
- 第一种是仅用于集群内部通信的Cluster IP类型。
- 第二种是接收集群外部请求的NodePort类型,他工作于每个节点的主机IP之上。
- 第三种是LoadBalancer类型,它可以把外部请求负载均衡至多个Node主机IP的NodePort之上。
-
Label:标签用于区分对象,使用标签引用对象而不再是IP地址。Label以键值对的形式存在,每个对象可以有多个标签,通过标签可以关联对象。
- 假设Service代理一个或者多个Pod,但是某一个Pod因故障被删重新调度出一个新Pod,那么这个Pod的IP可能会发生改变,因为容器的IP是随机的。那Service怎么能知道这个新Pod的IP呢。这时使用标签就可以完美的解决问题。k8s中的Pod,所谓一个萝卜一个坑,只要不是手动删除Pod,那么这个Pod一定会一直存在,down掉会重启,故障会重建。在最初创建Pod时,它的Label就已经写死了,当然后面是可以手动改的。比如app:nginx。所以即便重建了Pod,IP变了,Label不会变。Service通过LabelSelector去找Label为app:nginx的服务依然能够找到。
-
Ingress:给Service提供外部访问功能。
-
Namespace:可以抽象理解为对象的集合。比如将集群内部的对象划分到不同得到项目组或用户组。比如Pods、Services都是属于某一个Namespace的(默认是default)。
-
Volume:数据卷,共享Pod中使用的数据。
高级对象
k8s中,集群级别的大多数功能都是通过几个被称为控制器的进程执行实现的,这几个进程被集成与kube-controller-manager守护进程中。由控制器完成的功能主要包括生命周期功能和API业务逻辑,如下:
- 生命周期功能:包括Namespace创建和生命周期、Event垃圾回收、Pod中止相关的垃圾回收、级联垃圾回收及Node垃圾回收。
- API业务逻辑:例如有ReplicaSet指定的Pod扩展等。
控制器的种类基本如下:
- ReplicationController:简称RC。在旧版的k8s中,只有RC对象,使用它来确保Pod以用户指定的副本数量运行。容器异常或者缺少都会自动处理。
- ReplicaSet:ReplicaSet 是 ReplicationController 的替代物。因此作用基本相同,RC与RS唯一区别就是支持LableSelector不同,RS支持基于集合的标签。官方建议使用Deployment来自动管理RS,因为有些功能RS不支持,Deployment支持。
- Deployment:Pod控制器,它支持版本记录、回滚、暂停升级等高级特性。Pod是不可以被直接创建的,需要先创建控制器,然后由控制器去创建Pod。每个Pod都对应一个deployment控制器。
- StatefulSet:为了解决有状态服务的问题(对应 Deployments 和 ReplicaSets是为无状态服务而设计)。
- DaemonSet:保证在每个Node节点上都运行一个Pod,常用来部署一些集群的日志、监控等应用。比如fluentd、logstash、prometheus等。
- Job:一次性任务,运行完后Pod销毁,不再自动重建。
- CronJob:定时任务
三、Kubernetes组件
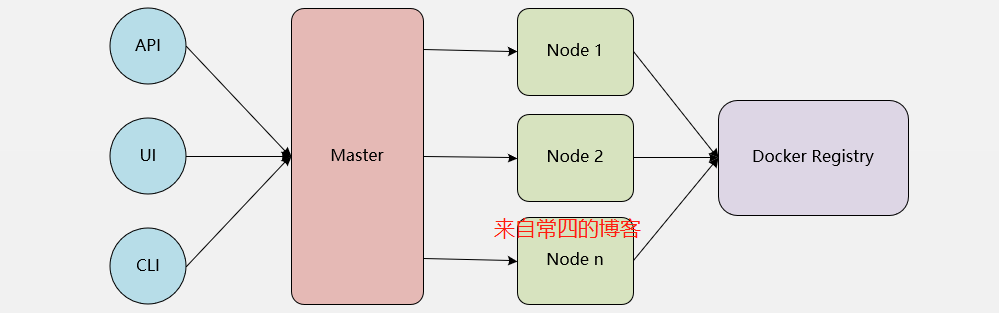
Kubernetes的结构略微复杂,我会从大的层面一点点往下拆分叙述。整个Kubernetes集群大致划分为四部分:Clients,Master,Node,Registry。k8s本身其实就Master和Node两部分。
- Master:是Kubernetes集群的管理节点,是提供集群资源访问与管理的唯一入口。
- Node:是Kubernetes集群运行Pod的服务节点,实质上也就是运行容器。
- Registry:容器的运行需要依赖于镜像。
- Clients:编程接口,图形化接口,命令行接口。我们通过这些接口向Master发请求来管理容器,比如创建、删除等操作,我们称发起请求者为管理客户端(Clients)。
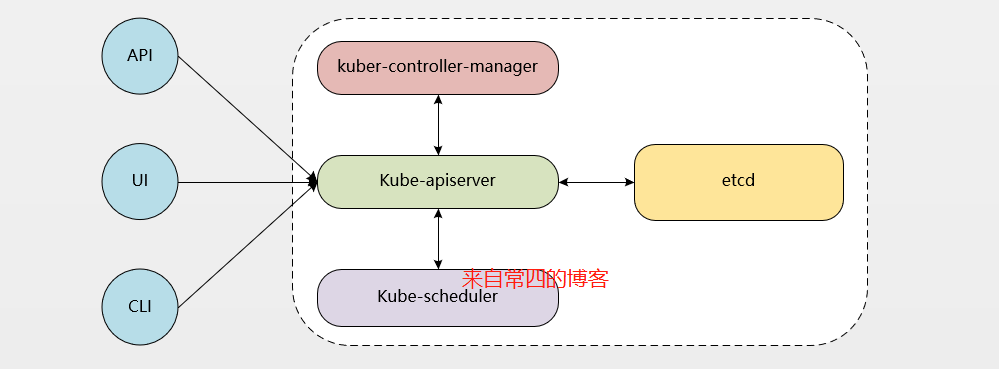
Master的组件
Master节点有四个核心组件,每一个组件都是单独的服务,下面组件中只有etcd不是k8s自己提供,它只是k8s的主要组成部分,etcd也是CNCF的成员。
-
kube-apiserver:是整个k8s集群对外提供服务的唯一接口,它提供请求过滤、访问控制等机制,是各组件的协调者,此API是声明式的(简单说就是用户想要什么规格的容器直接跟kube-apiserver说就行了,过程不用你管)。用户的合法请求会被API放行,然后存入etcd中。
- 是否合法指的是:etcd就好像公司领导,kuber-apiserver就是门口保安,领导规定,必须什么样的人你能放进来。k8s将etcd所能接受的数据规格范式加以封装定义在了kube-apiserver中,符合规格才能放行。
- 程序的编程范式包括声明式和命令式:声明式强调结果;命令式强调过程。
-
kube-scheduler:资源调度器。kube-apiserver收到新建Pod的请求,识别其合法并存入etcd,然后kube-scheduler去watch kube-apiserver知道此需求,根据预定的调度策略评估出一个最合适Node节点来运行Pod,如果没有最合适,那就随机,最后会把调度的结果记录在etcd中。
-
kube-controller:控制器。就好比人类的大脑一样,负责维护集群的状态、故障检测与恢复、自动扩展、节点状态等等。kube-controller有一个control loop的机制,它会循环检测集群中Pod的状态,假如Nginx启的不是预期的80端口,那就由kube-controller来控制容器重启、重建,直到达到预期效果为止。
-
replication-controller:管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的Pod副本数量与实际运行Pod数量一致。
-
etcd:是一个键值(key:value)格式的存储系统。k8s集群中所有状态信息都需要持久化存储在etcd中,etcd是独立的服务组件,并不隶属于集群本身。etcd不仅提供键值数据存储,还为集群提供了监听机制,用于监听和推送变更,在k8s中,etcd键值发生变化会通知到API server,并由其通过watch api向客户端输出。
-
举例:用户发送新建Nginx容器的请求给kube-apiserver,kube-apiserver识别其合法后以键值对的方式存入etcd,kube-scheduler和kube-controller通过watch kube-apiserver知道此需求,然后kube-scheduler负责资源分配并决定容器运行在哪个Node上,至于运行时所需的镜像及运行的健康状态的维护都由kube-controller来负责,kube-controller会循环将当前容器的状态与watch到的用户预期的需求做对比,看是否匹配。
-
k8s watch功能:k8s提供的watch功能是建立在etcd之上的。早期的k8s架构中kube-apiserver、kube-controller、kube-scheduler、Kubelet等都是直接去watch etcd的,但是随着实例的增多,对etcd造成的压力也越来越大,因此,现在是当etcd中的键值发生变化时,通知kube-apiserver,其它的组件需要watch时去直接找kube-apiserver,这样大大减小了etcd的压力。
-
Node的组件
Node节点负责提供运行容器的各种依赖环境,并接受master的管理。每个Node主要由以下几个组件构成:
- kubelet:kubelet是运行与Node上面的守护进程,他从API server接收关于Pod对象的配置信息并确保它们处于期望的状态,kubellet会在API server上注册当前工作节点,定期向master汇报资源使用情况,并通过cAdvisor监控头容器和节点资源使用情况。kubelet会去watch kube-apiserver,如果发现有新任务的调度结果分到了自己这个Node节点上,便会接过来执行此任务。完成后将结果汇报给kube-apiserver。
- container runtime:每个Node都需要提供一个容器运行时(container runtime)环境,它负载下载镜像并运行容器。k8s支持多种容器运行环境,如:docker、rkt、cri-o等等,只不过k8s标准支持的容器是docker,其它容器引擎想要与k8s配合使用,需要接入到k8s的cri接口 。因为不同容器技术的更新速度是不一样,k8s只能以一个相对比较权威的容器技术来作为标准。
- kube-proxy:每个Node都需要一个kube-proxy守护进程,它能够按需为service生成iptables或ipvs规则,从而捕获访问当前service的cluster ip的流量并将其转发至正确的后端Pod对象。
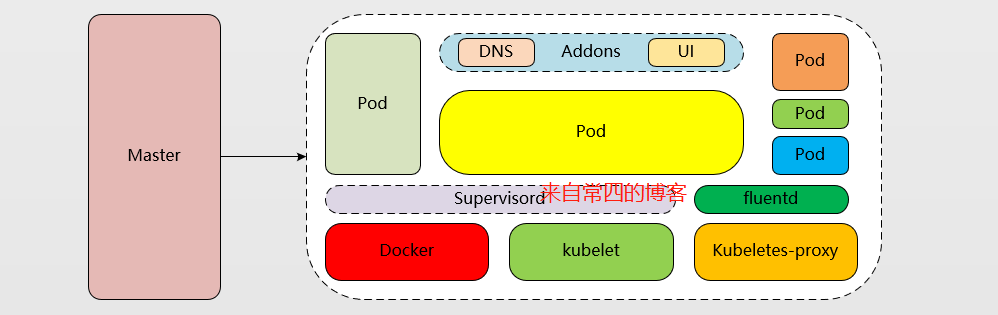
Addons
除了上面Master和Node几个核心组件,k8s集群还需依赖一些扩展插件来提供完整的功能,他们通常是由第三方提供的特定应用程序,如下:
- Coredns:在k8s集群中调度运行提供DNS服务的Pod。从k8s 1.11版本开始,集群默认使用CoreDNS为集群提供服务注册和服务发现的动态名称解析服务。
- CNI:容器网络接口,k8s的网络模型需要借助这类插件才能实现。比如flannel,calico等。
- Fluentd:为集群提供日志采集、存储和查询。
- Ingress Controller:Service是一种工作于传输层的负载均衡器,而Ingress是在应用层实现的HTTP(s)负载均衡机制。不过Ingress本身并不能进程“流量穿透”,它仅是一组路由规则的集合,这些规则需要通过Ingress Controller发挥作用。目前,此类可用的项目有:Nginx、Tarefik、Envoy和Haproxy等。
- Kubernetes Dashboard:管理k8s集群的图形化界面。
四、Kubernetes网络
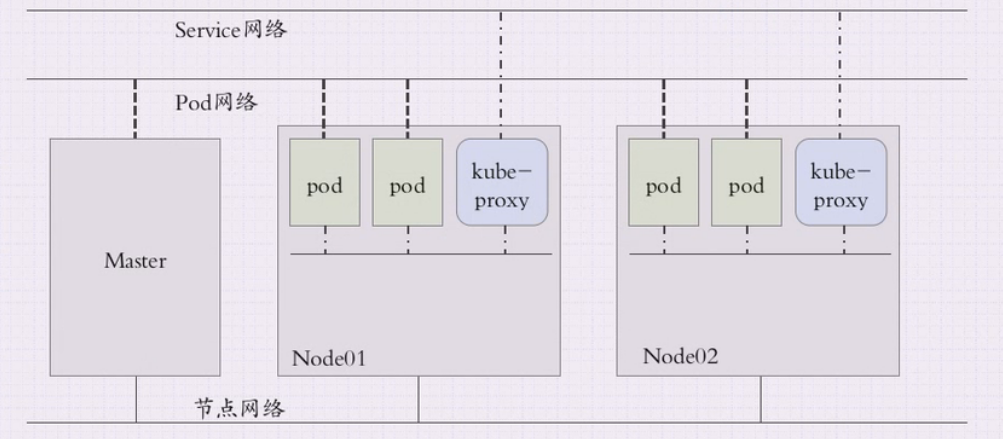
如下图所示,k8s集群包含三个网络:
- 节点网络:各主机自身(master、node、etcd)所属的网络,其地址配置于主机层面的网络接口,不被k8s集群管理。
- Pod网络:这是一个虚拟网络,为各Pod对象设定IP地址等网络参数,其地址配置于Pod内容器的网络接口上。Pod网络需要借助于kubenet或CNI插件实现。该插件可以部署在k8s集群之外,也可以托管在集群上。
- Service网络:这也是一个虚拟网络,用于为k8s集群中的service配置虚拟IP地址,这种IP没有任何网络接口。它是通过Node上的kube-proxy配置为iptables或ipvs规则,从而将发往此地址的所有流量调度至后端各Pod对象上。service网络在创建k8s集群时指定,而各service的地址则在用户创建service时动态配置。此IP是集群提供服务的接口,故也称为Cluster IP。
五、小小建议
Kubernetes的概念还是蛮多的,不建议是一脑门扎到概念上,尽量结合实践去理解,可以多看看官网,部分页面是有中文支持的。在下写的时候脑门也是嗡嗡的,可能会有不完善或者偏差的地方,未完待续吧......
参考资料
- 《Kubernetes权威指南》
- 《Kubernetes进阶实战》
- Kubernetes官网
- ywhu的博客:k8s的watch功能
写作不易,转载请注明出处,谢谢~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号