微服务下,接口性能优化的一些总结
如果是自己写的代码,加上又熟悉业务场景,很容易就知道性能瓶颈点。但如果上来就去优化别人的代码,甚至是其他产品线的代码,还是有一些挑战的。最近就在做这事,接手了优化公司一个业务引擎接口的任务,在这儿对优化方法做一些总结。
优化接口总共分两步,一是找到性能热点,二是解决热点。在不熟悉代码的情况下,找热点是最难的,找到后对症下药就容易多了。先主要说一下如何找性能热点。
一、查调用链。
微服务下,调用链追踪能很容易的定位到是链路上的哪个环节出现问题。从而确定是别人接口把你的拖慢了,还是自己接口内代码有问题;且调用链反映的是线上真实数据,比跑线下测试数据更有说服力。
调用链基础是调用前后记录的日志。

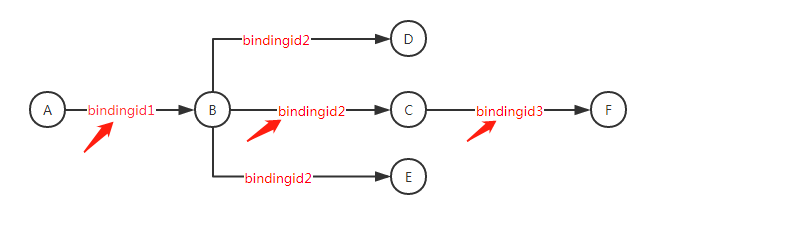
这里以A->B->C举例,简单说一下调用链常用的几个参数:
- TraceID:一个完整链路的唯一ID。本例中,TraceID是在A、B、C中传递的,ABC中记录的链路日志都用这个唯一的TraceID,不会变。
- BindingID:一个线程内的ID。本例中,A记录的链路日志中,有唯一的BindingIDA,同样B、C中各有BindingIDB、BindingIDC
![]()
注意:BClient记日志的BindingID 跟 CServer记Log的BindingID不一样
- ConversationID:一个会话的ID。本例中,A调用B,A生成一个ConversationID,传给B,B在返回结果前,记下日志,A在收到结果后记下日志。这两条日志有唯一的ConversationID。
- VirtualPath:用于标识微服务路径
- Component:用于标识组件,或者微服务名称
- CostInMilsecond:记录一次会话耗时。Client端发起前开始计时,收到后记入日志、Server端返回前记入日志。
明白这几个参数后,再看看具体使用。我们公司是用Kibana作为查询统计工具的。那么,我的分析步骤有如下几步:
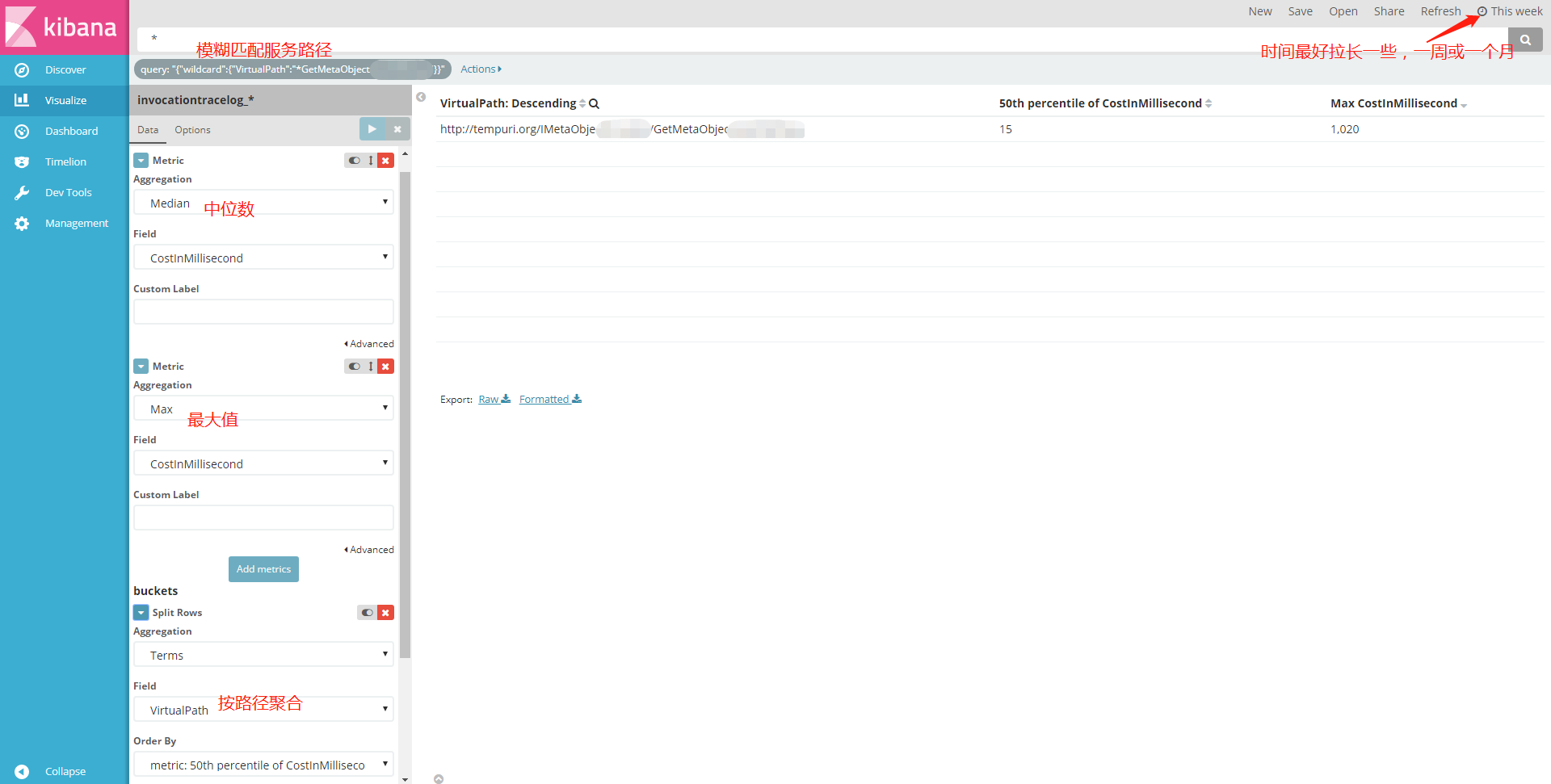
1. 确定该请求的最长耗时(用于重点优化)、耗时中位数(用于全面优化):
需要用到Kibana的Visualize功能,指定一个Metric为中位数、一个Metric为Max,再按照服务路径聚合即可
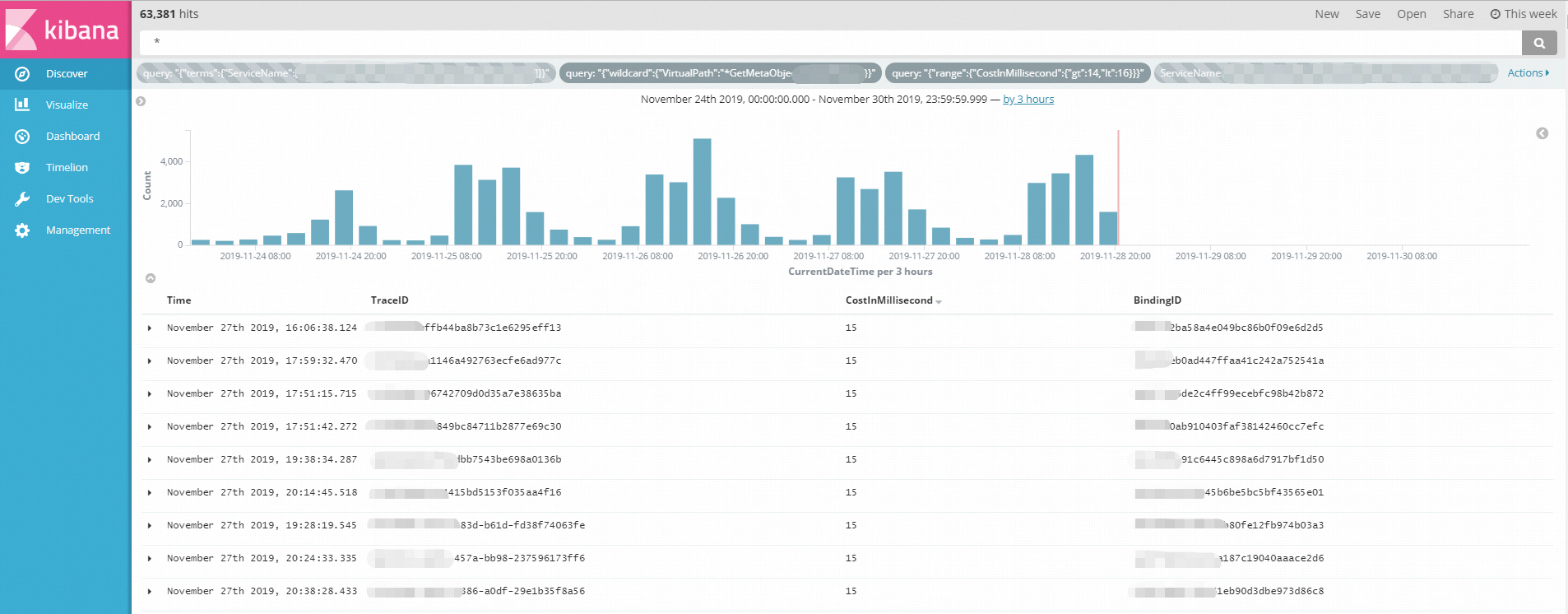
2. 拿到指定耗时时间附近的多个请求的BindingID
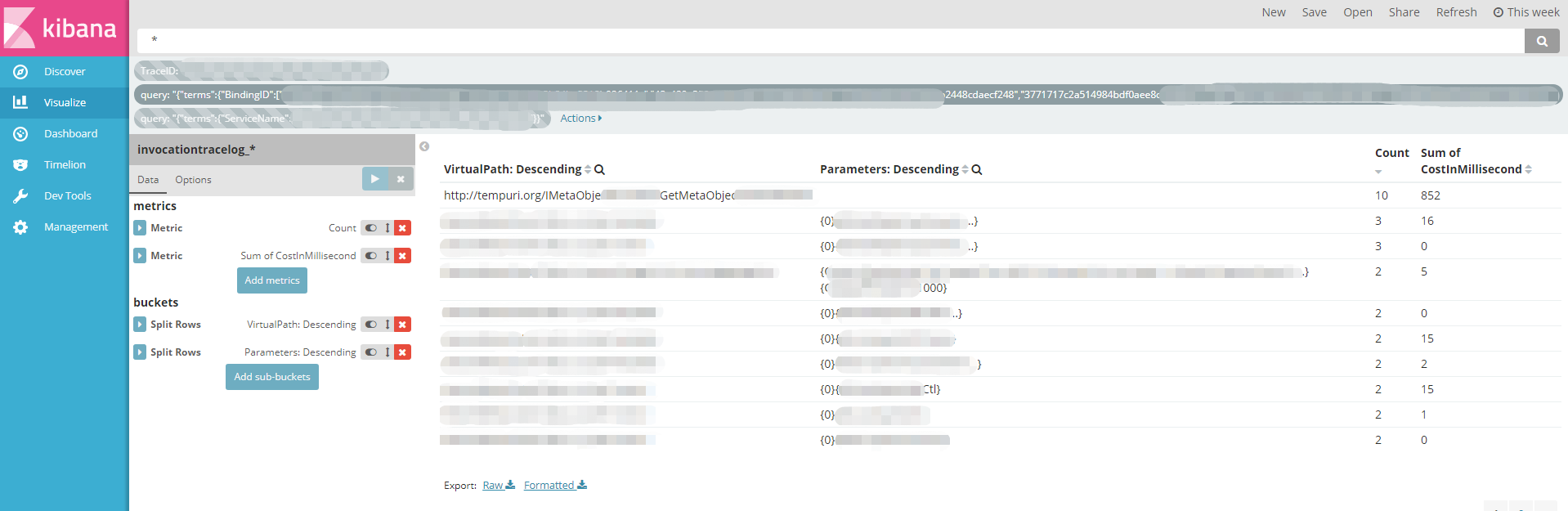
3. 统计其子链路耗时:
用Visualize可以统计出平均每个线程中,每个子链路的被调用次数、总耗时。然后看看在主链路耗时的占比情况。如果占比比较大,说明链路有问题了。比如我最近优化的几个接口,在链路上能看到数据库存储过程执行次数多且慢,那么肯定可以定位是数据访问的问题。
如果占比不多,那就要继续分析方法内部了。
二、本地分析
1. 使用Dottrace
方法内部的分析,最主要的是采用合理的参数来驱动被测方法。这里我会选最耗时的参数来覆盖被测方法的大多数分支,并且充分暴露问题。
还要注意一点的是,在正式采样前,先对程序预热一下,也就是跑一次被测方法,让该缓存的缓存下来。这样更能反映线上一般情况。
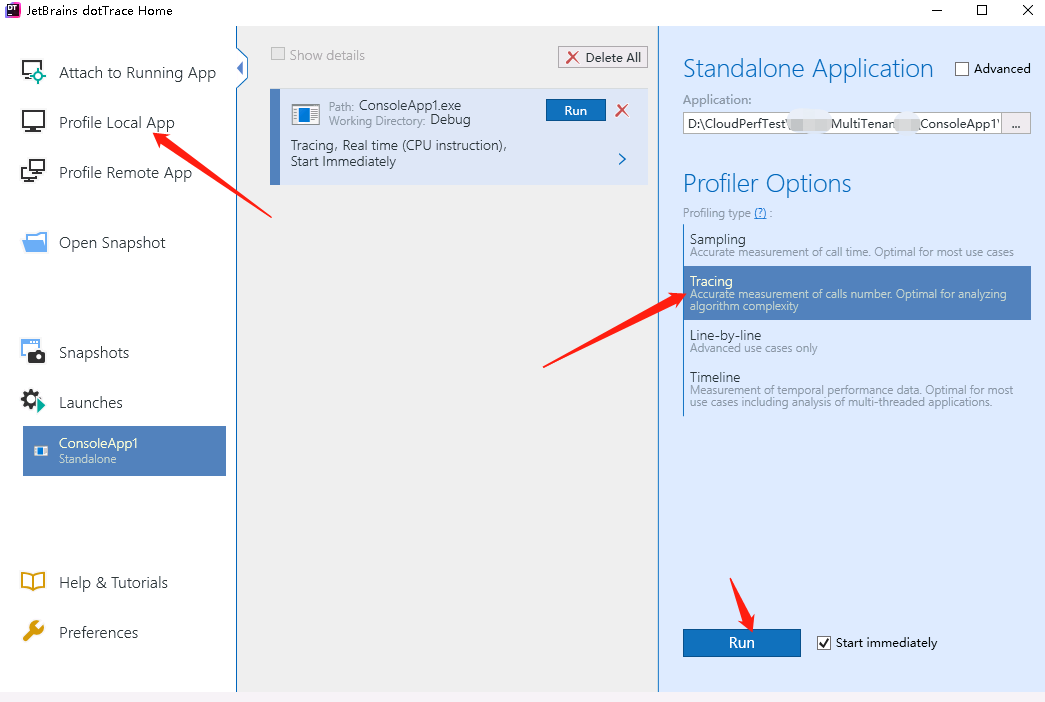
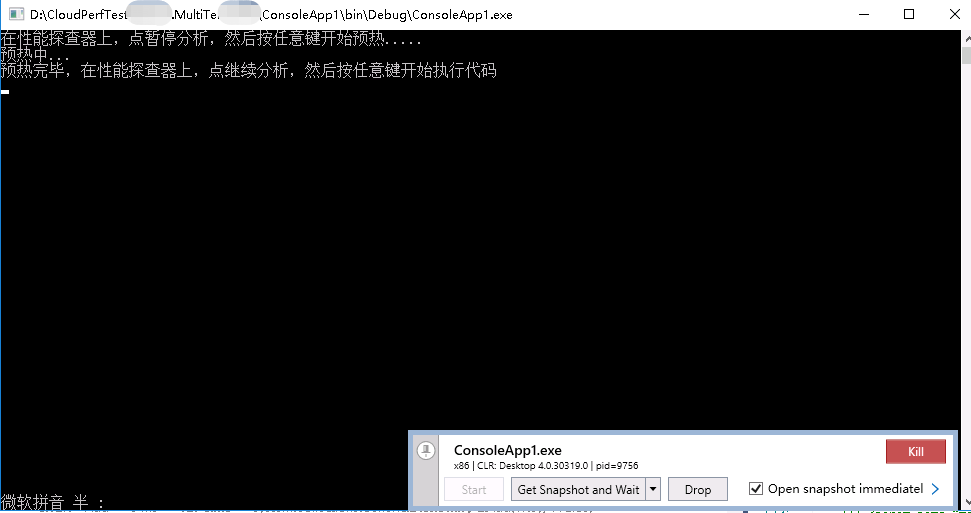
2. 结果解读
dottrace可以说是异常的强大了。给你列出了某个方法的被调用次数、耗时、Collection操作耗时、系统函数耗时、用户函数耗时。基本上看这个图就知道热点在什么地方了。
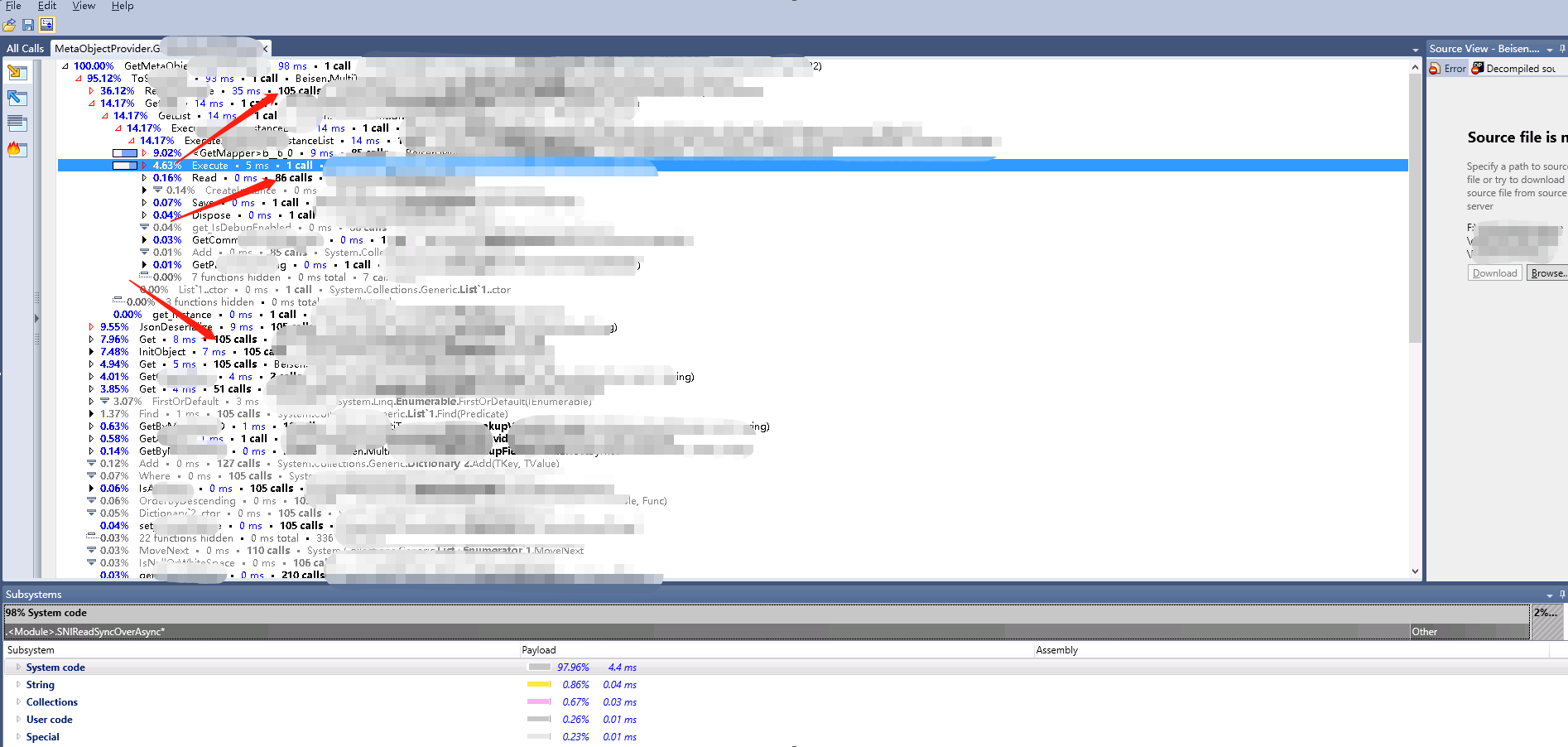
三、优化方法总结
热点找到了,后面就是对症下药的优化了。总结一下优化方法也就是:
1. 循环体内的IO、远程调用,改为循环外去重后批量执行,避免重复发起调用
2. 数据库慢查询,优化SQL、索引
3. 基础的、频繁查询的方法,可以把执行结果放到缓存
4. 串行的远程调用可以改为并行。(慎用,请求高峰期会造成内存暴涨,同时也可能导致上下文丢失)
5. 非主流程的方法,比如发消息通知、增删会员积分,改为发消息到队列然后异步消费。
......
先写到这儿吧。。公司要求严、打马好辛苦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号