Raft算法之Leader选举
记录一下对Raft算法的理解,算法的内容比较多,所以准备将算法的全部过程分成四个部分来写。分别是
该文章为第一部分。
Raft算法之Leader选举
简单介绍
首先需要了解Raft中的一个关键词:Term,本文中以下部分简单称为任期。任期通过连续的整数编号表示并且是单调递增的,代表任意长度的一段时间。在网络中所有服务器都有自己的任期编号,在网络中大部分正常运行阶段,所有服务器的任期号都是相同的。
Raft算法中服务器主要分为三种角色:Leader,Follower,Candidate,并且三种角色相互独立,也就是服务器在同一时间内只可能扮演其中一种角色。
Leader:用于对所有用户的请求进行处理。以及之后要说明的日志的复制等等。Follower:不会主动发送消息,只响应来自Leader与Candidate的请求。Candidate:用于选举新的Leader。
在本文介绍的范围内,网络状态分为两种情况:选举阶段,正常运行阶段。(网络状态还可能会有成员变化阶段,但不在本文范围内,所以暂时先不考虑).
并且每一个任期都是以选举阶段开始。但不一定以正常运行阶段结束。在某些情况下一个完整的任期可能全部为选举阶段。如下图:
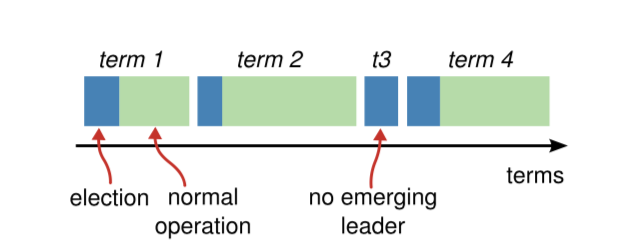
选举阶段->正常运行阶段
在网络初始化时,网络中所有的服务器都以Follower的角色启动。由于Follower只被动接收消息。所以全网中所有服务器都处于等待状态。同时每一个服务器都在本地维护一个计时器。
- 计时器的作用很简单,就是判断当前阶段(选举阶段或正常运行阶段)是否超时。而当计时器超时后,任期将会
所以在网络启动后所有服务器等待指定长度的一段时间过去以后。计时器将会超时。这时候计时器超时的服务器将转换自己的角色为Candidate。进入选举阶段。而进入选举阶段的Candidate将会做以下几件事:
- 将自己的任期号加1.
- 为自己投一票用以选举出新的
Leader。 - 将本地的计时器重置
- 发送投票请求到网络中的其他所有的服务器。
- 等待下一次的计时器超时
同时选举Leader具有以下几点要求:
- 每个服务器在一个任期内只能投一票,并且使先到者先得(即投票给自己收到的第一个请求投票的,满足要求的服务器的请求)
- 请求投票的消息中需要带有请求者所处的当前任期号。
- 投票者只会投票给任期号大于等于自己当前任期号的服务器。
- 关于日志的要求(下一篇文章再介绍)
在选举状态会出现三种结果:
- 自己成功当选
Leader - 网络中其他服务器当选
Leader - 网络中没有服务器当选
Leader
当网络中某一个Candidate接收到网络中大多数成员的投票后,即可将自己的身份转换为Leader。在当选Leader后,该服务器将周期性地发送心跳信息(心跳信息包含成功当选Leader的服务器的当前任期号)到网络中其他服务器。在网络中其他的服务器收到心跳信息后检查心跳消息中的任期号是否大于等于自己的任期号。如果满足该条件的话Candidate将会转换为Follower状态,并重置计时器。而如果任期号小于自己的任期号,服务器将拒绝该心跳消息并继续处于Candidate状态。
第三种情况为网络中没有服务器成功当选Leader。这种情况在当很多Follower同时成为Candidate时会发生。因为当角色转换为Candidate后将会将选票投给自己。从而导致选票被分散开来,没有Candidate可以得到网络中大部分节点的选票。从而没有节点可以成为Leader.这种情况下计时器将再次超时,网络状态将从选举阶段进入下一个选举阶段。同时Candidate将会再次执行上面说明的几件事。
Raft算法采用了随机选举超时机制来避免出现这种情况。即当计时器超时后,服务器将随机延迟指定的时间后才进入选举阶段。
由于随机延迟的原因,将降低服务器在同一时间选举超时的情况,可以有效避免选票分散的情况。
正常运行阶段->选举阶段
当Leader成功选举之后,将周期性发送心跳消息到网络中其他服务器。同时其他服务器将转换自己的角色为Follower。并且每次收到心跳消息后都会重置自己的计时器,防止超时再次进入选举阶段。
而如果Leader因为特殊情况崩溃时,网络中的其他服务器将不再接收到心跳消息,在等待指定时间后计时器将会超时,从而再次进入选举阶段。
- 而如果
Leader崩溃时间较短,可以在其他服务器计时器超时之间恢复,并发送心跳消息,网络仍然可以恢复为Leader崩溃之前的状态。 - 如果
Leader崩溃时间较长,在网络中已有新的Leader选举产生后恢复,由于旧的Leader任期号将小于新的Leader,在旧的Leader接收到新的Leader发送的心跳消息后则会变为Follower状态。
总结
三种角色的转换情况:
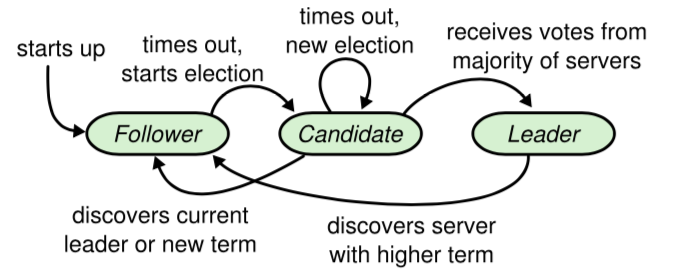
Candidate
服务器角色变为Candidate后:
- 将自己的任期号加1.
- 为自己投一票用以选举出新的
Leader。 - 将本地的计时器重置
- 发送投票请求到网络中的其他所有的服务器。
- 等待下一次的计时器超时
- 当接收到心跳消息(心跳消息中的任期号大于等于自己的任期号)后,变为
Follower状态。 - 计时器超时,再次执行上面的5件事。
- 当自己接收到大多数选票后,变为
Leader状态。
Follower
服务器角色变为Follower后:
- 等待
Leader或者Candidate发送消息给自己。- 如果是心跳消息(心跳消息中的任期号大于等于自己的任期号),则重置计时器。
- 如果是选举消息(选举消息中的任期号大于自己的任期号),则将自己变为
Candidate,任期号更新为选举消息中的较大的任期号。重置计时器并返回投票响应信息。
- 或者网络处于正常运行状态时,如果收到客户端请求,将会将该请求重定向到
Leader。 - 如果在指定时间间隔内没有收到心跳消息或者是选举消息,则角色变为
Candidate。
Leader
服务器角色变为Leader后:
- 重置计时器,并周期性发送心跳消息(带有自己的任期号)到网络中其他服务器。
- 等待客户端请求消息。
下一篇文章:Raft算法之日志复制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号