kettle工具的介绍和使用
kettle详解(数据抽取、转换、装载)
原文地址链接:https://blog.csdn.net/qq_35731570/article/details/71123413
文件资源库模式的调度命令:
job: $kitchen路径 -file=$job路径 kitchen.sh -file=/opt/dpbs/kettlefile/pan_quality_indicator.kjb
trans: $pan路径 -file=$trans路径 ./pan.sh -file=/home/hadoop/workplace/kettle/trans/test_cml.ktr -norep
数据库资源库模式的调度命令:
job: $kitchen路径 -rep=kettle名 -user=用户 -pass=密码 -job=job名称 ./kitchen.sh -rep=kettle1 -user=admin -pass=admin -job=job
trans: $pan路径 -rep=kettle名 -user=用户 -pass=密码 -trans=转换名称 ./pan.sh -rep=kettle1 -user=admin -pass=admin -trans=trans
一:下载路径
当你要学习一个工具时,往往一开始就找不到下载路径,也不知道是为什么,连个官网都找不到,最后还是问的别人要的路径,做程序好心酸。
http://community.pentaho.com/projects/data-integration 下载路径
二:学习
kettle是什么?
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。kettle支持图形化的GUI设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,其中最主要的我们通过熟练的应用它,减少了非常多的研发工作量,提高了我们的工作效率.
Kettle是一款国外开源的ETL工具,纯Java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
为什么使用kettle?
这里简单概括一下几种具体的应用场景,按网络环境划分主要包括:
-
表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
-
前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
-
文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来;
综上3种模式如果我们都用传统的模式无疑工作量是巨大的,那么怎么做才能更高效更节省时间又不容易出错呢?答案是我们可以用一下Kettle-_-!
使用kettle需要了解的知识?
|
|
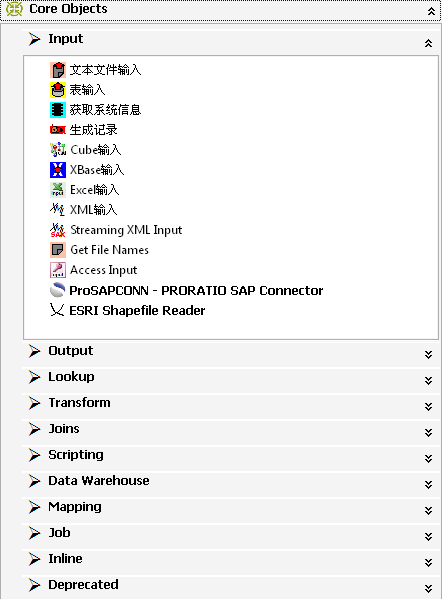
Main Tree菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。
DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。
Steps:一个transformation中应用到的环节列表
Hops:一个transformation中应用到的节点连接列表 |
 |
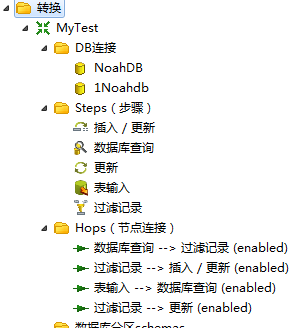
Core Objects菜单列出的是transformation中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
Input:输入环节 Output:输出环节 Lookup:查询环节 Transform:转化环节 Joins:连接环节 Scripting:脚本环节 |
|
类别 |
环节名称 |
功能说明 |
|
Input |
文本文件输入 |
从本地文本文件输入数据 |
|
表输入 |
从数据库表中输入数据 |
|
|
获取系统信息 |
读取系统信息输入数据 |
|
|
Output |
文本文件输出 |
将处理结果输出到文本文件 |
|
表输出 |
将处理结果输出到数据库表 |
|
|
插入/更新 |
根据处理结果对数据库表机型插入更新,如果数据库中不存在相关记录则插入,否则为更新。会根据查询条件中字段进行判断 |
|
|
更新 |
根据处理结果对数据库进行更新,若需要更新的数据在数据库表中无记录,则会报错停止 |
|
|
删除 |
根据处理结果对数据库记录进行删除,若需要删除的数据在数据库表中无记录,则会报错停止 |
|
|
Lookup |
数据库查询 |
根据设定的查询条件,对目标表进行查询,返回需要的结果字段 |
|
流查询 |
将目标表读取到内存,通过查询条件对内存中数据集进行查询 |
|
|
调用DB存储过程 |
调用数据库存储过程 |
|
|
Transform |
字段选择 |
选择需要的字段,过滤掉不要的字段,也可做数据库字段对应 |
|
过滤记录 |
根据条件对记录进行分类 |
|
|
排序记录 |
将数据根据某以条件,进行排序 |
|
|
空操作 |
无操作 |
|
|
增加常量 |
增加需要的常量字段 |
|
|
Scripting |
Modified Java Script Value |
扩展功能,编写JavaScript脚本,对数据进行相应处理 |
|
Mapping |
映射(子转换) |
数据映射 |
|
Job |
Sat Variables |
设置环境变量 |
|
Get Variables |
获取环境变量 |
|
|
Main Tree菜单列出的是一个Job中基本的属性,可以通过各个节点来查看。
DB连接:显示当前Job中的数据库连接,每一个Job的数据库连接都需要单独配置。
Job entries:一个Job中引用的环节列表
|
|
|
Job entries菜单列出的是Job中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
每一个环节可以通过鼠标拖动来将环节添加到主窗口中。
并可通过shift+鼠标拖动,实现环节之间的连接。 |


|
类别 |
环节名称 |
功能说明 |
|
Job entries |
START |
开始 |
|
DUMMY |
结束 |
|
|
Transformation |
引用Transformation流程 |
|
|
Job |
引用Job流程 |
|
|
Shell |
调用Shell脚本 |
|
|
SQL |
执行sql语句 |
|
|
FTP |
通过FTP下载 |
|
|
Table exists |
检查目标表是否存在,返回布尔值 |
|
|
File exists |
检查文件是否存在,返回布尔值 |
|
|
Javascript |
执行JavaScript脚本 |
|
|
Create file |
创建文件 |
|
|
Delete file |
删除文件 |
|
|
Wait for file |
等待文件,文件出现后继续下一个环节 |
|
|
File Compare |
文件比较,返回布尔值 |
|
|
Wait for |
等待时间,设定一段时间,kettle流程处于等待状态 |
|
|
Zip file |
压缩文件为ZIP包 |
怎么使用kettle?
一:配置环境
1、安装java JDK
1)首先到官网上下载对应JDK包,JDK1.5或以上版本就行;
2)安装JDK;
3)配置环境变量,附配置方式:
安装完成后,还要对它进行相关的配置才可以使用,先来设置一些环境变量,对于Java来说,最需要设置的环境变量是系统路径变量path。
(1)要打开环境变量的设置窗口。右击“我的电脑”,在弹出的快捷菜单中选择“属性”选项,进入“系统属性”对话框,如图所示。选择“高级”标签,进入“高级”选项卡,再单击“环境变量”按钮,进入“环境变量”对话框,如图所示:
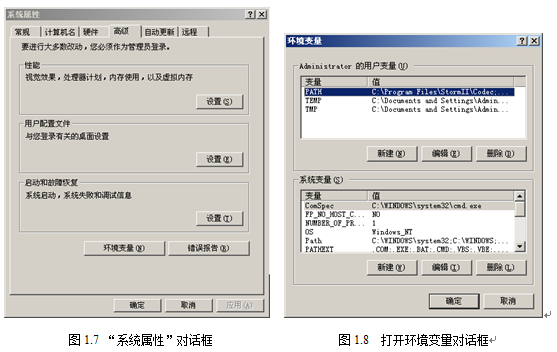
(2)在“Administrator的用户变量”列表框中,选择变量PATH,待其所在行变高亮后,单击“编辑”按钮,如图所示。
(3)在弹出的“编辑系统变量”对话框中,将JDK安装路径下的bin目录路径设置到Path变量中,如图所示。
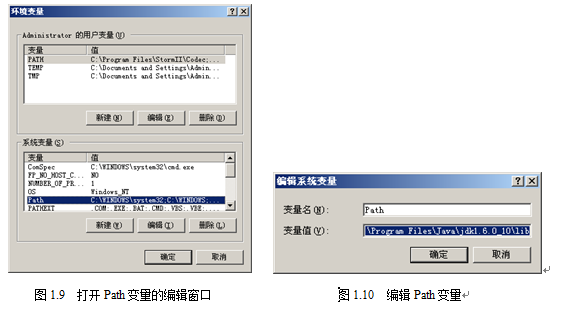
编辑完后,单击“确定”按钮,进行保存,环境变量Path的设置就正式完成。
注意:设置Path变量的路径,必须是JDK安装目录中的bin目录,有时候在JDK安装目录的同一层会有JRE的安装目录,因此请谨慎选取相关路径,避免将路径设置成JRE目录下的bin目录。
3、2 测试JDK配置是否成功
设置好环境变量后,就可以对刚设置好的变量进行测试,并检测Java是否可以运行。
(1)单击“开始”按钮,选择“运行”选项,在“运行”对话框中输入cmd命令。
(2)之后单击“确定”按钮,打开命令行窗口。
(3)在光标处输入:javac命令,按下Enter键执行,即可看到测试结果
3、3 运行Kettle

二、练习
功能简述:数据库TestA中的UserA表到数据库TestB的UserB表;
实现流程:建立一个转换和一个作业Job;
进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat或Kettle.exe文件。
不输入密码进入,可以看到主对象树和核心对象.
新建一个转换后,看到转换下有DB连接,Steps,Hops,数据库分区schemas,子服务器,kettle集群schemas
A:建立一个转换:打开Kettle.exe,选择没有资源库,进入主界面,新建一个转换,转换的后缀名为ktr,转换建立的步骤如下:
步骤1建立DB连接:创建DB连接,选择新建DB连接,如下图,我们输入相应的数据库配置信息之后点击Test按钮测试是否配置正确!
填入信息,最后要起连接名testA,先点击test测试连接,如果报错,可能是数据库信息填的不对。
Host Name:10.8.200.105/localhost
Database Name:lifedev
Port Number:1521
User Name:...
password:...
点击test进行连接测试。
建立好DB连接后,会出现子节点testA、testB

步骤2:建立步骤和步骤关系,
点击核心对象,我们从步骤树输入中选择【表输入】,如下图,这样拖拽一个表输入之后,我们双击表输入之后,我们自己可以随意写一个sql语句,这个语句表示可以在这个库中随意组合,只要sql语句没有错误即可,我这里只是最简单的把TestA中的所有数据查出来,语句为select * from LXX_KETTLE_TESTA

接下来我们创建另外一个步骤输出中的【插入/ 更新】,然后在【表输入】上同时按住shift键和鼠标左键滑向【插入/ 更新】,这样建立两个步骤之间的连接,【插入/ 更新】执行的逻辑是如果UserA表中的记录在UserB中不存在那么就插入,如果存在就更新,如下图,在插入更新中我们可以做一些关键条件和字段映射,这里我们是最简单的!点击保存,把我们建立的转换保存一下。

建立好转换之后,我们可以直接运行这个转换,检查一下是否有错,如图,有错误都会在下面的控制台上输出。

步骤三:如果我们需要让这个转换定时执行怎么办呢,那么我们需要建立一个作业job
见下图,在简单表同步这个转换中,我们把在A步骤中建立的ktl配置上,注意路径的正确性;

这样我们在【Start】步骤上面双击,如图:

实例2:全面进阶的一个稍微复杂的例子



操作步骤:
在EtltestTrans页面下,点击左侧的【Core Objects】,点击【Input】,选中【表
输入】,拖动到主窗口释放鼠标。
双击【表输入】图标
数据库连接选择刚刚创建好的etltest数据库连接,在主窗口写入对应的查询
语句
Select * from trade ,如下图:

点击确定完成。
点击核心对象->查询,选中【数据库查询】,拖动到主窗口释放鼠标。
按住shift键,用鼠标点中刚才创建的【表输入】,拖动到【数据库查询】上,
则建立了两个环节之间的连接,如图:

双击【数据库查询】
步骤名称写入account 表查询,数据库连接选择刚刚创建好的etltest 数据库
连接,查询的表写入account,查询所需的关键字中,表字段写入acctno,比较
操作符写入“=”,字段1写入acctno。
在查询表返回的值里面写入custno,确定完成,如下图:

同上,再创建一个数据库查询,命名为cust表查询,查询的表写入cust,查
询所需的关键字写入custno=custno,查询表返回的值写入custname,custid,
custtype,如下图:

点击核心对象->Flow下过滤记录,拖动到主窗口释放鼠标。
点击核心对象->脚本,选中两个【Modified Java Script Value】,拖动到主窗
口释放鼠标。分别双击打开,重命名为“对公类型修改”和“对私类型修改”。
同时,分别创建【过滤记录】和【对公类型修改】,【对私类型修改】的连接。
双击过滤记录打开。
第一个<field>里面选择custtype,点击<value>,在Enter value 里面写入1,
确定,如图:

在发送true数据给步骤里,选择【对私类型修改】,在发送false数据给步骤
里,选择【对公类型修改】,确定保存,如图:

双击【对公类型修改】,在里面写入javascript 脚本语句
var custtype_cn='对公客户交易'
在字段中写入custtype_cn,类型选为string。确定。
同理,在【对私类型修改】中,在里面写入javascript脚本语句
var custtype_cn='对私客户交易'
在字段中写入custtype_cn,类型选为string。确定。
点击左侧的【Transform】,选中两个【增加常量】,拖动到主窗口释放鼠标。
分别双击打开,重命名为“增加对公常量”和“增加对私常量”。
分别建立【对公类型修改】和【对私类型修改】与【增加对公常量】和【增
加对私常量】的连接,如图:

双击【增加对公常量】,名称写入value,类型选择string,值写入“这是一
笔对公客户发生的交易”,确定保存。
同理,双击【增加对私常量】,名称写入value,类型选择string,值写入“这
是一笔对私客户发生的交易”,确定保存。
点击左侧的【Output】,选中【文本文件输出】,拖动到主窗口释放鼠标。
建立【增加对公常量】,【增加对私常量】和【文本文件输出】的连接,如图:

双击打开【文本文件输出】,文件名称写入D:\etltest\etltest.txt
点击内容标签,根据情况进行修改,例如
点击字段标签
名称依次写入tradeid,acctno,amt,custno,custname,custid,custtype_cn,
value,类型根据各个字段实际类型进行选择
确定保存
点击保存创建好的transformation。
点击运行这个转换。
点击launch,开始运行
当所有状态都变已完成时,则转换完成,如图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号