
23python多线程、多进程和锁相关
说在前面:
并发和并行:
并发:伪,指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个线程同时执行的效果,但
在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
并行:真,指在同一时刻,有多条指令在多个处理器上同时执行,无论从宏观还是微观来看,二者都是一起执行的。
线程和进程:
线程:
1、进程是供CPU调度的工作的最小单元
2、线程共享进程中的资源
3、每个线程可以分担一些任务,最终完成最后的结果
进程:
1、每个进程都会独立开辟内存
2、进程之间的数据隔离
python多线程:
- 计算密集型操作:效率低。(GIL锁)
- IO操作:效率高(IO操作不占用CPU)
python多进程:
- 计算密集型操作:效率高。(浪费资源)
- IO操作:效率高(浪费资源)
写python时:
IO密集型用多线程 文件/输入输出/socket通信/爬虫
计算密集型用多进程
1、python的多线程的基础使用:
import threading def func(arg): print(arg) t = threading.Thread(target=func, args=(11,)) t.start() print(123)
如上,主线程打印123,子线程打印11。
2、python中的锁:
# GIL锁:全局解释器锁。同一时刻,同一进程中,只允许一个线程被cpu调度
Lock:同步锁。一次允许一个线程通过加锁的代码块, ---无法嵌套,会死锁
RLock:递归锁,与同步锁用法一致。可以嵌套
BoundedSemaphore(N):一次允许n个线程通过加锁的代码块。N是写死的
condition:一次允许x个线程通过加锁的代码块,x可以是动态的
Event:卡住所有,一个都不让过,然后一次全部释放(如需释放后再次全部锁住,需要lock.clear())
---实际工作用应该用的基本上都是Rlock:
# coding:utf-8 import threading import time lock = threading.RLock() v = [] def func(arg): lock.acquire() # 加锁 v.append(arg) time.sleep(0.01) m = v[-1] print(arg, m) lock.release() # 释放锁 for i in range(10): t = threading.Thread(target=func, args=(i,)) t.start() # start的本质不是开始运行线程,而是通知cpu可以进行调度。
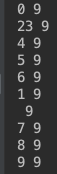
加锁运行结果如下:

不加锁运行结果如下:
3、线程的一些常用操作(不重要):
join:控制主线程等待子线程时间
setDeanon:设置为Ture,主线程不会等待子线程
setName:设置线程名字
threading.current_thread():获取当前线程对象
4、线程池:
实际工作中。一般都是规定线程池的线程数。而不是直接每次调用生成一个线程。用法如下:
from concurrent.futures import ThreadPoolExecutor import time def task(a1, a2): time.sleep(2) print(a1, a2) # 创建一个线程池(最多5个线程) pool = ThreadPoolExecutor(5) for i in range(40): # 去线程池申请线程,让线程执行task函数 pool.submit(task, i, 8)
5、进程。
进程与线程使用方法基本上一致,就是名词变了一下。
线程导入模块:import threading 进程导入模块:import multiprocessing
线程运行:
t = threading.Thread(target=func,args=(xx,))
t.start()
进程运行:
t = multiprocessing.Process(target=func,args=(xx,))
t.start()
多线程的Rlock锁(唯一的区别就是创建):
多线程: lock = threading.RLock()
多进程: lock = multiprocessing.RLock()
线程池(就创建的时候有区别):
pool = ThreadPoolExecutor(5)
进程池:
pool = ProcessPoolExecutor(5)
----
以上就是线程与进程这几天的总结了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号