
字符串操作1-截取和查找-Python
1、转义字符。
print('haha\nhaha') '''
\n: haha haha ''' print('haha\thaha') # \th:haha haha print('haha\\haha') # 如何输出“\”:haha\haha print('haha\'hehehehe\'') # 如何输出单引号:haha'hehehehe' print("haha\"h") # 如何输出双引号:haha"h
2、字符串保留区和索引
同一个字符串的变量地址是一样的,字符串保留区里面的不会保留重复的字符串。字符串里面的每一个字符都有一个索引。
查看变量的地址:print(id(s1))
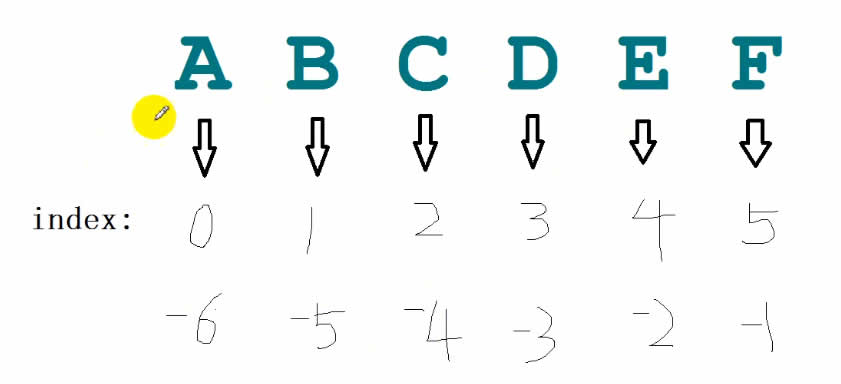
从上图中可以知道,字符串索引机制有两种:
(1)0~len(s)-1 (2) -len(s)~-1
3、截取字符串。
(1)通过索引来截取字符串:
s1 = 'ABCDEFG' print(s1[0]) # A print(s1[5]) # F print(s1[-1]) # G
(2)通过切片来截取字符串:
''' 切片:字符串,列表 格式:字符串变量[start:end] 字符串变量[start:end:step] step: 1、步长 2、方向 step 正数 从左向右取值 负数 从右向左取值 ''' s1 = 'ABCDEFG' print(s1[1:4]) # BCD print(s1[0:5]) # ABCDE print(s1[:5]) # ABCDE print(s1[-3:]) # EFG print(s1[:]) # ABCDEFG print(s1[1:-1]) # BCDEF,不要两头只要中间 print(s1[2:-2]) # CDE,不要两头只要中间 print(s1[:-1:2]) # ACE # 当step为负值时 print(s1[::-1]) # GFEDCBA print(s1[::-2]) # GECA print(s1[0:6:-2]) # 没有取到值 print(s1[6::-2]) # GECA
3、字符串常见操作。
*获取长度:len
*查找内容:find,index,rfind,rindex
*判断:startswith,endswith,isalpha,isdigit,isalnum,isspace
*计算出现次数:count
*替换内容:replace
*切割字符串:split,rsplit,splitlines,partition,rpartition
*修改大小写:capitalize,title,upper,lower
*空格处理:ljust,rjust,center,lstrip,rstrip,strip
*字符串拼接:join
这Python里面字符串是不可变的,所有字符串相关方法,都不会改变原有的字符串,都是返回一个结果,这这个新的返回值里保留了执行后的结果!
关于查找的实例:
path = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png' # find:从左向右查找,只要遇到一个符合要求的则返回位置,如果没有找到符合要求的则返回-1 # 查找 _, i = path.find('_') print(i) # 30 # 查找图片的名字 image_name = path[i - 4:] print(image_name) # PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png print(path.find('#')) # -1 # rfint:从右向左查找 # 查找 . i = path.rfind('.') print(i) # 63 # 找到图片的格式 geshi = path[i:] print(geshi) # .png # count:统计字符的个数 # 统计.的个数 print(path.count('.')) # 3 # index和find差不多,只是index如果没有找到字符串会报错 # path.index('#') ''' Traceback (most recent call last): File "D:/Project/python/first.py", line 25, in <module> path.index('#') ValueError: substring not found ''' # 查找一个词 PCtm,find返回第一个字母的位置 print(path.find('PCtm')) # 26

 浙公网安备 33010602011771号
浙公网安备 33010602011771号