

于函数的概念,在此不多作解释。简单来说,函数就像是一个暗箱,把计算过程封装在暗箱中,再次调用函数时,只需要传入必要的参数,就能按照既定的规则返回结果。
在M语言中,函数主要有内建函数,比如Text.From这种系统自带的;自定义函数,形如(x)=>x+1这种;以及参数函数,即函数内参数类型为function的,function就是函数的意思了。
我们先来看自定义函数,比如fx = (x)=>x+1。创建一个名为fx的函数,需要一个参数x,传入参数后返回结果为x+1,比如fx(5),将5带入函数,返回结果为6,这很容易理解。
关于自定义函数,之前在《自定义函数》中已经讲过一些供参考。
再来看一个简单的例子:点击添加列-自定义列,直接输入1,点击确定。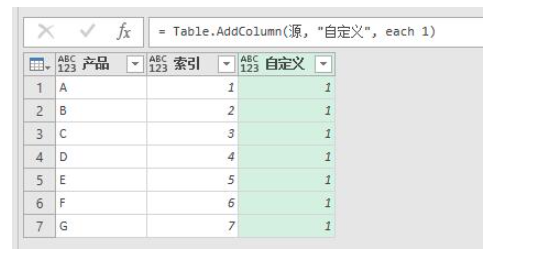
我们看到Table.AddColumn的第三参数,虽然我们输入的是1,但是系统自动在1前面加上了一个each。
那么问题来了,这个each是什么东西?
再看一眼Table.AddColumn第三参数的类型,显示为function。单独一个1是number,加个each就变成function了,这个怎么理解?
我们单独在编辑栏里输入each 1看一下: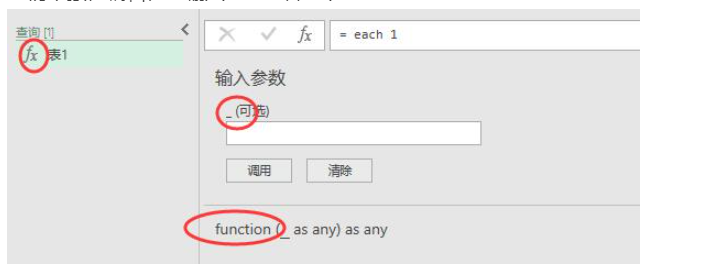
发现这么写并没有报错,并且底部以及左侧的图标都表明这是一个function。
我们注意到还给了一个可选参数为_,这个_又是什么?
在此情况下,无论我们输入_等于什么,返回的结果都是1,因为_并没有参与函数的运算,于是把_加入右边的表达式中试一下,fx=each _+1: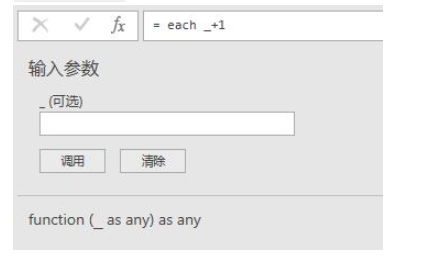
此时发现,当我们给任意一个数字时,返回的结果都会是我们给的参数+1,比如fx(5),返回结果为6。
咦,这不正是本文开头所讲的自定义函数的效果么?
没错,当自定义函数只有一个参数时,(x)=>x的写法完全与each _等价。
所以,可以把刚才添加列中的第三参数里的each 1,写成(x)=>1,效果完全一样。
OK,这个理解了我们继续往下看。
如果刚才添加列输入的不是1而是_呢?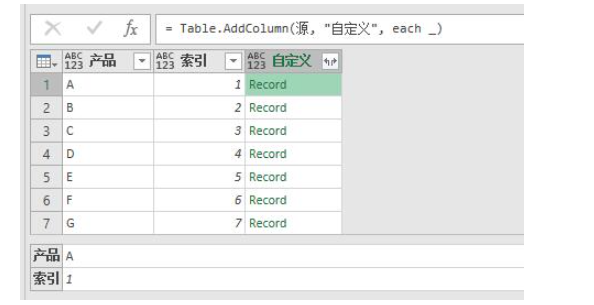
我们已经知道了each _就相当于(x)=>x,而(x)=>x看上去好像更容易理解一些,就是你传入的是什么,返回的还是什么。
那么在= Table.AddColumn(源, "自定义", each _)中,传入的是什么?是源这张表,但是因为上下文的原因,这张表被拆分成了很多行,所以每一行只返回当前行的所有列,结果为一个record。
而record又能深化出其中的字段,比如我们要其中[索引]字段下的值,那么可以_[索引],第一行返回的结果为1。
所以我们平时添加列,比如要[索引]*10,公式为= Table.AddColumn(源, "自定义", each [索引]*10),而在这个[索引]的前面,实际上是省略了一个_的: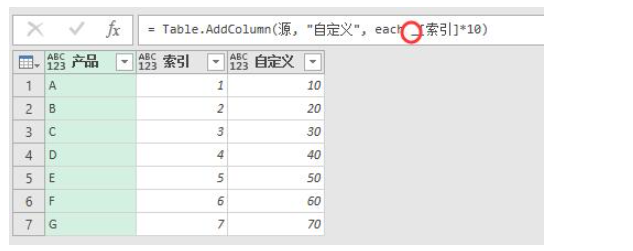
当然如果你用的是each,此处的_可以省略,但是如果你写成(x)=>的形式,就不能省略,要写成= Table.AddColumn(源, "自定义", (x)=> x[索引]*10)。
再说一遍,当函数传入的参数只有一个时,each _与(x)=>x等价。那么既然等价,什么时候该用什么呢?
这个问题问得好!其实两个都能用,用什么那只是习惯问题。
each是语法糖,一般来说,当函数作为参数的时候习惯用each _,这样能够提高代码的可读性;而当单独定义一个函数的时候习惯用(x)=>x。
但是有一种情况比较特殊,在自定义函数那一篇中,我介绍过一个形如lambda表达式的匿名函数来实现累计求和,很多人表示不理解。再来回顾一下: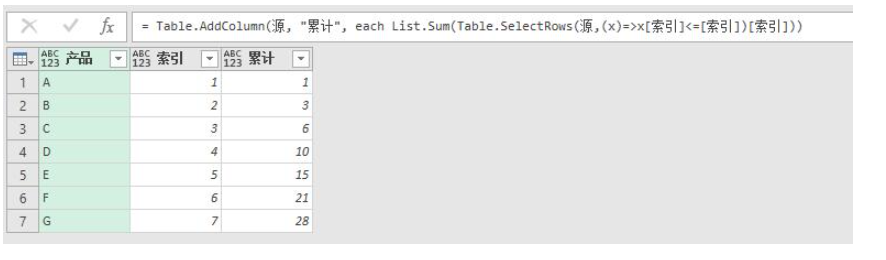
整体的思路就是,先筛选出表中[索引]<=当前行的索引的所有记录,比如当前行索引为3,那么得到的就是索引为1,2,3的三行,然后对筛选表中的[索引]列求和,即可得到累计求和。 先撇开求和不谈,先来看筛选表,刚才说过这里的<=[索引]实际上省略了_,我们先加上,公式为= Table.AddColumn(源, "累计", each Table.SelectRows(源,(x)=>x[索引]<=_[索引]))。
其中用到两个函数Table.AddColumn和Table.SelectRows,先单独看下这两个公式:
= Table.AddColumn(源, "累计", each 源)
= Table.SelectRows(源,each [索引]<=3])
而现在我们要的是把前面公式中最后的源,传递到后面公式最后的3的位置,所以要把两个公式嵌套在一起,而这两个函数中都有类型为function的参数,所以如果都用each _,到后面就会变成each _[索引]<=_[索引],那么就会指代不明,你说这个_到底是前面的函数里的呢,还是后面函数里的呢?而如果这两个_表示的是同一个意思即<=左右两边相等,那么这个表达式的结果恒为true,返回的结果就会是整张表,显然不是我们想要的。 所以,在遇到两个或多个函数的参数互相干扰的时候,需要使用不同的参数将它们区分开来。 当然除了以上的写法,你也可以写成以下的形式,把三个放一起比较下区别:
= Table.AddColumn(源, "累计", each Table.SelectRows(源,(x)=>x[索引]<=_[索引]))
= Table.AddColumn(源, "累计", (x)=> Table.SelectRows(源,each _[索引]<=x[索引]))
= Table.AddColumn(源, "累计", (x)=> Table.SelectRows(源,(y)=>y[索引]<=x[索引]))
这三种写法完全等价。
最难的又理解了,我们再回过头看简单的以便彻底理解。当时还给了一个分步创建自定义函数的写法:
let
fx =(x)=>Table.SelectRows(源, each [索引] <= x),
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
筛选 = Table.AddColumn(源, "累计",each fx([索引]))
in
筛选
这样应该都能理解,那如果我们把第一步的自定义函数改一下呢?改成fx = each Table.SelectRows(源, (x)=> x[索引] <= _),最后的结果完全一样。
那我们第三步里写的是fx([索引]),fx是自定义函数的函数名,而fx又等于第一步等号右边的表达式,那直接用表达式来替换fx可不可以呢?fx([索引])传入的参数为[索引],那么在表达式中把的形参_替换为实参[索引],写成= Table.AddColumn(源, "累计",each Table.SelectRows(源, (x)=> x[索引] <= _[索引]))
看!替换完得到的结果,不就是我们上面写的那个吗?
再反过来,你甚至可以把_[索引]写到自定义函数里,第一步写成fx = each Table.SelectRows(源, (x)=> x[索引] <= _[索引])。这是名为fx的函数,而第三步Table.AddColumn的第三参数要的就是function,于是你可以直接给一个函数,写成筛选 = Table.AddColumn(源, "累计",fx),结果也完全正确。
所以当函数需要传入的参数为当前上下文本身且不需要其他参数的时候,你可以直接丢一个函数名,连each都不用,比如= List.Transform({1..5},Text.From)。因为each Text.From(_),意思就是传递一个参数然后调用函数,那不就还是原来的函数嘛,所以何必多此一举。
除了以上提到的几个函数,在M语言中还有很多函数的参数类型为function,正是由于我们可以对function进行任意的自定义改造,所以你会发现这些函数都比较难理解,但是又有无限的可能,可以从中挖掘到很多常规函数的非常规用法,这也是M语言的魅力所在。
本文介绍了函数的几种形态,以及之间的相互联系与转换。对于初学者来说可能有点绕,但是如果多看几遍并自己动手测试下,把这篇深入理解,将会一通百通。
原文链接: https://pqfans.com/1726.html/comment-page-1#comment-2709

 浙公网安备 33010602011771号
浙公网安备 33010602011771号