《视觉SLAM十四讲》笔记(ch12)
ch12——回环检测
主要目标:1.理解回环检测的比要性
2.掌握基于词袋的外观式回环检测
3.通过DBoW3的实验,学习词袋模型的实际用途
SLAM主体(前端[提供特征点的提取和轨迹、地图的初值]和后端[负责对所有这些数据进行优化])主要目的:估计相机运动
本讲将介绍主流视觉SLAM中检测回环的方式:词袋模型,并通过DBoW库上的实验程序,使读者得到更加直观的解释。
回环检测的关键:如何有效的检测出相机经过同一个地方这件事。
回环检测的作用:1)得到一个全局一致(Global Consistent)的估计,提高系统稳定性。
2)由于回环检测提供了当前数据与所有历史数据的关联,在跟踪算法丢失后,可利用回环检测进行重定位。
仅有前端和局部后端——VO
带有回环检测和全局后端的系统——SLAM
实现回环检测的方法:1)基于里程计的几何关系(Odometry based):当我们发现相机运动到了之前的某个位置,检测它们有没有回环。
这种方法的思路很直观。(1)但是由于累计误差的存在,我们往往没法正确地发现“运动到了之前的某个位置附近”这个事实,以至于回环检测也无从谈起。(2)并且回环检测的目标就是发现“相机回到之前位置的事实”,从而消除累计误差。而在此方法中,我们需要假设的就是“相机回到之前的位置”。所以,逻辑上存在问题。
2)基于外观(Appearance based):和前端(前端可以向其提供特征点)、后端无关,仅根据两副图像的相似性来确定回环检测的关系。
总结:基于外观的回环检测能在不同的场景下有效工作,是视觉SLAM中的主流方法,并被应用到不同的系统中。
基于外观的回环检测:
核心问题:如何计算图像间的相似性?
由于像素灰度很容易受到环境光照和相机曝光的影响,而且即使光照不变,仅是相机视角发生变动,像素值也会发生大的变动,因此我们不能简单地考虑“将两副图像的灰度值相减”来评估图像是相似。
考虑使用的方法:1)对两幅图像的特征点进行匹配,只要匹配数量大于一定值,就认为出现了回环。(存在的问题:特征匹配比较费时,当光照变化时特征描述可能不稳定等)。
2)利用词袋模型。我们通常使用这种方法
评估回环检测好坏的标准:准确率(P)、召回率(R)
相关知识点:假阳性(False Positive,事实上不是回环,但算法给出的是回环)又称为感知偏差(Perceptual Aliasing);假阴性(False Negative,事实上是回环,但算法给出的不是回环)又称为感知变异(Perceptual Variability)
评估标准:TP(true positive,真阳性。事实和算法吻合,是回环)、TN(true negative,真阴性。事实和算法吻合,不是回环)、FP、FN。我们希望TP、FP尽量高,TN、FN尽量低
准确率(Precision):表示的是算法提取的所有回环中确实是真实回环的概率。Precision=TP/(TP+FP)
召回率(Recall):表示的是在所有真实回环中被正确检测出来的概率。Recall=TP/(TP+FN)
P和R是一对矛盾的统计量,想一想为什么这样说?
在SLAM中,我们对准确率的要求更高,对召回率的要求较为宽容。
词袋模型:
词袋(Bag-of-Words(BoW)),目的是用“图像上有哪几种特征”来描述一副图像。强调的是words的有无,而不关心word出现的顺序。
利用词袋模型判断图像间相似性的步骤:
1)生成字典:根据K-means,我们可以把已经提取的大量特征点聚类成一个含有k个单词的字典。
2)使用一种k叉树来表达字典。我们构建一个深度为d,每次分叉均为k的树,训练字典时,逐层使用K-means聚类。这种树结构可容纳k^d个单词。当在字典中查找单词时,只需要将它与树结构中每个中间节点的聚类中心比较,总共做d次比较,就可找到对应的单词。
实践:演示如何训练生成一个ORB字典。代码如下:
1 #include "DBoW3/DBoW3.h" 2 #include <opencv2/core/core.hpp> 3 #include <opencv2/highgui/highgui.hpp> 4 #include <opencv2/features2d//features2d.hpp> 5 #include <iostream> 6 #include <vector> 7 #include <string> 8 9 using namespace std; 10 using namespace cv; 11 12 //本程序演示了如何根据data/目录下的十张图片训练字典 13 int main(int argc,char** argv) 14 { 15 cout<<"reading images..."<<endl; 16 vector<Mat> images; 17 for(int i=0;i<10;++i) 18 { 19 string path="/home/cc/slambook/ch12/data/"+to_string(i+1)+".png"; 20 //cout<<path<<endl; 21 images.push_back(imread(path)); 22 } 23 24 //detect ORB features 25 cout<<"detecting ORB features..."<<endl; 26 Ptr<Feature2D> detector=ORB::create(); 27 vector<Mat> descriptors; 28 for(Mat& image:images) 29 { 30 vector<KeyPoint> keypoints; 31 Mat descriptor; 32 detector->detectAndCompute(image,Mat(),keypoints,descriptor); 33 descriptors.push_back(descriptor); 34 } 35 36 //create vocabulary 37 cout<<"creating vocabulary..."<<endl; 38 // DBoW3::Vocabulary vocab;//默认k=10,d=5 39 //我们也可以指定树的分叉数量及深度 40 const int k=9;//配置分叉数为9 41 const int L=3;//配置深度为3 42 // const WeightingType weight = TF_IDF; 43 // const ScoringType score = L1_NORM; //使用L1范数计算word之间的分数差 44 // const ScoreingType score=LI_NORM;//使用LI范数计算word之间的分数 45 // DBoW3::Vocabulary vocab(k,L,weight,score); 46 DBoW3::Vocabulary vocab(k,L); 47 vocab.create(descriptors); 48 cout<<"vocabulary info: "<<vocab<<endl; 49 vocab.save("vocabulary.yml.gz"); 50 cout<<"done"<<endl; 51 return 0; 52 }
实际BoW使用时字典往往是从更大的数据集生成的。而且最好是来自与目标环境类似的地方。字典的规模越大意味着字典中单词量越丰富,就越容易找到与当前图像对应的单词,所以我们通常使用较大规模的字典,但是也不能大到超过计算能力和内存。
如果我们想要获得更好的效果,可以自己训练一个更大的字典,或者使用别人训练好的,但是一档要注意字典使用的特征类型是否是一致的。
2)利用字典计算两幅图像间的相似性
TF-IDF(Term Frequency-Inverse Document Frequency),频率-逆文档频率。对于TF部分的思想是:某单词在一副图像中越常出现,它的区分度就越高。IDF部分的思想是:某单词在一副图像中出现的频率越低,它的区分度就越高。
IDF-统计某个叶子节点![]() 中特征数量相对于所有特征数量的比例:
中特征数量相对于所有特征数量的比例: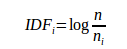 ,其中n表示所有特征的数量,
,其中n表示所有特征的数量,![]() 表示某个叶子节点
表示某个叶子节点![]() 中特征数量。
中特征数量。
TF-指某个特征在单副图像中出现的频率: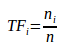 ,其中n表示图像A中一共出现的单词数目,
,其中n表示图像A中一共出现的单词数目,![]() 表示图像A中单词
表示图像A中单词![]() 出现的次数。
出现的次数。
=>![]() 的权重
的权重 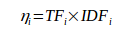
对于图像A,我们可以定义组成它的Bag-of-Words:A={(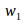 ,
,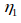 ),(
),(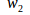 ,
,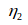 ),… ,(
),… ,(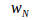 ,
,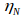 )}=
)}=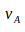 。我们就用这个向量描述一副图像A,是一个稀疏的向量,它的非零部分指示了图像A中含有哪些单词,而这些部分的值为TF-IDF的值。
。我们就用这个向量描述一副图像A,是一个稀疏的向量,它的非零部分指示了图像A中含有哪些单词,而这些部分的值为TF-IDF的值。
利用词袋模型计算两幅图像间的相似度的方式1:
实践2:我们利用实践1中生成的字典,计算图像中的相似度。代码如下:
1 #include "DBoW3/DBoW3.h" 2 #include <opencv2/core/core.hpp> 3 #include <opencv2/highgui/highgui.hpp> 4 #include <opencv2/features2d/features2d.hpp> 5 #include <iostream> 6 #include <vector> 7 #include <string> 8 9 using namespace std; 10 using namespace cv; 11 12 //本程序演示了根据前面训练的字典计算相似性评分 13 int main(int argc,char** argv) 14 { 15 //read the images and database 16 cout<<"reading database..."<<endl; 17 DBoW3::Vocabulary vocab("/home/cc/slambook/ch12/build/vocabulary.yml.gz"); 18 if(vocab.empty()) 19 { 20 cerr<<"Vocabulary dose not exist."<<endl; 21 return 1; 22 } 23 cout<<"reading images..."<<endl; 24 vector<Mat> images; 25 for(int i=0;i<10;i++) 26 { 27 string path="/home/cc/slambook/ch12/data/"+to_string(i+1)+".png"; 28 images.push_back(imread(path)); 29 } 30 31 //detect ORB features 32 cout<<"detecting ORB features..."<<endl; 33 Ptr<Feature2D> detector=ORB::create(); 34 vector<Mat> descriptors; 35 for(Mat& image:images) 36 { 37 vector<KeyPoint> keypoints; 38 Mat descriptor; 39 detector->detectAndCompute(image,Mat(),keypoints,descriptor); 40 descriptors.push_back(descriptor); 41 } 42 43 //images: 44 cout<<"comparing images with images "<<endl; 45 for(int i=0;i<images.size();i++) 46 { 47 DBoW3::BowVector v1; 48 vocab.transform(descriptors[i],v1); 49 for(int j=i;j<images.size();j++) 50 { 51 DBoW3::BowVector v2; 52 vocab.transform(descriptors[j],v2);//i->j 53 double score=vocab.score(v1,v2); 54 cout<<"image "<<i<<" vs image "<<j<<":"<<score<<endl; 55 } 56 cout<<endl; 57 } 58 59 //or with database: 60 cout<<"comparing images with database"<<endl; 61 DBoW3::Database db(vocab,false,0); 62 for(int i=0;i<descriptors.size();i++) 63 { 64 db.add(descriptors[i]); 65 } 66 cout<<"database info: "<<db<<endl; 67 for(int i=0;i<descriptors.size();i++) 68 { 69 DBoW3::QueryResults ret; 70 db.query(descriptors[i],ret,4);//max result=4 71 cout<<"searching for image "<<i<<" returns "<<ret<<endl<<endl; 72 } 73 cout<<"done."<<endl; 74 }
实验结果:
各图像之间的得分为:
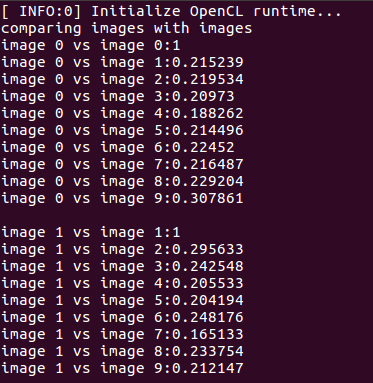
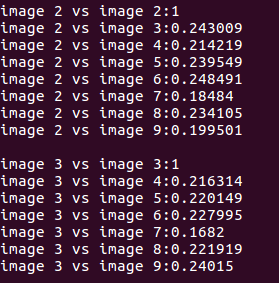
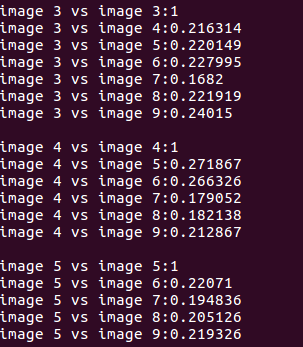
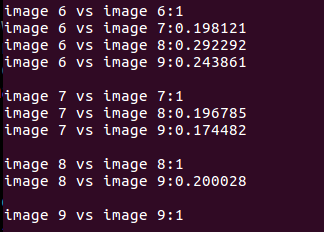
在数据库查询时,DBoW对上面的分数进行排序,给出最相似的结果:
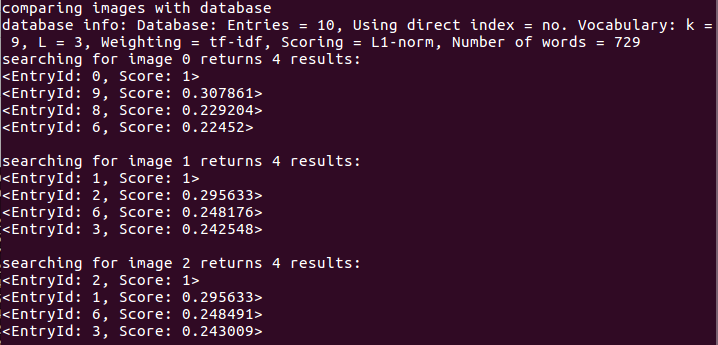
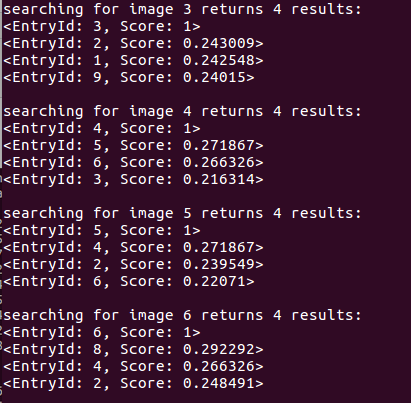
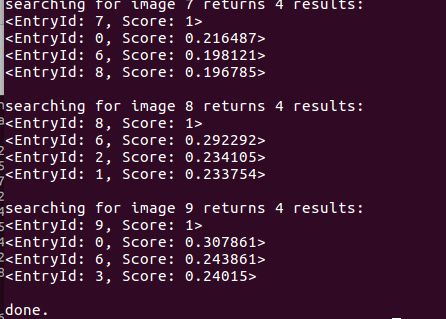
由此可知,明显相似的是图像1和图像10(分别对应0和9),但其相似评分也只有0.307861,而其他图像间的相似评分大约为0.2左右,在数值上这个差别不是十分明显。
考虑原因:在机器学习领域,如果代码没有出错,而结果不满意,我们首先怀疑“网络结构是否够大,层数是否够深,数据样本是否够多”等。
在教材中,训练了一个样本更多的字典,得到的结果由于上面这个结果。由此说明增大字典的训练样本是有益的,同理,也可以增大字典的规模(即增大L、K)。
利用词袋进行回环检测的缺点:1)算法完全依赖于外观而没有利用其他任何的几何信息i,会导致外观相似的图像易被当作回环
2)由于词袋不在乎单词顺序,只在意单词有无的表达方式,更容易引发感知偏差。
所以要在检测到回环之后进行验证,方式有:
1)时间上的一致性检测:如果能在一段时间中一直检测到回环,才认为是正确的回环。
2)空间上的一致性检测:对回环检测到的两个帧进行匹配,估计相机的运动。然后再把运动放到之前的Pose Graph中,检查与之前的估计是否有很大的出入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号