福大软工1816 · 第五次作业 - 结对作业2
本次作业队友:
031602501: 结对队友博客,
同名仓库Github,
本次作业博客链接
软工实践第三次作业-结对项目2
简要目录:
- Step1 · 结对信息
成员信息
具体分工
代码规范
PSP表格
- Step2 · 解题思路与设计实现
爬虫使用
代码组织与内部实现设计(类图)
关键算法及流程图
关键代码解释
- Step3 · 附加题设计与展示
设计创意独到之处
实现思路
实现成果展示
- Step4 · 测试与优化
性能分析与改进
单元测试
- Step5 · 结对过程
代码签入记录
遇到的代码模块异常或结对困难及解决方法
评价队友
学习进度条
- Step6 · 附件
Step1 · 结对信息:
成员信息:
具体分工:
- 说明:在各个方面设计的思路共同讨论的前提下大概分工为:
- 蔡宇航:
爬虫的实现(爬取所需要的资源)
代码复审、测试(单元测试)
- 陈柏涛:
界面的实现(与原型相仿的交互性界面)
基本功能(词频统计)代码的实现
代码规范:
-
我们一起制定了代码规范
结对制定的代码规范见:
博客戳这里! -
敲重点!
多交流、多沟通是最好的规范。
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 2630 | 3000 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 480 |
| · Design Spec | · 生成设计文档 | 120 | 120 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 90 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 1200 | 1500 |
| · Code Review | · 代码复审 | 200 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 480 | 540 |
| Reporting | 报告 | 100 | 130 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| · | 合计 | 2760 | 3160 |
Step2 · 解题思路与设计实现
解题思路:
- 大致的解题思路在下方关键算法已介绍,这里来说说一些数据结构的选择的精巧之处:
map和hash_map的取舍博客在这里!
爬虫使用:
- 使用了java实现爬虫,用python再次爬取数据,将二者爬取结果进行文本对比,以确保结果正确性。(python仅用来验证)
- java实现设计思路介绍(以下介绍基本功能的爬虫实现过程):
- 知识点:
URL(Uniform Resource Location),即Web上的文件提供的唯一地址,可以叫做统一资源定位器。- 使用的函数方法:
1.使用java.net.URL类的构造方法,为该文件创建一个URL对象
2.URL类中定义的openStream()方法来打开输入流和用输入流
3.BufferedReader 是缓冲字符输入流。它继承于Reader。
BufferedReader 的作用是为其他字符输入流添加一些缓冲功能。每次从中读取一部分数据到缓冲中进行操作。(将网页html存入,每次读取一行进行正则匹配获取所有论文url并存于list中)4.同理使用BufferedWriter来辅助文件写入
5.使用java.util.regex包进行正则匹配。其中Pattern类下的compile()方法编译正则表达式,返回正则表达式被编译后的pattern。
而其中的Matcher类没有提供什么静态方法,通过调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。然后使用Matcher对象的.find()函数来判断是否存在匹配。利用group(i)来返回匹配项(i从1开始)
- 获取网页html源码
URL url=new URL("http://openaccess.thecvf.com/CVPR2018.py"); //建立http连接并返回连接对象
BufferedReader bufr=new BufferedReader(new InputStreamReader(url.openStream()));
- 匹配论文url的正则表达式(利用标签唯一确定):
String mail_regex = "<dt class=\"ptitle\"><br><a href=\"(.*?)\">";
- 传入网站URL,正则表达式匹配所有论文的URL存下来
- 遍历所有论文的URL(注意要加上http://openaccess.thecvf.com/),分别进行网页读取,正则表达式匹配各个论文的标题和摘要并按题目要求格式写入txt中
- 注意需用UTF-8格式(论文有各种符号如果用默认编码格式将产生乱码)
- 附加功能爬虫源码见附录
String head = "http://openaccess.thecvf.com/";
List<String> list=getMailsByWeb();
File f = new File("./Spider_result.txt");
if (!f.exists())
{
f.createNewFile();
}
OutputStreamWriter write = new OutputStreamWriter(new FileOutputStream(f),"UTF-8");
BufferedWriter writer=new BufferedWriter(write);
int num = 0;
int flag = 0;
for(String mail:list)
{
mail = head + mail;
URL url=new URL(mail);
System.out.println(mail);
System.out.println("\n");
BufferedReader bufred=new BufferedReader(new InputStreamReader(url.openStream(),"UTF-8"));
String title_regex = "<div id=\"papertitle\">\\n(.*?)</div>";
String abstract_regex = "<div id=\"abstract\" >\\n(.*?)</div>";
Pattern p = Pattern.compile(title_regex);
Pattern q = Pattern.compile(abstract_regex);
String line = null;
String content = null;
while((line=bufred.readLine())!=null)
{
content = content + line + "\n";
}
Matcher w = p.matcher(content);
Matcher n = q.matcher(content);
if(w.find()&&n.find())
{
if(flag == 1)
{
writer.write("\n\n\n");
}
flag = 1;
writer.write(String.valueOf(num));
num++;
writer.write("\nTitle: ");
writer.write(w.group(1));
writer.write("\nAbstract: ");
writer.write(n.group(1));
}
}
writer.close();
-
实现了题目的基本需求(爬取CVPR2018论文列表)
![]()
-
实现了附加功能需求:
![]()



1、爬取了各个论文的属性以及作者和作者工作单位用于附加功能界面的实现(按论文标题进行了同一论文的合并)。利用了网上github归纳整合的论文属性进行爬取 https://github.com/amusi/daily-paper-computer-vision/blob/master/2018/cvpr2018-paper-list.csv
2、爬取了CVPR2018论文PDF链接和论文网址
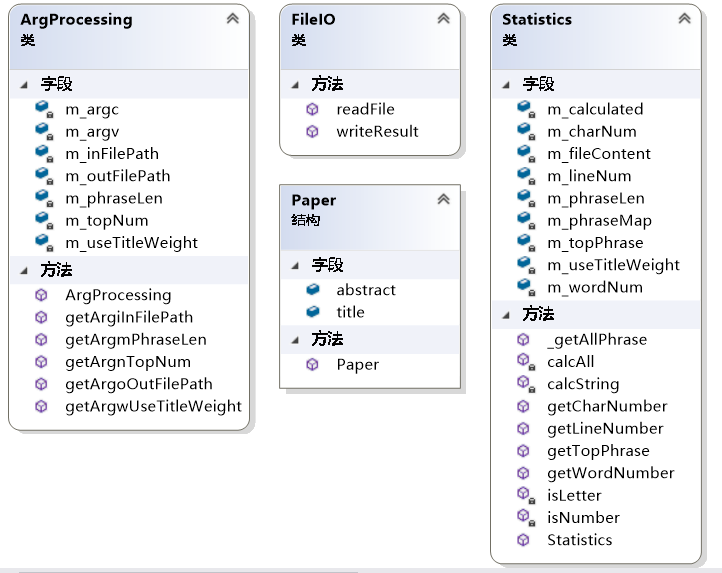
代码组织与内部实现设计(类图):
说明:
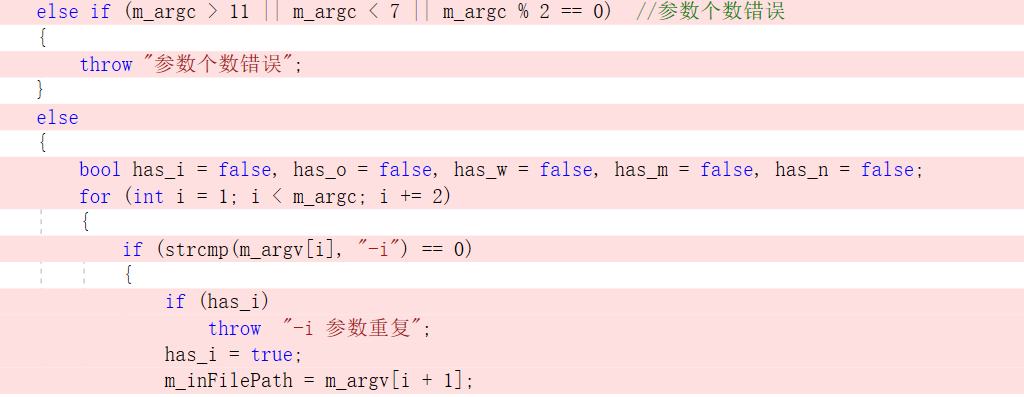
- ArgProcessing类封装了命令行参数处理的方法。传入argc、argv,通过get字段取出对应参数数值。
1、ArgProcessing() 构造函数:对参数进行处理
2、getArgiInFilePath() 获取-i后的参数:输入文件路径
3、getArgoOutFilePath() 获取-o后的参数:输出文件路径
4、getArgwUseTitleWeight() 获取-w参数:是否使用标题10倍权重
5、getArgmPhraseLen() 获取-m参数:短语长度
6、getArgnTopNum() 获取-n参数:结果所需单词数
- FileIO类封装了用于特定格式文件读写的方法
1、readFile() 按照指定格式读取文件
2、writeResult() 按照指定格式写文件
- Paper结构对应于论文的结构
1、title 论文标题
2、abstract 论文摘要
3、将论文抽象成一个结构,保证了可拓展性,还可以加入如论文作者、论文网站、论文PDF连接等属性,还可以对论文属性进行枚举。
- Statistics结构对应于论文的结构
1、getCharNumber() 获取字符个数
2、getWordNumber() 获取单词个数
3、getLineNumber() 获取获取行数
4、getTopPhrase() 获取最高频的n个词组
5、_getAllPhrase() 获取所有词组,用于调试
6、isLetter() 判断给定字符是否为字母
7、isNumber() 判断给定字符是否为数字
8、calcString() 对给定字符串执行统计功能
9、calcAll() 对所有文本内容fileContent执行统计功能
关键算法及流程图:
- 统计单词算法
1、定义单词缓存wordBuf、分隔符缓存separatorBuf、词组缓存队列phraseBuf,初始化为空。
2、对给定字符串进行遍历,遍历过程中记录单词缓存、分隔符缓存。
3、遇到分隔符:若单词缓存中不是单词,清空分隔符缓存和词组缓存队列;若单词缓存中是单词,则将分隔符压入词组缓存队列,将单词缓存压入词组缓存队列。若词组缓存队列长度达到指定的词组长度的2倍(因为压入的是分隔符和单词),弹出词组缓存队列首个分隔符,遍历词组缓存队列取出词组,弹出词组缓存队列首个单词。
4、重复步骤3直至处理完整个字符串。

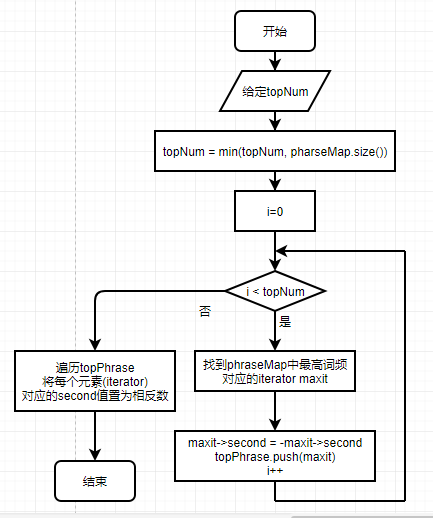
- 获取最高频的n个词组
1、对按照以词组————次数存的map进行n次遍历
2、每次遍历,将次数最多的词组的迭代器取出。通过迭代器将词组次数置为相反数(设为负数,下次寻找最大值排除在外)。将取出的迭代器加入结果数组。
3、取完n个迭代器后,对结果数组进行遍历,将词组次数置为相反数(恢复正数)。完成。
关键代码解释
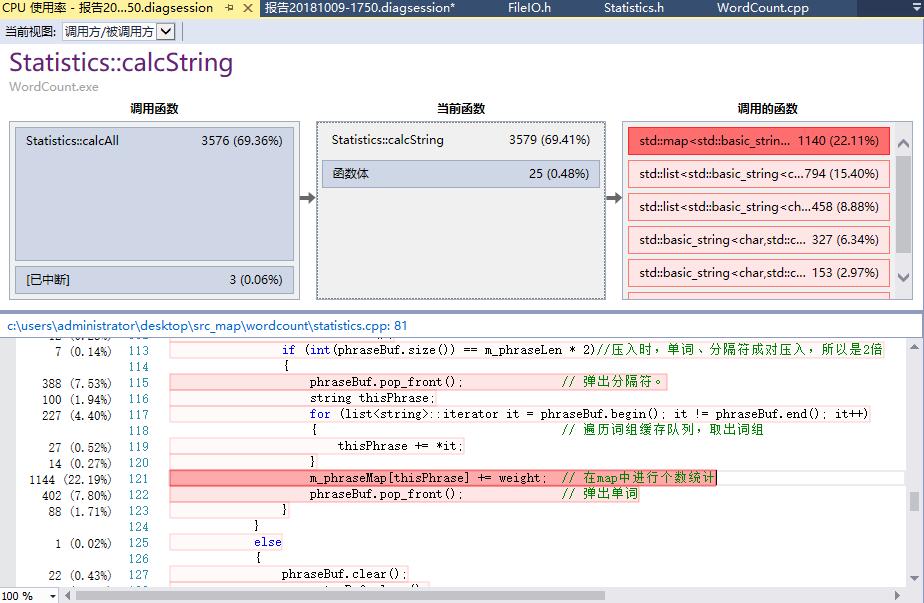
- 短语统计
1、以“分隔符-单词-分隔符-单词-分隔符-单词”的形式压入短语缓存队列。
2、取短语时,先冒出短语缓存队列的首个分隔符,然后遍历队列取出短语,最后冒出短语缓存队列的首个单词。
if (wordBuf.size() >= 4 && isLetter(wordBuf[0]) && isLetter(wordBuf[1]) && isLetter(wordBuf[2]) && isLetter(wordBuf[3]))
{
m_wordNum++;
phraseBuf.push_back(separatorBuf); // 将分隔符压入词组缓存
phraseBuf.push_back(wordBuf); // 将单词压入词组缓存
separatorBuf.clear();
wordBuf.clear();
if (int(phraseBuf.size()) == m_phraseLen * 2)//压入时,单词、分隔符成对压入,所以是2倍
{
phraseBuf.pop_front(); // 弹出分隔符。
string thisPhrase;
for (list<string>::iterator it = phraseBuf.begin(); it != phraseBuf.end(); it++)
{ // 遍历词组缓存队列,取出词组
thisPhrase += *it;
}
m_phraseMap[thisPhrase] += weight; // 在map中进行个数统计
phraseBuf.pop_front(); // 弹出单词
}
}
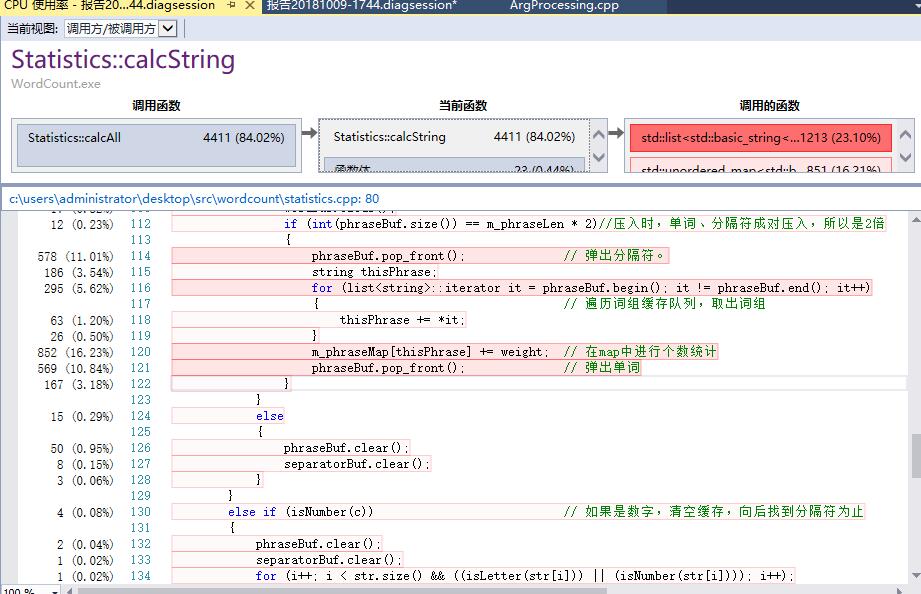
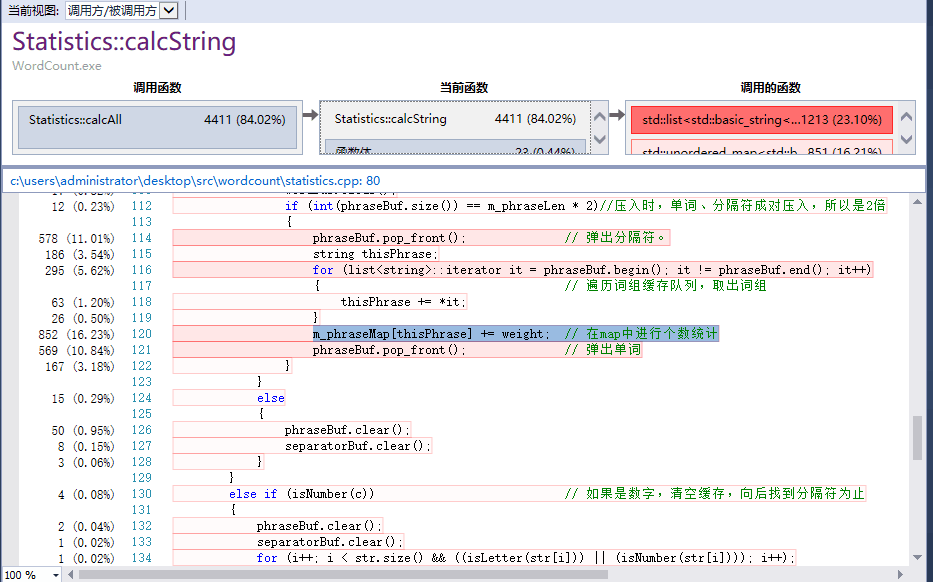
- 取最高频的n个短语
1、为确保正确,n应取需求个数n和不同短语个数phraseMap.size()的最小值。
2、对phraseMap遍历n遍,每次遍历取出最高频次对应的iterator,加入结果,并通过iterator将词频置为相反数(确保下一次遍历时不考虑它)。
3、取完n个iterator后,应对取出的iterator再次遍历,将词频置为相反数,恢复词频为正数。
topNum = min(topNum, int(m_phraseMap.size()));
for (int i = 0; i < topNum; i++)
{
unordered_map<string, int>::iterator maxit = m_phraseMap.begin();
for (unordered_map<string, int>::iterator it = m_phraseMap.begin(); it != m_phraseMap.end(); it++)
{
if (it->second > maxit->second || it->second == maxit->second && it->first < maxit->first)
{
maxit = it;
}
}
m_topPhrase.push_back(maxit);
maxit->second = -maxit->second;
}
for (unsigned int i = 0; i < m_topPhrase.size(); i++)
{
m_topPhrase[i]->second = -m_topPhrase[i]->second;
}
Step3 · 附加题设计与展示
设计创意独到之处
- 实现了交互界面将创新想法需求与界面相结合(基本与上回作业的设计原型一致)
- 用java从网站综合爬取论文的除题目、摘要外其他信息
- 对数据的图形可视化做了一些努力,将对通过java爬取的数据进行处理,依据处理的结果绘制统计图。
- 在界面的基础上实现了(一些右键功能的加入(方便操作))
- 每日推荐:进行随机推荐(支持刷新以更换推荐),对于推荐的论文可以进行收藏,以及打开其PDF链接
- 论文搜索:按照作者和标题进行论文的检索
- 流行趋势:对所有论文的热词进行统计并画出热词直方图(对爬取结果)
- 人物风采:展示了论文重要Speakers的简介
- 我的收藏:收藏功能的实现以及对已收藏论文的批量管理。
- 软件设置:实现了各种主题皮肤的切换(更加满足不同用户的个性化需求)
实现思路:
- 公用的是左边的图片和若干个按钮,采用垂直线性布局,右边一个QWidget,用来放子界面。整个页面采用水平线性布。对应的子界面构造出来后,都作为右边空Widget的子对象放在右边的Widget中。
- 论文列表采用QListWidget,添加论文项目用addItem添加一行。
。右键菜单的实现用到了QMenu,使用addAction对menu加入指定的action。 - 统计图的实现,是在QChartView中用QChart来绘制的。(数据是使用爬虫爬下来的。ps:真实数据)
- 主题的切换,采用css和qss样式表实现。
- 事件的触发,用Qt的信号和槽机制。
- 搜索功能采用关键词匹配
实现工具:QT5 + MSVC 2017 + Python
实现成果展示:
-
说明:成果exe和代码见附件
-
热词图谱效果图(部分):
-
前10热词(包括长度为2词组)
![]()
-
前50热词(包括长度为2词组)
![]()
-
使用python生成热词图谱(源码如下)


from wordcloud import WordCloud
import matplotlib.pyplot as plt
f = open(u'Spider_result.txt','r',encoding='utf-8').read()
#修改基本功能需求文件内容格式
content = ""
i = 0
while(i<len(f)):
if f[i]>='0'and f[i]<='9':
while(f[i]!='\n'):
i+=1
i+=1
while(f[i]!=' '):
i+=1
i+=1
title=""
while(f[i]!='\n'):
title+=f[i]
i+=1
i+=1
while(f[i]!=' '):
i+=1
i+=1
abstract=""
while(i < len(f)):
if f[i]=='\n':
break
else:
abstract += f[i]
i+=1
i+=3
content+=title + '\n' + abstract + '\n'
wordcloud = WordCloud(
background_color="white", #设置背景为白色,默认为黑色
width=1500, #设置图片的宽度
height=960, #设置图片的高度
max_words=50, #设置显示的热词数
margin=10 #设置图片的边缘
).generate(content)
# 绘制图片
plt.imshow(wordcloud)
# 消除坐标轴
plt.axis("off")
# 展示图片
plt.show()
# 保存图片
wordcloud.to_file('hot words2.png')
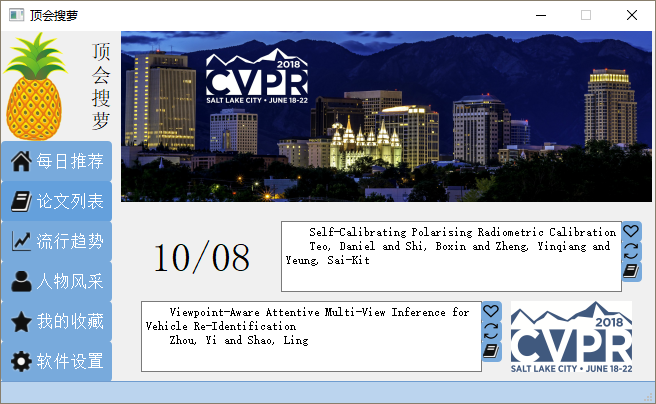
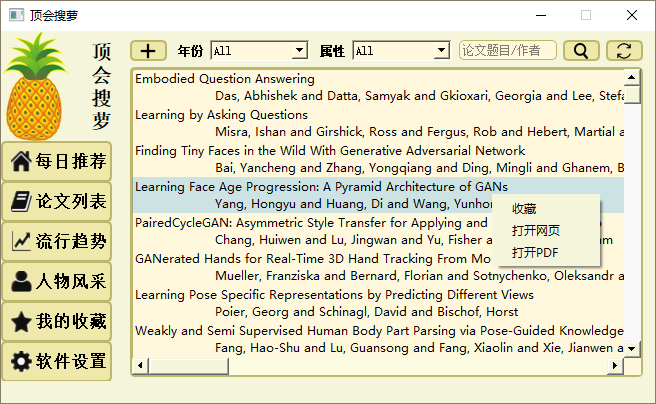
1_每日推荐界面

2_论文搜索界面
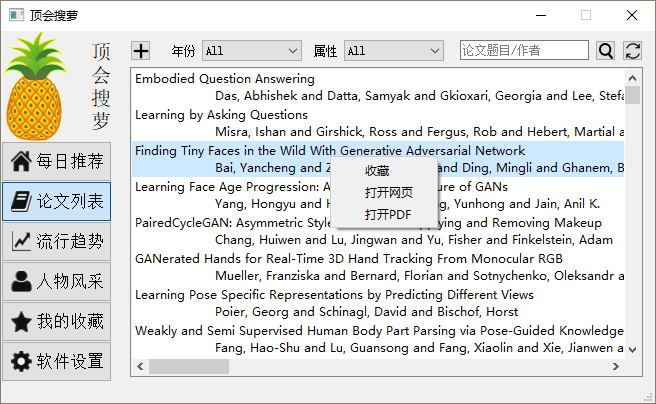
2_论文搜索界面_搜索功能
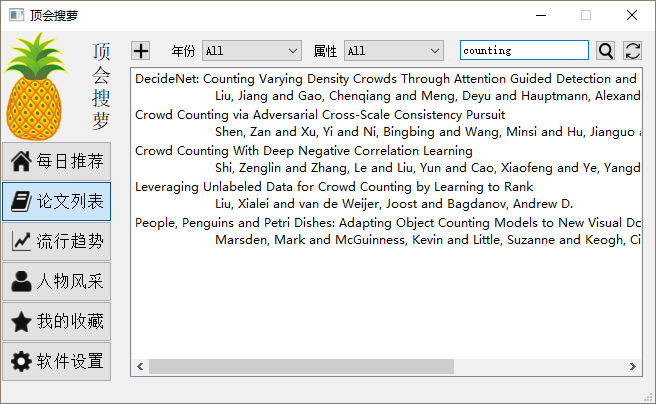
3_流行趋势_十大热词排名统计图
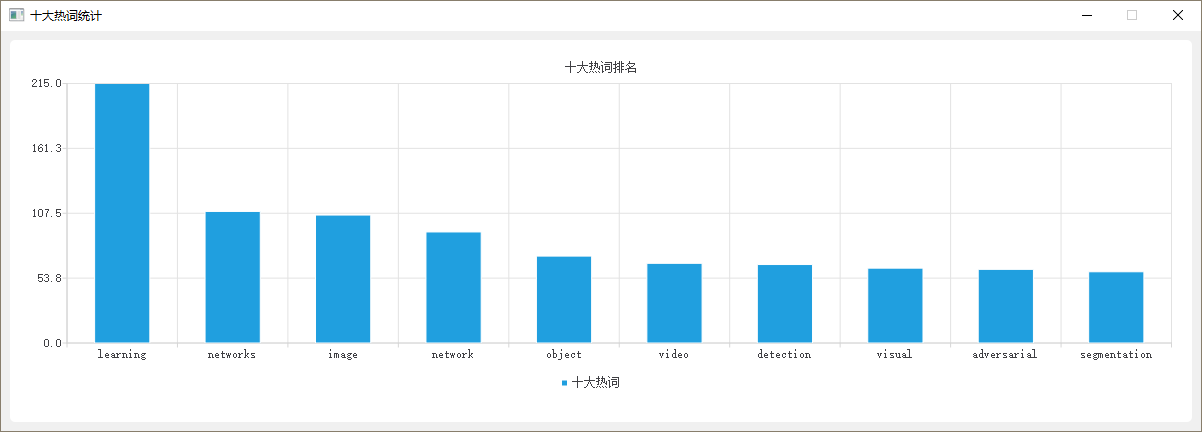
4_人物界面

5_我的收藏界面

6_设置界面

6_设置界面_更改头像
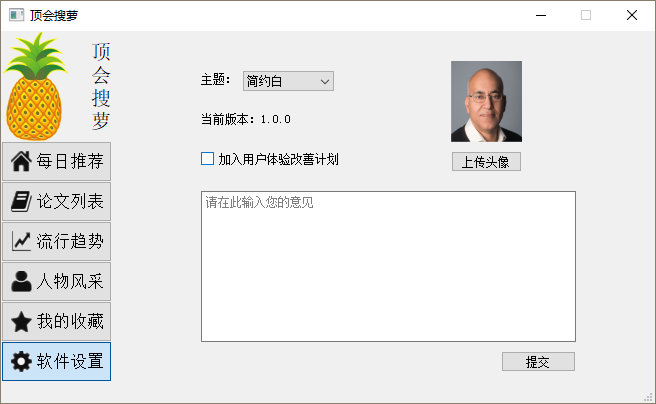
6_设置界面_更换主题
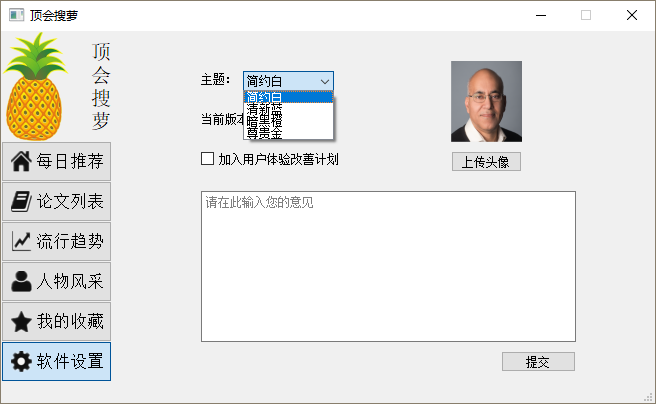
7_暗黑橙主题_论文搜索界面

7_暗黑橙主题_每日推荐界面

7_清新蓝主题_论文搜索界面

7_清新蓝主题_每日推荐界面
7_尊贵金主题_论文搜索界面
Step4 · 测试与优化
性能分析与改进:
-
说明:Debug x86编译,phraseLen = 1 topNum = 10
-
起初使用map实现

- 瓶颈:
![]()
-改进:用 unordered map 代替 map

- 瓶颈:
警告消除:
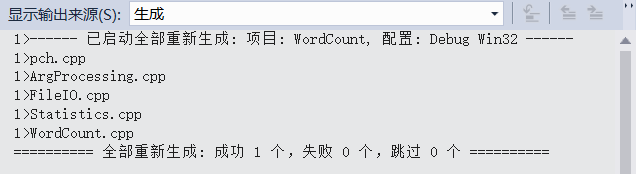
单元测试:
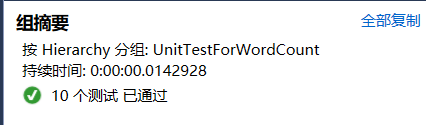
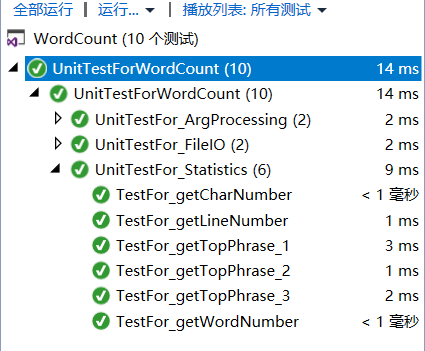
- 运行说明:若要运行单元测试请以x86形式运行
- 样例说明:(前四个对应四种异常处理,后六个为对接口函数的测试)
传入(或输出)文件名 | 测试文件| 测试函数| 期待输出
---|---|---|---|---|
aaa.txt(不存在的文件名) | FileIO.h|FileIO::readFile()|输入错误的文件名(异常处理)
empty.txt(传入)\//\//(输出) | FileIO.h|File::writeResult()|输出文件名错误(异常处理)
无|ArgProcessing.h|ArgProcessing:ArgProcessing()|主函数参数过多(异常处理)
无|ArgProcessing.h|ArgProcessing::ArgProcessing()|错误命令行参数(异常处理)
lines(nw)_test.txt|Statistics.h|Statistics::getLineNumber()|正确统计文本的行数(不带权重)
words(nw)_test.txt|Statistics.h|Statistics::getWordNumber()|正确统计文本中的单词数(不带权重)
char(nw)_test.txt|Statistics.h|Statistics::getCharNumber()|正确统计字符数(不带权重)
TopPhrase_3(nw)_test.txt|Statistics.h|Statistics::getTopPhrase()|正确输出频率前十的词组(不带权重)
Top9Phrase_1(w)_test.txt|Statistics.h|Statistics::getTopPhrase()|正确输出频率前十单词(带权重)
Top2Phrase_3(nw)_test.txt|Statistics::getTopPhrase()|正确输出频率前n的词组(不带权重)
部分代码展示:
- 文件读写错误(异常处理)
TEST_CLASS(UnitTestFor_FileIO)
{
public:
TEST_METHOD(TestFor_readFile)
{
auto fun = [this]
{
const char* inputfile = "aaa.txt";
const char* outputfile = "result_test.txt";
vector<Paper> fileContent;
bool showInConsole = false;
FileIO::readFile(fileContent, inputfile, showInConsole);
};
Assert::ExpectException<const char*>(fun);
}
TEST_METHOD(TestFor_writeFile)
{
auto fun = [this]
{
const char* inputfile = "empty.txt";
const char* outputfile = "\\//\\//";
vector<Paper> fileContent;
int phraseLen = 1;
bool useTitleWeight = false;
bool showInConsole = false;
int topNum = 10;
Statistics st(fileContent, useTitleWeight, phraseLen);
vector<unordered_map<string, int>::iterator> &topPhrase = st.getTopPhrase(topNum);
FileIO::writeResult(1, 1, 1, topPhrase, outputfile, showInConsole);
};
Assert::ExpectException<const char*>(fun);
}
};
- 参数判断(异常处理)
TEST_CLASS(UnitTestFor_ArgProcessing)
{
public:
TEST_METHOD(TestFor_ArgProcessingOvermuch)
{
auto fun = [this]
{
char *argv[4] = { "WordCount.exe","-i","input.txt","-n" };
int argc = 3;
ArgProcessing ap(argc, argv);
};
Assert::ExpectException<const char*>(fun);
}
TEST_METHOD(TestFor_ArgProcessingWrong)
{
auto fun = [this]
{
char *argv[13] = { "WordCount.exe","-i","input.txt","-m","3","-n","3","-w","1","-o","output.txt","yeah" };
int argc = 12;
ArgProcessing ap(argc, argv);
};
Assert::ExpectException<const char*>(fun);
}
};
- 正确输出频率前十的词组(不带权重)
TEST_METHOD(TestFor_getTopPhrase_1)
{
const char* inputfile = "TopPhrase_3(nw)_test.txt";
vector<Paper> fileContent;
int topnum = 10;
int phraseLen = 3;
bool useTitleWeight = false;
bool showInConsole = false;
FileIO::readFile(fileContent, inputfile, showInConsole);
Statistics st(fileContent, useTitleWeight, phraseLen);
string answer[10] ={
"abcd_abcd_abcd","abcd_abcd.then",
"else_todo_abcd","then_else_todo","todo_abcd_abcd",
"abcd.abcd.abcd","abcd.then,else","abcd.then_else",
"abcd_abcd.abcd","then,else;todo"};
int frequence[10] = {9,6,6,6,6,3,3,3,3,3};
vector<unordered_map<string, int>::iterator> &tem = st.getTopPhrase(topnum);
//FILE *fp = NULL;
//fopen_s(&fp, "asd.txt", "w");
for (int i = 0; i < 10; i++)
{
/*fprintf(fp, "%d\n", tem[i]->second);*/
Assert::IsTrue(tem[i]->first == answer[i] && tem[i]->second == frequence[i]);
}
}
运行结果:
代码覆盖率:
- 说明:使用了一个样例来测试代码覆盖率(代码覆盖率不高的原因是一些测试用的函数和异常处理的模块调用的少)(注释掉测试用函数,所有单元测试的代码覆盖率应该是接近100%的)

Step5 · 结对过程
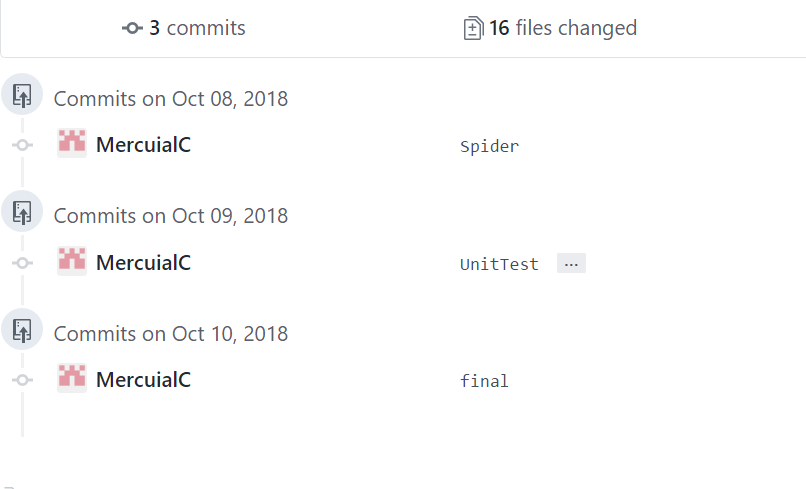
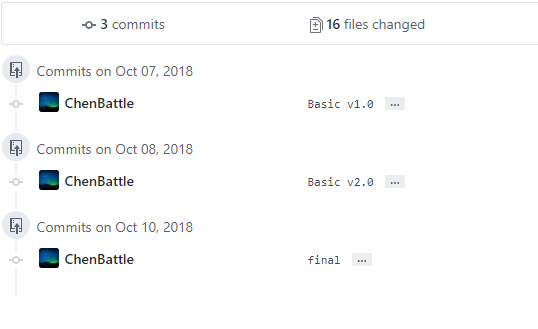
代码签入记录:
- 蔡宇航:
![]()
- 陈柏涛:
![]()
遇到的代码模块异常或结对困难及解决方法:
- 代码模块异常:
1、在实现爬虫的过程中遇到了乱码的情况,通过转换编码为UTF-8解决了这一点
2、在实现爬虫的过程出现了爬取过程中get请求某个论文url时超时导致爬虫卡在那一段,后来利用了设置超时时间来捕获异常超时处理,异常处理为重新加载(return)
3、词组词频统计时对于单词之间分隔符忽略了,导致最后输出的词组仅已空格分隔,后来使用了一个词组缓冲队列,每次压入单词前先压入分隔符缓存,取出单词前先冒掉首个分隔符缓存,再遍历队列取出词组,冒掉首个单词。
- 结对困难
1、老是觉得国庆的时间很长,事情留到国庆做,但是假期的效率太低。
2、由于词频统计原先是个人作业,双方原先代码风格规范不一致,加上功能模块较少,协作起来困难,所以在思路共同讨论的情况下分工合作。
评价队友:
- 评价陈柏涛同学(蔡宇航)
值得学习的地方:
1、代码能力以及代码的规范程度
2、时间观念强,很早的完成任务
3、学习能力强,新的东西学习快
需要改进的地方:
睡眠时间要加长
- 评价蔡宇航同学(陈柏涛)
值得学习的地方:
1、强烈的求知欲,刨根问底。
2、学习能力强,学东西快。
3、有良好的编码规范。
4、思路灵活,富有创造性。
需要改进的地方:
不要熬夜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号