福大软工1816 · 第二次作业 - 个人项目
1. Github项目地址。
2. 给出PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 660 | 1080 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 30 | 20 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 60 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 650 |
| Reporting | 报告 | 120 | 110 |
| · Test Repor | · 测试报告 | 15 | 60 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 40 |
| | 合计 | 790 | 1200
3. 解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程。
解题思路
- 本任务的要求是统计给定文件中的字节数、单词数、行数、最高频的10个单词
- 从main函数的argv中读出传入参数作为文件名。
- 在文件读入时,为了能读出换行符'\n',我选择采用按字节读入的方法。读入的多个字符按行拼装成一个string,所有行(string)组成一个vector返回,记为vector
file_lines。 - 对file_lines进行遍历,在遍历过程中可以简单地统计出字节数、单词数、行数。统计单词数可以采用正则表达式,我没用正则表达式,而是自己手写判断规则,以获得更高的效率。
- 遍历file_lines时,以单词作为key,出现次数为value建立map<string,int>。要统计N个单词中最高频的n个单词,有两种做法:
(1)种是使用诸如快排、堆排的排序算法进行排序,取出前n个。(其中,堆排比快排在极端情况下表现更好)。由于涉及到对字符串的排序,移动字符串较为耗时,可以使用引用或指针代替。时间复杂度O(N*log(N))
(2)对序列遍历n次,可以取出排名前n个的单词。时间复杂度O(N*n)
本题目n=10,在N<100的情况下(1)更好,N>100情况下(2)更好。在N<100时,虽然(2)比(1)更耗时,但由于问题规模较小,时间也不会多多少,是可接受的。权衡二者,我采用第(2)中方法统计最高频的10个单词。
- 最后将结果输出即可。
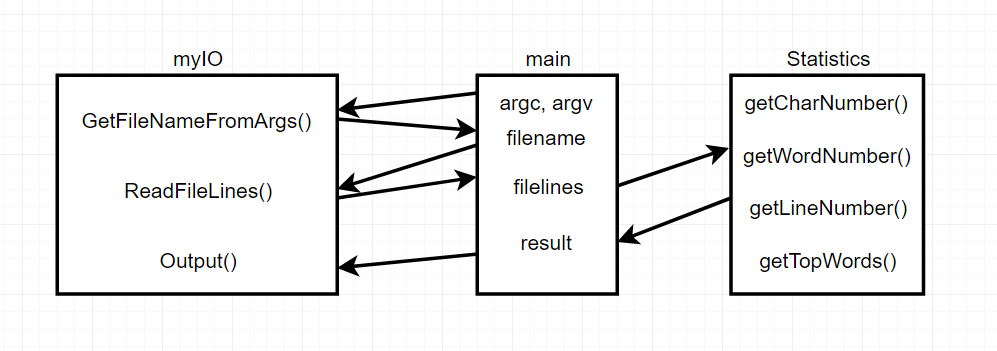
4. 设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
- 由于作业要求,我要按照以下格式组织代码
031602502
|- src
|- WordCount.sln
|- WordCount
|- pch.h
|- myIO.h
|- Statistics.h
|- pch.cpp
|- myIO.cpp
|- Statistics.cpp
|- WordCount.cpp
|- WordCount.vcxproj
|- WordCountUnitTest
|- stdafx.h
|- targetver.h
|- stdafx.cpp
|- unittest1.cpp
- main在WordCount.cpp中
- 用于统计的类Statistics,封装了getCharNumber、getWordNumber、getLineNumber、getTopWords方法;
- myIO命名空间,包含了用于IO的GetFileNameFromArgs、ReadFileLines、Output方法。
过程
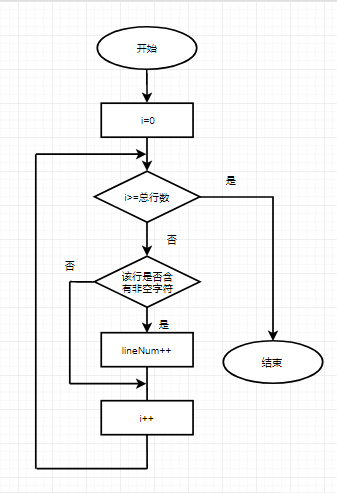
计算文本有效行数
计算最高频的10个词

单元测试
- 在运行单元测试前,确保先以Debug x86方式运行过程序,确保WordCount/Debug目录下有对应的.obj文件
- 新建本机测试项目,引用WordCount项目,手动设置测试项目的附加依赖项(到.obj文件的相对路径),将被测试项目产生的所有 obj 文件路径写到附加依赖项中。
- 对于Statistics类的测试
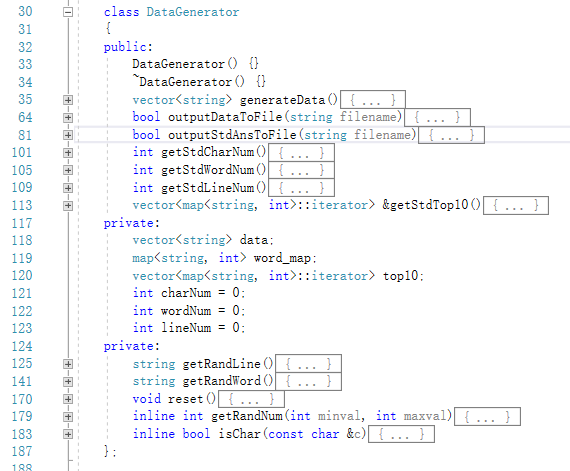
1.采用unittest1.cpp中写的的DataGenerator类随机生成文本内容和标准结果。
构造测试数据,是以字符为最小单位。用随机的字符组成随机的单词,加上随机的分隔符。若干个随机单词拼成一行。若干行拼成整个文本内容。为保证单词重复出现,设计新单词有20%的概率从以前出现的单词中取。此外,增大了空格在分割符中的使用比例。构造测试数据的过程中,可以得到字符数、单词数、行数、最高频词。将标准结果与通过Statistics类计算出来的数据进行比较,以此来进行单元测试。可通过改变以下宏变量来修改随机测试的参数。#define UNIT_TEST_CASE 20 #define MAX_LINE_NUM 50 #define MIN_LINE_NUM 0 #define MAX_LINE_LEN 20 #define MIN_LINE_LEN 0 #define MAX_WORD_LEN 8 #define MIN_WORD_LEN 0
DataGenerator类定义
测试代码
srand(unsigned int(time(0)));
DataGenerator dg;
for(int i=0;i < UNIT_TEST_CASE;i++)
{
vector<string> lines = dg.generateData();
Statistics st(lines);
vector<map<string, int>::iterator> st_top10 = st.getTopWords(10);
vector<map<string, int>::iterator> dg_top10 = dg.getStdTop10();
dg.outputDataToFile("input.txt"); //输出随机测试用例到文件
dg.outputStdAnsToFile("std_ans.txt");//输出测试标准答案到文件
Assert::AreEqual(dg.getStdCharNum(), st.getCharNumber());
Assert::AreEqual(dg.getStdWordNum(), st.getWordNumber());
Assert::AreEqual(dg.getStdLineNum(), st.getLineNumber());
for (unsigned int i=0;i< dg_top10.size();i++)
{
Assert::AreEqual(dg_top10[i]->first, st_top10[i]->first);
Assert::AreEqual(dg_top10[i]->second, st_top10[i]->second);
}
}
其中一个测试的例子
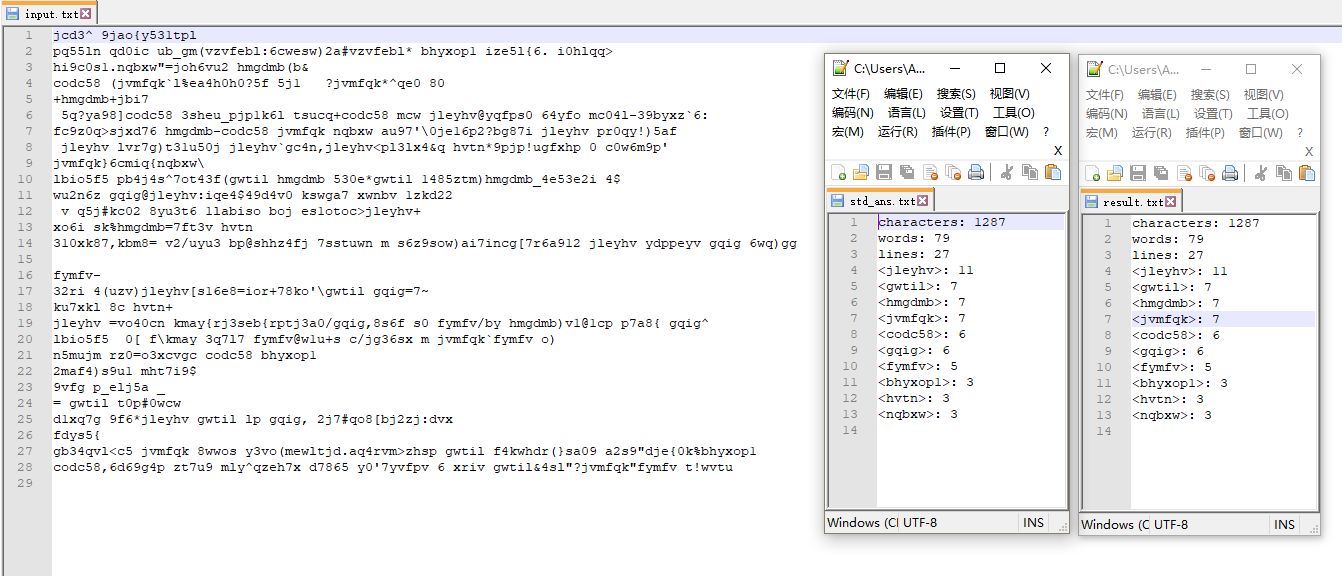
2.对于一些特定的数据,可以采取手动录入,人工比较的方式。
vector<string> lines; //空文件 lines.clear(); lines.push_back(string("")); Assert::AreEqual(0, Statistics(lines).getCharNumber()); Assert::AreEqual(0, Statistics(lines).getWordNumber()); Assert::AreEqual(0, Statistics(lines).getLineNumber()); //------------------------------------------------------------ //全是空行 lines.clear(); lines.push_back(string("\n")); lines.push_back(string("\n")); lines.push_back(string("\n")); Assert::AreEqual(3, Statistics(lines).getCharNumber()); Assert::AreEqual(0, Statistics(lines).getWordNumber()); Assert::AreEqual(0, Statistics(lines).getLineNumber()); //------------------------------------------------------------ //最后一行没有换行 lines.clear(); lines.push_back(string("asdf123\n")); lines.push_back(string("a v4w")); Assert::AreEqual(13, Statistics(lines).getCharNumber()); Assert::AreEqual(1, Statistics(lines).getWordNumber()); Assert::AreEqual(2, Statistics(lines).getLineNumber()); //------------------------------------------------------------ //最后一行有换行 lines.clear(); lines.push_back(string("asdf123\n")); lines.push_back(string("a v4w\n")); Assert::AreEqual(14, Statistics(lines).getCharNumber()); Assert::AreEqual(1, Statistics(lines).getWordNumber()); Assert::AreEqual(2, Statistics(lines).getLineNumber());
- 对于myIO命名空间内函数的测试
主要是测试异常处理。手工构造数据,进行测试。
测试结果
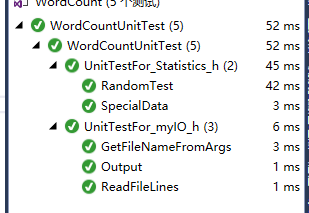
覆盖率
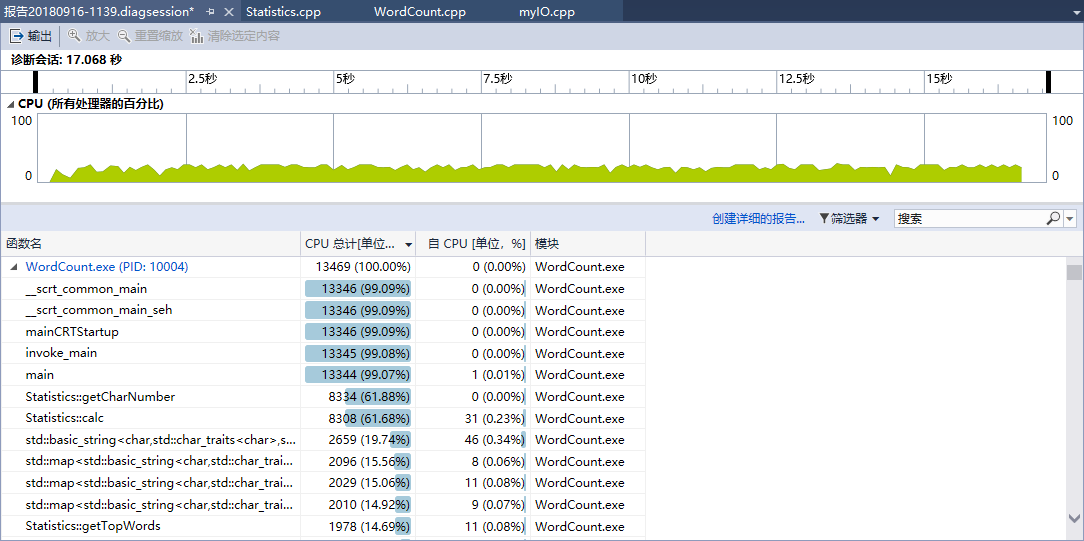
5. 记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
数据量较小时,所花费的时间大部分在IO上。若要提高性能,可以用C语言的IO方法(如scanf、printf、fopen、fclose)代替C++的IO的方法(如cin、cout、ifstream、ofstream)
数据量较大时,IO占用的时间比例就较小。为了提高性能:
调用Statistics类的方法进行统计功能时,采用引用或指针的方式传入文本内容,避免对较为庞大文本内容进行再一次拷贝,避免时间和空间上的浪费。
由于计算字节数、单词数、行数均可在一次遍历统计中完成,所以我一个变量来标记是否进行过统计,若执行过,则直接返回计算结果,避免重复计算。
在统计最高频的10个单词时,我采用遍历10次来取出最高频的10个词的方法代替排序的方法。虽然在数据量N较小时,使用排序的方法时间会更少(O(Nlog(N))),但是由于本题是统计前n=10的词,在数据量N较大时,采用遍历的方法更好(O(Nn))。在数据量N较小时,遍历的方法花略微多一点时间,但这是可接受的。
采用map的方式组织单词和对应的出现次数。map的实现是采用红黑树(一种非严格意义上的平衡二叉树),数据的插入、删除、查找均只要O(logn)。使用map的方式组织数据,数据插入完成后,单词就已按照字典序排好。
统计最高频的10个词时,统计结果以vector<map<string,int>::iterator >&返回,避免对map中的key-value再次拷贝。要注意的是要还原统计过程中通过iterator对value值进行的修改。
对于以下文本内容,重复执行main1000次
运行结果
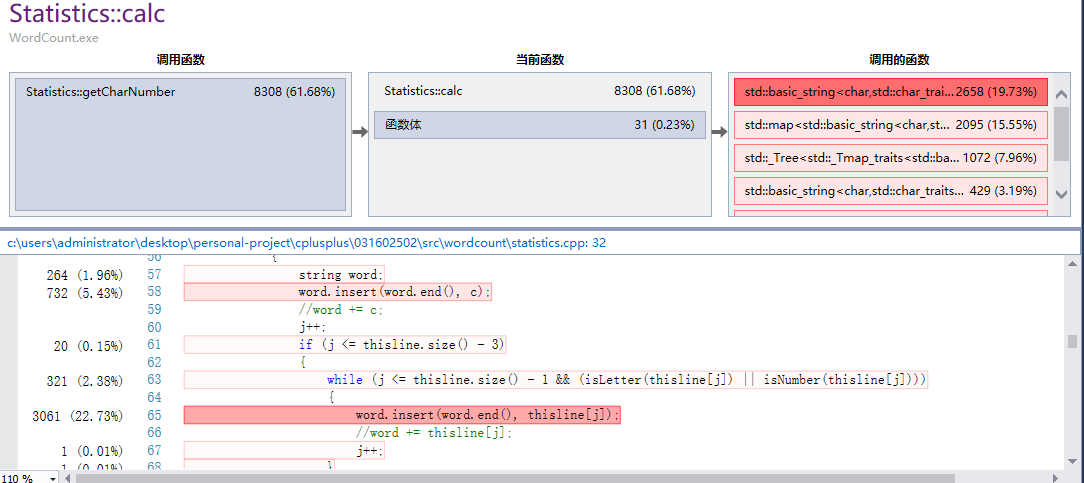

改进

重新运行分析,测试1000遍结果
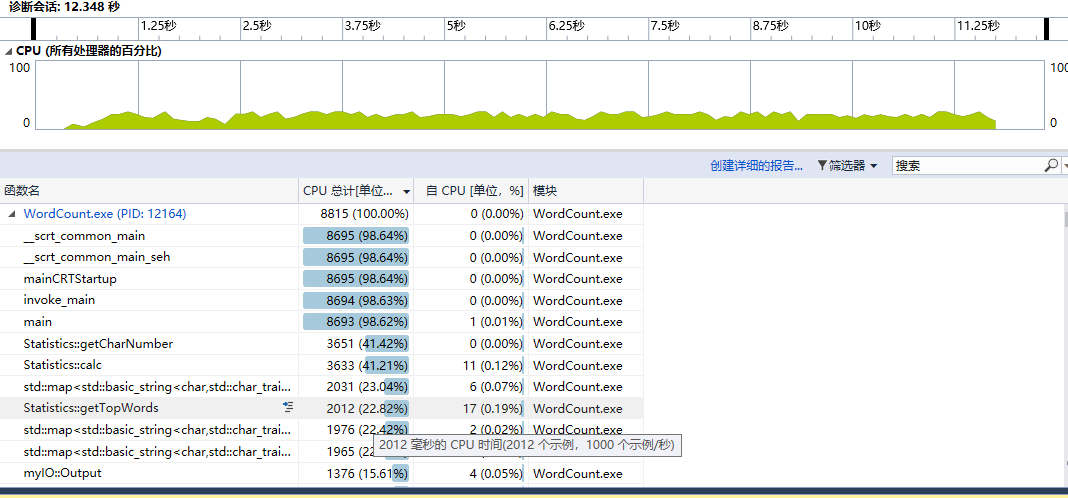
使用C风格IO
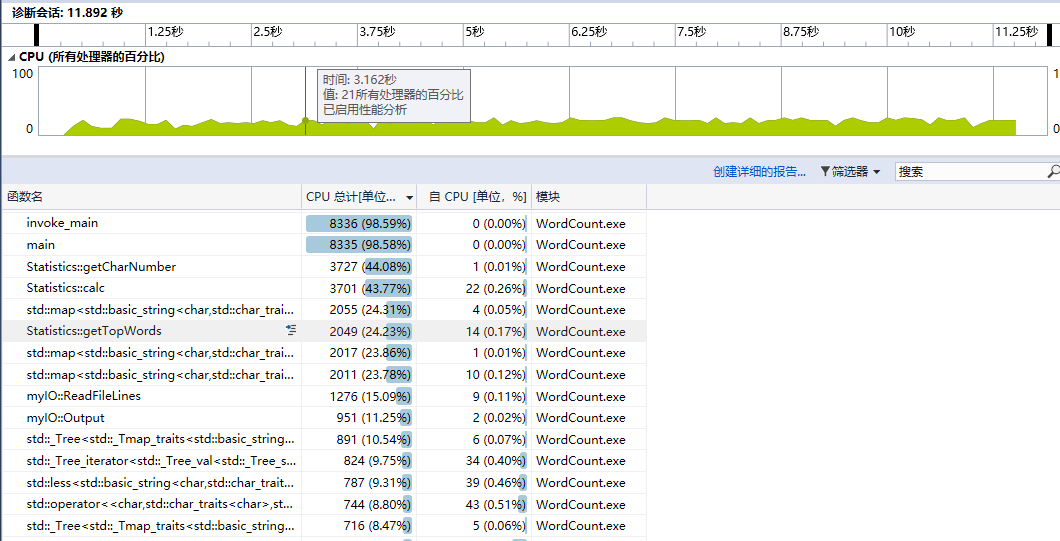
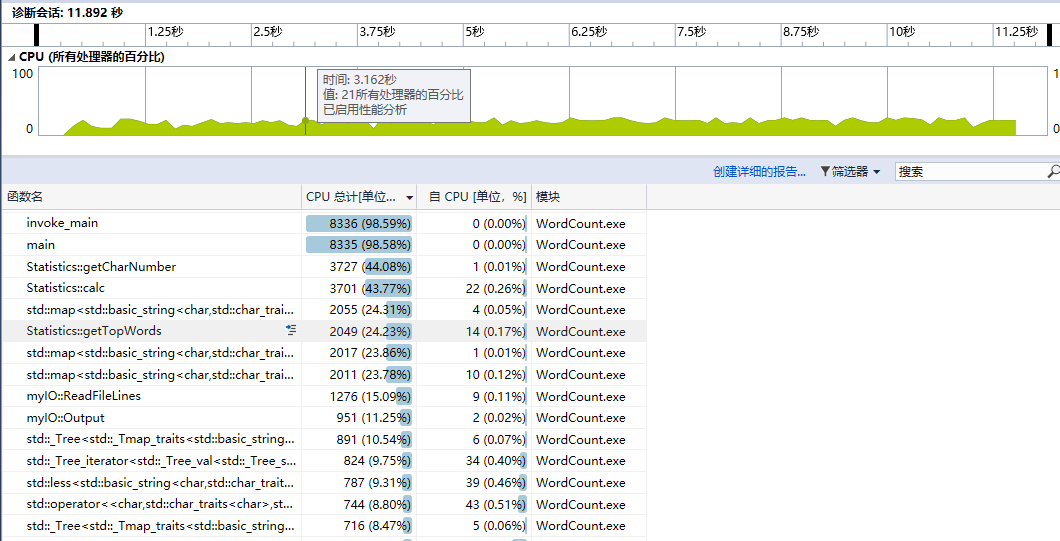
分析:
文本内容较少时,消耗最大的是用于IO的函数,这时采用C风格的IO函数(fopen、fprintf、fclose等)代替C++风格的IO函数(ifstream和ofstream)可以显著提高性能。
当文本内容较多时,IO占用的时间比例减少,消耗最大的是用于计算的函数。
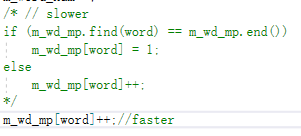
我改进map的插入方式(value类型为int,初始值为0,使用直接map[key]++代替先查找再自增),避免2次查找。
改变string插入方式,由string.insert(string.end(), char)改为string += char
通过以上调整,重新测试。性能提升30%
6. 代码说明。展示出项目关键代码,并解释思路与注释说明。
关键代码说明:
1.统计功能,对字节数、单词数、行数进行统计。
去除只含有空白字符的空行采用的方法是:判断一行中每个字符ascll码值是否大于32,若大于,则为非空字符,否则为空字符。
统计单词的方法是:按照字符遍历,将字符拼装成单词,以分隔符或者EOF为界限。
计算完成后,用calculated标记计算状态,避免对相同的数据重复计算。
void Statistics::calc()//统计功能,可不必手动调用
{
for (unsigned int i = 0; i < m_file_lines.size(); i++)
{
const string &thisline = m_file_lines[i];
m_char_num += thisline.size();
bool is_a_line = false;
for (unsigned int k = 0; k < thisline.size(); k++)//判断是否为空白行
{
if (thisline[k] > 32)//大于32为非空白字符
{
is_a_line = true;
break;
}
}
if (!is_a_line)
continue;
m_line_num++;
unsigned int j = 0;
while (j <= thisline.size() - 1)//统计单词个数
{
char c = thisline[j];
if (isLetter(c))
{
string word;
word.insert(word.end(), c);
j++;
if (j <= thisline.size() - 3)
{
while (j <= thisline.size() - 1 && (isLetter(thisline[j]) || isNumber(thisline[j])))
{
word.insert(word.end(), thisline[j]);
j++;
}
}
if (word.size() >= 4 && isLetter(word[0]) && isLetter(word[1]) && isLetter(word[2]) && isLetter(word[3]))
{
m_word_num++;
if (m_wd_mp.find(word) == m_wd_mp.end())
m_wd_mp[word] = 1;
else
m_wd_mp[word]++;
}
}
else if (isNumber(c))
{
for (j++; j <= thisline.size() - 1 && (isLetter(thisline[j]) || isNumber(thisline[j])); j++);
}
else
{
j++;
}
}
}
calculated = true;
/*for (auto it = m_wd_mp.begin(); it != m_wd_mp.end(); it++)
{
cout << it->first << " " << it->second << endl;
}*/
}
2.获取出现次数排名前几的单词
在执行本函数之前,要求对先执行统计功能。通过calculated进行判断。
为避免越界,遍历次数n应取需求量(本题为10)与不同单词个数的最小值。
进行n次遍历,每次取出当前出现次数最大的单词对应的迭代器,并通过迭代器将出现次数置为相反数,方便取下一个数。
全部取出后,通过取出的迭代器对上一步修改的数据进行还原。
vector<map<string, int>::iterator> &Statistics::getTopWords(unsigned int top_num)//获取出现次数排名前几的单词
{
if (!calculated)
calc();
top_num = min(m_wd_mp.size(), top_num);
for (unsigned int i = 0; i < top_num; i++)
{
string maxstr;
map<string, int>::iterator maxit = m_wd_mp.begin();
for (map<string, int>::iterator it = m_wd_mp.begin(); it != m_wd_mp.end(); it++)
{
if (it->second > maxit->second)
{
maxit = it;
}
}
m_top_words.push_back(maxit);
maxit->second = -maxit->second;
}
for (unsigned int i = 0; i < m_top_words.size(); i++)
{
m_top_words[i]->second = -m_top_words[i]->second;
}
return m_top_words;
}
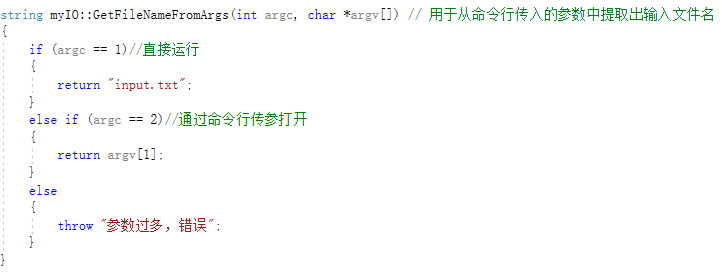
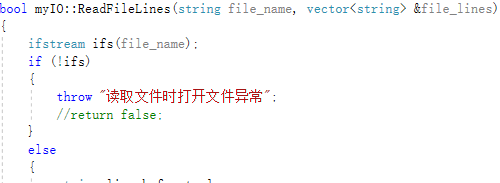
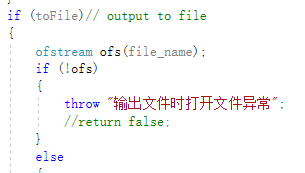
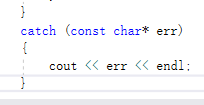
7.异常处理
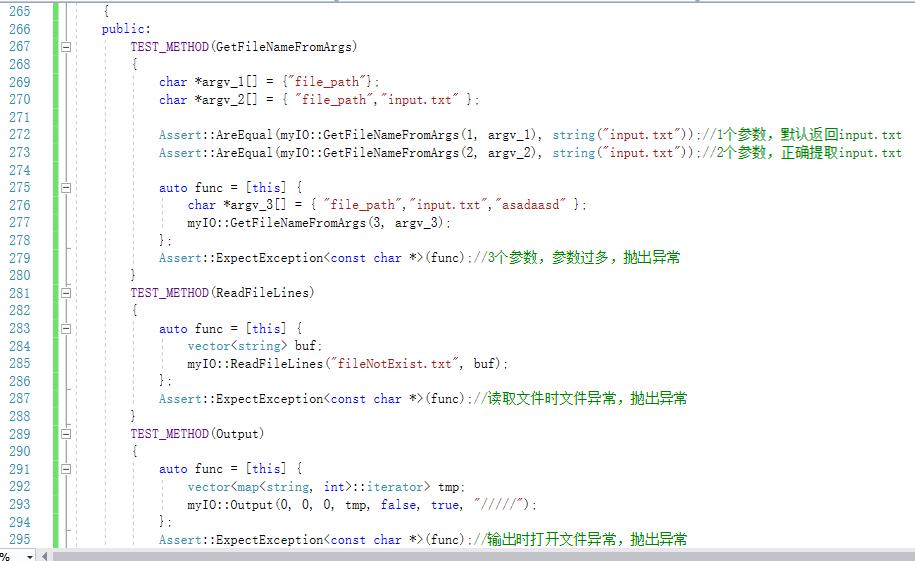
参数错误(参数过多)异常
输入文件打开异常(无法打开输入文件)
输出文件打开异常(无法打开输出文件)
异常处理
对异常处理的单元测试
8. 结合在构建之法中学习到的相关内容与个人项目的实践经历,撰写解决项目的心路历程与收获。
现在可以理解为什么那么多的同学会退这门课了。这门课要花很多的时间,周末的空闲时间几乎全在做这个了。但我不后悔选这门课,付出总是与回报成正比的,第一次的作业就让我学到很多。从开始的通过argc、argv读取命令行参数,到后来的SLT map的使用,iterator的使用;从函数封装到单元测试......此外,还有对变量、函数良好的命名规则,引用、指针的使用。以前虽然对这些略微了解,但是缺乏实践,在一些地方一知半解。通过这次作业,我更加深入的了解了这些知识。
给我印象深刻的是,在和一起同学讨论交流实验的过程中,我们发现:比如fun(a(), b(), c()),调用函数fun(),函数a()、b()、c()执行的先后顺序是c -> b -> a,而不是我们所想象的a -> b -> c。这与函数默认参数的定义顺序有相似性(定义函数默认参数值时,只允许从后往前定义)。会按照c -> b -> a的顺序执行,或许与程序的栈结构有关。
总体感受用一句话形容:虽然苦,但乐在其中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号