大模型--采样技术 TopK TopP 惩罚系数--37
1. 参考
https://mp.weixin.qq.com/s/mBZA6PaMotJw7WeVdA359g
2. 概述
大型语言模型(LLMs)通过“根据上下文预测下一个 token 的概率分布”来生成文本。最简单的采样方法是贪心采样(Greedy Sampling),它在每一步选择概率最高的 token。
这种确定性(deterministic)的方法往往会导致生成重复且缺乏创意的句子。为了解决这一问题,现在有多种采样方法,例如 Top-K、Top-P 或 重复惩罚(Repetition Penalty)。
大多数 LLM 服务框架(例如 vLLM 和 TensorRT-LLM)支持这些采样技术,允许用户在创意和连贯性之间进行调整。不过这些方法会增加计算成本,从而影响服务性能:
贪心采样
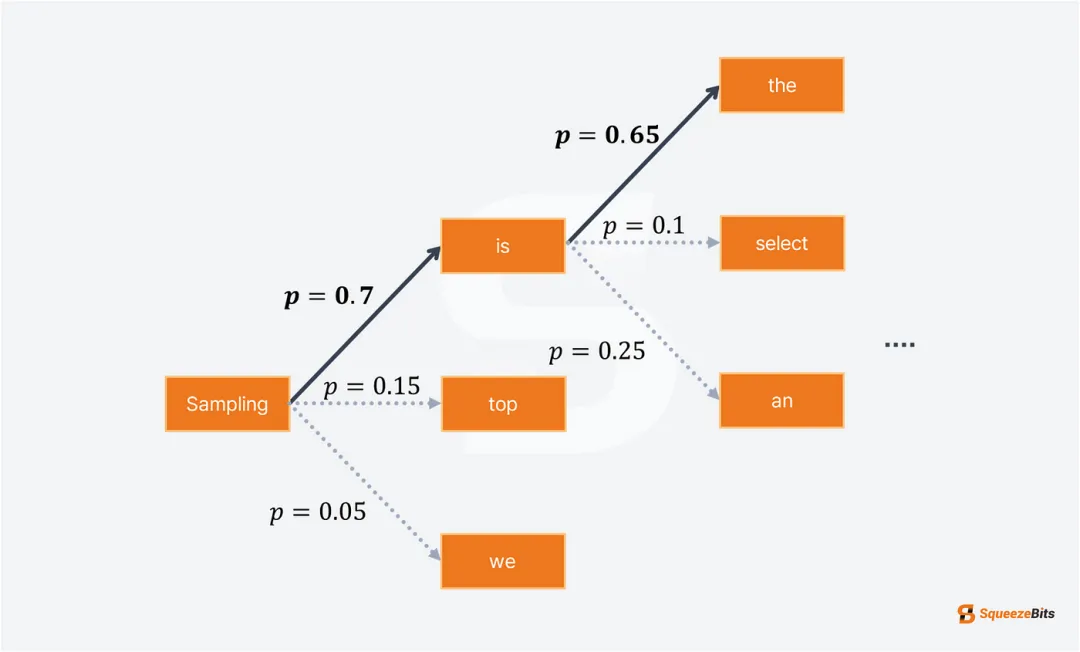
贪心采样在每次迭代中简单地选择概率最高的 token
top-K 采样
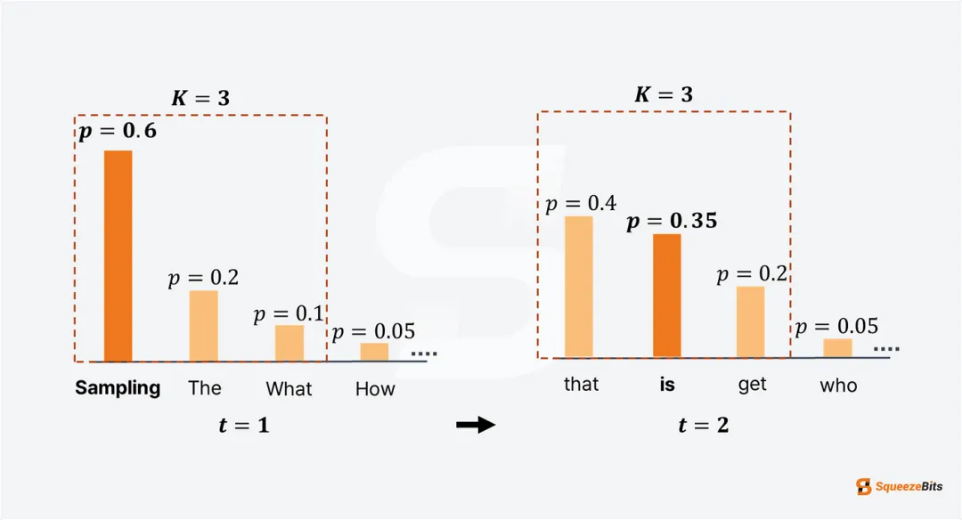
为了提高输出多样性,引入了基于采样的方法,例如 Top-K 采样。
Top-K 采样允许概率较高但非最高的 token 也有机会被选择。
核心做法:
LLM 根据 token 的概率进行排名,仅保留概率最高的 K 个 token。然后对这些 K 个 token 的概率进行归一化,以确保总和为 1,并根据归一化后的概率随机选择下一个 token。
这种方法引入了受控的随机性,有助于生成更具多样性的输出,同时仍能避免选择概率极低的 token。
Top-P(核采样)
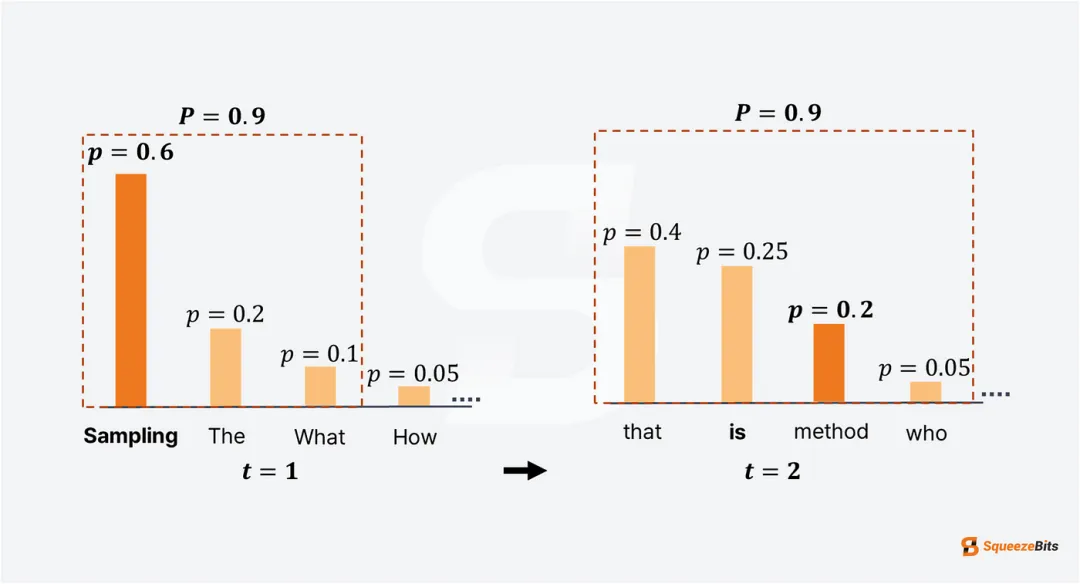
核心做法:
Top-P 采样,又称核采样,与 Top-K 采样类似,但在候选 token 集的选择方式上有所不同。Top-P 采样不是限制为固定数量的 token(K),而是动态选择概率累积值超过预设阈值 P(例如 0.9)的 token 集。
这种动态方法提供了更大的灵活性,
候选 token 的数量可以根据生成的上下文而变化。通过调整阈值 P,模型可以控制每一步中被考虑的 token 数量,从而在生成输出的多样性和连贯性之间取得平衡。
同时使用
注意,Top-K 和 Top-P 采样可以结合使用,如以下示例所示。当结合使用时,token 集首先被限制为 K 个候选,然后进一步缩小到满足概率累积阈值 P 的 token。
举例:
使用 Top-K(K=50)和 Top-P(P=0.9)生成的输出:
“It’s time to get up.\nI’m sure you’re still sleeping. You’ve been sleeping for 30 years. You’ve been dreaming of a better life”
Top-K 和 Top-P 采样都高度依赖于 token 的概率分布,而 温度(Temperature, T) 是另一个有用的参数,可以让用户控制概率分布。
降低温度会使概率分布更加集中,从而使模型更有可能选择最高概率的 token。这减少了输出的随机性,生成更连贯、可预测的句子

相反,提高温度会使概率分布更平滑,从而使模型更有可能选择概率较低的 token。这可以生成更具创意和多样化的文本,但也增加了生成不连贯结果的风险
重复惩罚(Repetition Penalty)
重复惩罚是另一种重要的技术,用于减少模型生成重复性输出的概率。这种方法对在之前步骤中已经被选择的 token 进行惩罚,从而降低它们的概率,减少它们再次被选中的可能性。
输入: “Hey, are you conscious?”
使用贪心采样生成的输出:
“I mean, are you really conscious? I mean, are you really conscious of your consciousness? I mean, are you really conscious of your consciousness of your consciousness”
使用重复惩罚(1.1)生成的输出:
“I mean really conscious?\nI’m not talking about being aware of your surroundings or the people around you. I’m talking about being aware of yourself and what’s”
结合 Top-K(K=50)、Top-P(P=0.9)和重复惩罚(1.1)生成的输出:
“I’m just asking. You know what I mean: Are you really awake and aware of your life?\nI have a friend who is always saying she’s “”
通过调整重复惩罚参数,用户可以减少退化现象,同时保持句子的连贯性。然而,较高的惩罚可能导致输出的连贯性下降,因为它可能过度惩罚那些对句子结构至关重要的 token。
例如:谓语 是 不让他在句子中出现 就很难描述一个东西。
实现方法:
频率惩罚(Frequency Penalty) 和 存在性惩罚(Presence Penalty)。两者通过从 logits 中减去一定数值来施加惩罚,
重复惩罚则通过缩放 logits 实现
惩罚方法可以与 Top-P 和/或 Top-K 采样并行使用。结合采样方法后,LLM 能够生成更具多样性和创意的句子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号