
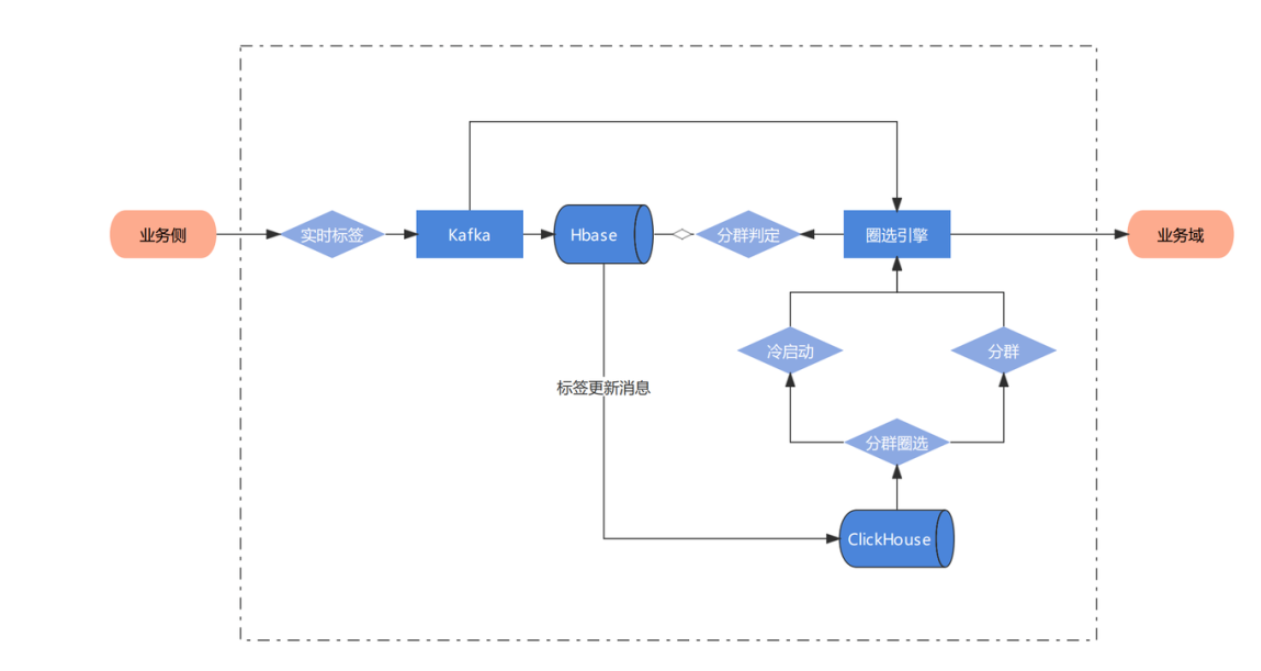
发现了ClickHouse依然存在了一定的局限
-
缺少完整的upsert和delete操作
-
多表关联查询能力弱
-
集群规模较大时可用性下降(对字节尤其如此)
-
没有资源隔离能力
-
ReplacingMergeTree引擎只支持数据的更新,并不支持数据的删除。只能通过CollaspingMergeTree来实现数据清除,通过不同的表引擎分别提供更新删除能力会让系统复杂度进一步提升。
-
ReplacingMergeTree中的去重是 Merge 触发的,在刚导入的数据时是不去重的,过一段时间后才会在分区内去重。
-
1. 原生ClickHouse选择的技术方案
原生ClickHouse的更新表引擎ReplacingMergeTree使用Merge on Read的实现逻辑,整个思想比较类似LSMTree。对于写入,数据先根据key排序,然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。
同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最新版本的值,所以叫merge on read方案。原生ClickHouse ReplacingMergeTree用的就是这种方案。
大家可以看到,它的写路径是非常简单的,是一个很典型的写优化方案。它的问题是读性能比较差,有几方面的原因。首先,key-based merge通常是单线程的,比较难并行。其次merge过程需要非常多的内存比较和内存拷贝。最后这种方案对谓词下推也会有一些限制。大家用过ReplacingMergeTree的话,应该对读性能问题深有体会。
这个方案也有一些变种,比如说可以维护一些index来加速merge过程,不用每次merge都去做key的比较

 浙公网安备 33010602011771号
浙公网安备 33010602011771号