

cc = ('''Counting stars Lately I've been, I've been losing sleep
Dreaming 'bout the things that we could be
But baby I've been, I've been prayin' hard
Said no more counting dollars We'll be counting stars
Yeah, we'll be counting stars I see this life Like a swinging vine
Swing my heart across the line In my face is flashing signs Seek it out and ye shall find
Old, but I'm not that old Young, but I'm not that bold And I don't think the world is sold
I'm just doing what we're told I, feel something so right But doing the wrong thing
I, feel something so wrong But doing the right thing I could lie, could lie, could lie
everything that kills me makes me feel alive Lately I've been, I've been losing sleep
Dreaming 'bout the things that we could be Baby I've been, I've been prayin' hard
Said no more counting dollars We'll be counting stars Lately I've been, I've been losing sleep
Dreaming 'bout the things that we could be Baby I've been, I've been prayin' hard Said no more counting dollars
We'll be, we'll be counting stars I feel the love And I feel it burn Down this river every turn
Hope is a four letter word Make that money Watch it burn Old, but I'm not that old
Young, but I'm not that bold And I don't think the world is sold I'm just doing what we're told
I, feel something so wrong But doing the right thing I could lie, could lie, could lie
Everything that drowns me makes me wanna fly Lately I've been, I've been losing sleep
Dreaming 'bout the things that we could be Baby I've been, I've been prayin' hard
Said no more counting dollars We'll be counting stars Lately I've been, I've been losing sleep
Dreaming 'bout the things that we could be Baby I've been, I've been prayin' hard
Said no more counting dollars We'll be, we'll be counting stars Take that money And watch it burn Sink in the river
''')
cc = cc.replace('.', ' ')
ccList = cc.split()
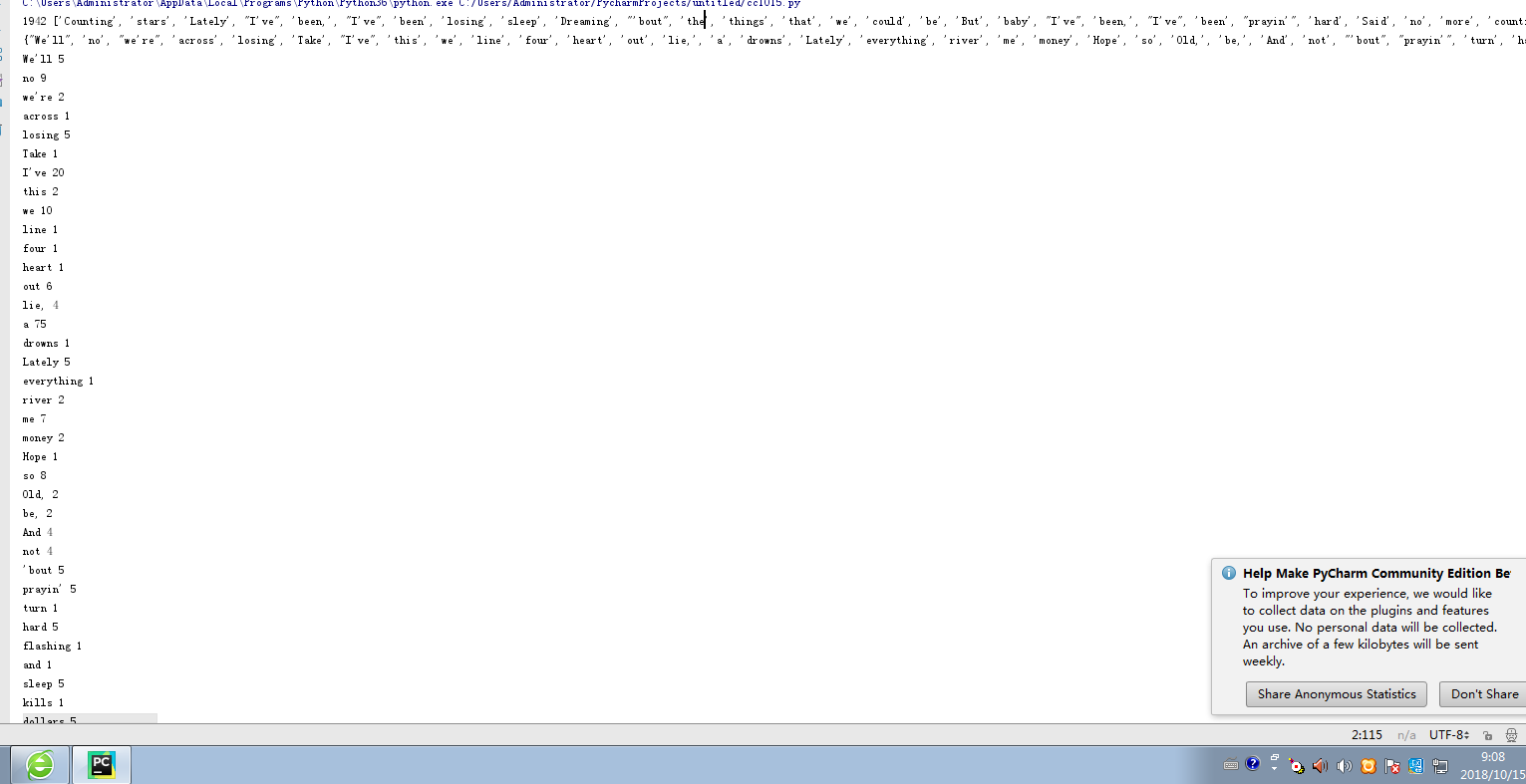
print(len(cc), ccList) # 分隔一个单词并统计英文单词个数
ccSet = set(ccList) # 将列表转化成集合,再将集合转化成字典来统计每个单词出现个数
print(ccSet)
strDict = {}
# for star in ccSet:
# strDict[star] = ccList.count(star)
# print(strDict, len(strDict))
for star in ccSet:
strDict[star]=cc.count(star)
for key in ccSet:
print(key,strDict[key])
wclist=list(ccSet.items())
print(wclist)
def takeSecond(elem):
return elem[1]
wclist.sort(key=takeSecond,reverse=True)
print(wclist)
#列表的遍历
cclist = ['wqdq','dqd','Awd',313,'小四','dqd']
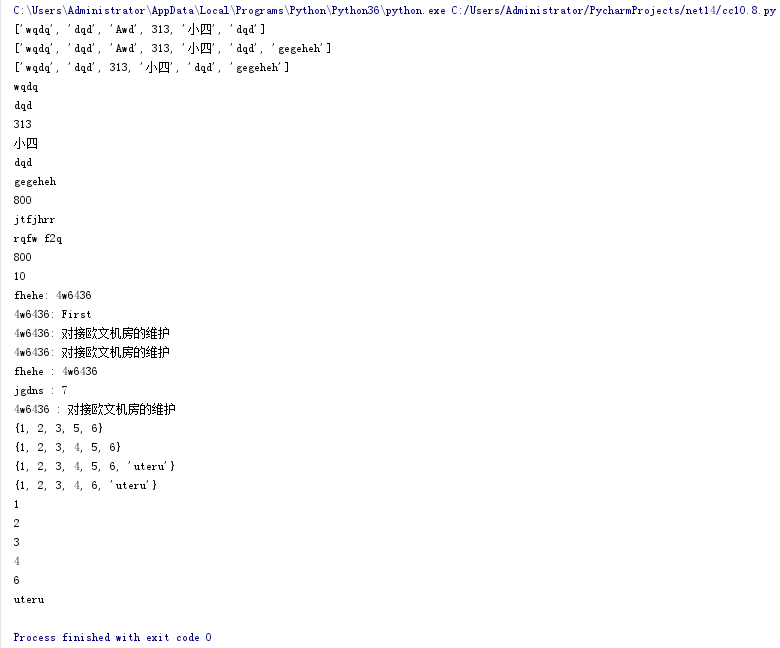
print(cclist)
cclist.append('gegeheh')
print(cclist)
cclist.pop(2)
print(cclist)
for i in cclist:
print(i)
#元组的遍历
tuple = ('jtfjhrr','rqfw f2q',800,10)
print(tuple[2])
for i in tuple:
print(i)
#字典的遍历
dic = {'fhehe': '4w6436', 'jgdns': 7, '4w6436': 'First'}
print('fhehe:' , dic['fhehe'])
print('4w6436:', dic['4w6436'])
dic['4w6436'] = 8;
dic['4w6436'] = "对接欧文机房的维护"
print('4w6436:', dic['4w6436'])
print('4w6436:', dic['4w6436'])
for key in dic:
print(key,':',dic.get(key))
#集合的遍历
a = set([1,2,3,6,5])
print(a)
a.add(4)
print(a)
a.add('uteru')
print(a)
a.remove(5)
print(a)
for i in a:
print(i)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号