浅谈哈希表
最近刚刚看到了阿尔法狗的大爷——阿尔法元把阿尔法狗打的不知所措。感叹于AI的迅速发展的同时也越发看到技术的魅力。值得我们深入思考的是新一代的阿尔法元,完全靠着无师自通的左右双手互搏术,经过多次的训练,然后完爆了阿尔法狗。DeepMind团队发现了一个令人窒息的事实那就是:人类把阿尔法狗教坏了!要知道阿尔法狗是学习了人类的三千万棋局的机器,然而它被无师自通的阿尔法元打败了。这带给我们一个更深的思考,人类活动所产生的庞大无比的数据是否还具有那么重要的作用。在未来的发展中,我们究竟应该如何看待人类经验的作用。
尽管阿尔法元的能力让人无比震撼,但是目前来说我们所产生的大数据依旧是一笔巨大的财富。或许未来AI的全局最优能力会是主流,当下来说数据依旧是我们的生命。(好吧好像和标题扯远了,只是感觉阿尔法元有点厉害。)那么如此庞大的数据,大家有没有想过它们是如何保存的呢?大数据的时代,数据结构的能量也变得越发的惊人了。说到数据结构我们首先能够想到就是数组和链表。这两个经典的数据结构依旧有着不可动摇的地位。
数组
这应该是最最常用的一个结构了,不管在什么时候数组都有着巨大的魅力。但是数组的特点我们也都清楚:结构简单、操作方便。一般来说如果能够知道下标就能够很快的找到所需的元素。但是我们想象一下这样的场景,如果数组里面储存的数据是无序的而且数据量很大的话,那么最糟糕的情况下查找需要的时间复杂度是O(n)。查找的效率就很低。而且数组的扩展也很麻烦,需要开辟的新数组并复制一份原来的数据,资源的耗费非常大。
总的来说如果数据量小,数据存储比较顺序的话数组是很不错的选择。
链表
链表最大的特点就是可以动态拓展大小。如果经常要增减数据的话,链表当然是不二之选。但是链表同样有一个致命的缺点,那就是链表的查找很麻烦。极端情况下单链表需要从表头查找到末尾。
以上的两种存储方式是连续数据结构和离散数据结构的两种代表方式。但是他们又有各自适用的场景。然而对于数据量十分庞大的数据来说,这两种结构都是效率很低的。(想象一下QQ就知道了,假设有一亿的QQ号的需要查找和添加,这两种数据结构的效率都会很低)既然如此有没有一种数据结构能够兼容以上两种的优缺点,使得数据的查找和添加的时间复杂度和空间复杂度都趋于一个常数呢?答案当然是肯定的,那就是——哈希表。
哈希表
哈希表是一种以key和value也就是键值对作为基本结构的一种存储结构。实际上哈希表可说是一种由key到value的映射。
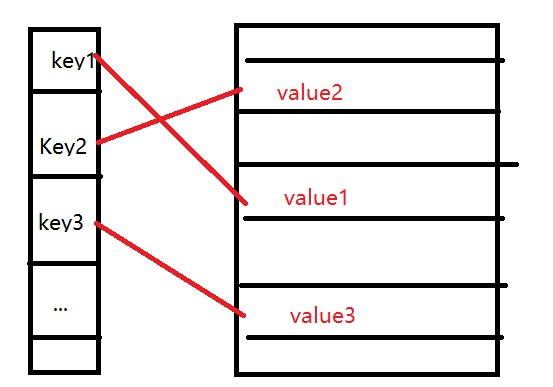
这种映射的好处就是可以把查找的时间复杂度降低到一个常数的水平。常用的一种哈希的实现方式就是使用一个链表的数组。由key对表长取模得到数组的下标。当然下标很可能会产生冲突。解决冲突的办法有很多。这里我们使用的是链地址法。也就是如果下标是相同的,我们就加到数组下标对应的链表中。
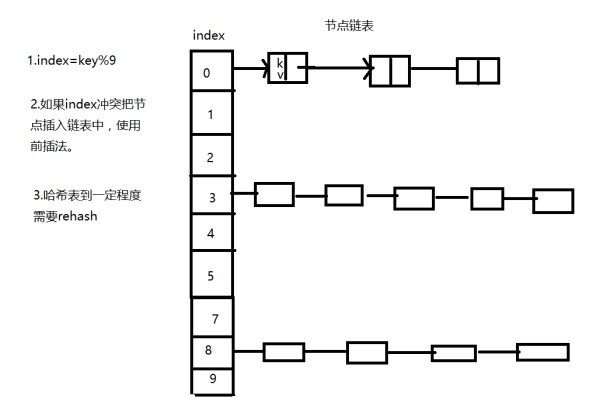
我们来设想一下极端的情况,如果数据选的“很好”,每一个key对应一个下标,那么整个哈希表可能会变成一个数组。如果数据选的很“不好”,那么这个哈希表就可能会变成一个单链表。因此我们要注意的是:key值需要是一个比表长大得多的数字,另外表长应该为一个质数或者说哈希函数index=key%m,中的m值需要是一个质数。这样才能更好的发挥哈希表的特性。
为了避免因哈希表后面的链表过长从而降低哈希表的效率(查找的时间复杂度),因此哈希表通常会设定一个阈值,当表中的key值数量超过这个阈值的时候需要扩大数组的长度(对应上图就是把数组长度变成18),重新计算每个元素的index值。这个过程就叫做rehash。可以想象rehash也是极其耗费资源的,所以我们应该尽量避免太多次的rehash过程。
下面是我用Java写的一个自定义哈希表(参考了Java Hashtable的源码):


package com.cbs.hash; /** * 定义哈希表的每一个节点 * @author CBS * */ public class Node<K,V> { K key;//key值 V value;//value值 Node<K,V> next;//下一个节点 public Node(){ } public Node(K k,V v){ this.key=k; this.value=v; } } package com.cbs.hash; /** * 自定义哈希表 * @author CBS * */ public class MyHashTable<K,V> { private Node<K,V>[] table; private int count=0;//哈希表长度 private final float f=0.75f;//装载因子 private int index;//数组下标 private int hash;//哈希值 //初始化数组长度 @SuppressWarnings("unchecked") public MyHashTable(){ table=new Node[9]; } /** * 添加方法 * @param key * @param value */ public void put(K key,V value){ hash=key.hashCode();//获取哈希值 index = (hash & 0x7FFFFFFF) % table.length;//获取下标值 Node<K,V> node=table[index]; Node<K,V> tem=node; //如果节点已经存在,更新value值 for(;tem!=null;tem=tem.next){ if(hash==tem.key.hashCode() && tem.key.equals(key)){ tem.value=value; return; } } Node<K,V> newNode=new Node<K, V>(key,value); //在链表的表头插入 table[index]=newNode; newNode.next=node; count++; } /** * 查找指定key值下的节点 * @param k * @return key值对应的节点对象 */ public Node<K, V> find(K k){ hash=k.hashCode(); int index = (hash & 0x7FFFFFFF) % table.length; Node<K,V> node=table[index]; Node<K,V> tem=node; for(;tem!=null;tem=tem.next){ if(hash==tem.key.hashCode() && tem.key.equals(k)){ return tem; } } return null; } /** * 更新key值对应的value值 * @param k * @param v */ public void update(K k,V v){ Node<K,V> node=find(k); node.value=v; } /** * 删除指定key值的节点 * @param k */ public void delete(K k){ hash=k.hashCode(); int index = (hash & 0x7FFFFFFF) % table.length; Node<K,V> node=table[index]; Node<K,V> tem=node; for(;tem!=null;tem=tem.next){ if(hash==tem.next.key.hashCode() && tem.next.key.equals(k)){ break; } } Node<K,V> nextNode=find(k); tem.next=nextNode.next; count--; } /** * 获取key值节点下面的value值 * @param k * @return V类型的值 */ public V get(K k){ Node<K,V> Node=find(k); if(Node!=null){ return (V)Node.value; } return null; } public int size(){ return count; } }
个人能力问题,还没有想出来rehash应该怎么写。另外解释一下hashCode方法。这个方法是Object类中的一个方法,也就是Java中所有的类都有这个方法。它是返回一个int值,这个int值唯一标识了一个对象。它一方面是为了便于对象的equals方法的重写,一方面是便于Java中Hashtable的使用。简单的来说就是:在一个程序中,一个对象只有一个唯一的hashCode。
PS:以上纯属个人理解,如有错误,欢迎批评指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号