EF Core-1
带着问题去思考,大家好!
前几天了解到EF Core的开发模式:DB First(数据库优先),Model First(模式优先),Code First(代码优先)。
我所接触的大多是DB First。如果大家了解的话,有些开源后台项目,基本都会有后两者,因为方便大家更快的去使用部署起来后台。
在建议的Layered ['leɪəd] Architecture [ˈɑːrkɪtektʃər]模式中,---表示层,业务层和数据层,其后Evans分析并引入两个关键变化。
一:将关注点放到layer上,而不是tier。layer是应用程序组件之间的逻辑分隔,而tier是物理上不同的应用程序和服务器。
二:识别的层数分为4各层-表示层-应用层-领域层和基础结构层

整体式应用程序
自底向下设计,我们都是围绕着数据模型来进行开发设计,其中的过程以及尤其依赖数据模型的用户界面和体验。
在整体式应用程序中,数据从底部的持久化存储到前端,然后在返回。
根据分层架构,我们都知道,从存储到前端以及从前端到存储。我们不应该考虑把应用程序堆栈分成两部分吗?独立处理命令堆栈和读堆栈对于开发是不是更加有效果呢?所以NOSql存储来了,使得经典的RDBMS系统开始支持XML和JSON。这也正式Command and Query Responsibility Segregation(CQRS)模式的使用。
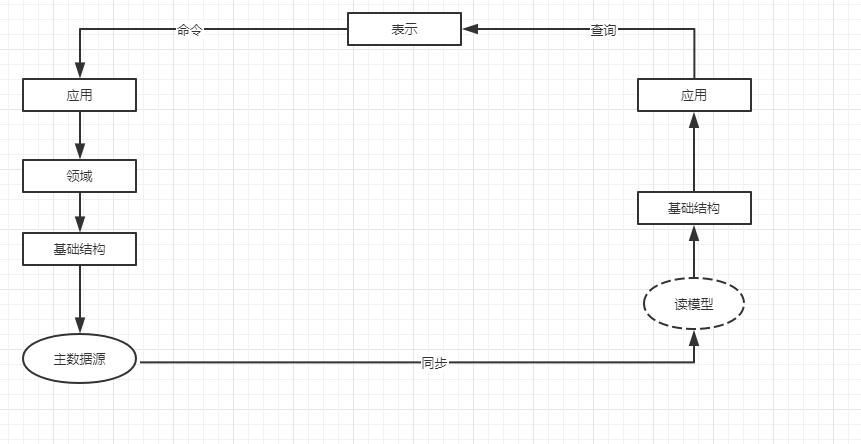
以上是结合CQRS设计的分层架构模式
CQRS方法
CQRS不是万能的,重要的是他的思想。
有经验的开发人员知道。创建一个理想的数据模型,使其能够将关系数据模型的原则和最终用户实际需要的视图的复杂性结合起来是很困难的。如果只有一个应用程序堆栈,就只能有一个面向持久化的数据模型,但是需要调整这个模型,使其能够有效的满足前端的需求。特别是与某种方法学(如领域驱动设计的额外的抽象层结合起来时),后端(业务逻辑和数据访问逻辑)的设计很容易变得一团乱。
以上问题。CORS通过将设计问题分解为两个较小的问题,新应用程序架构设计解决问题,并不释施加外部约束,使设计变得更加简单。具有不同的堆栈的好处是,容易为实现名利和查询使用不同的对象模型。有必要,可以为命令使用一个完整的领域模型,为表示使用一个定制的普通的数据传输对象,可能这些对象从SQL查询具体化的,需要多个表示前端,只需要额外创建读模型。整体复杂度是个体复杂度的和,而不是笛卡尔积。
1:不同的数据库
分解成不同的堆栈有一些问题,两个堆栈同步问题,数据命令写入能够被一致地读回?根据自身业务,CQRS实现可以基于一种两种数据库,如果使用一个共享数据库,共享数据库确保了经典的ACID一致性,只需要在读堆栈中的普通查询做一些额外的工作。
性能和扩展行,可以考虑为命令堆栈和读堆栈使用不同的持久化端点。

什么时候用CQRS?
这是一种模式,CQRS架构模式主要是被设计来解决高并发业务场景的性能问题。
基础结构层的构成
基础结构层是与使用具体的技术相关的所有东西,包括数据持久化O/RM框架(EF),外部的Web服务,特定的安全API,日志记录,跟踪,IOC容器,缓存等。最突出的是组件的持久化层,也就是数据访问层。
持久化层 缓存层 外部服务这些已经非常成熟,不在这里赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号