大模型--数据类型FP16 BF16--29
1. 参考
https://blog.csdn.net/voiiid/article/details/114825246
https://blog.csdn.net/shizheng_Li/article/details/144140912
2. 半精度浮点fp16
这两种数据类型编程是经常遇见
双精度double,64位
单精度float,32位
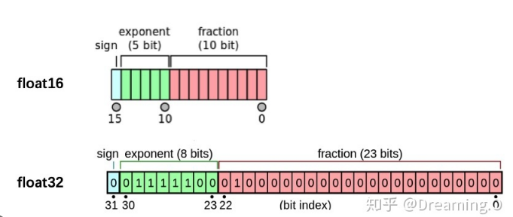
FP16 (Half-precision floating-point format)
它提供更高的精度,尤其是对于表示较小数字的精度要求较高。由于尾数位较多(10位),FP16在表示小数部分时更精确。
符号位(1位) | 指数位(5位) | 尾数位(10位)
BF16 (Brain Floating Point)
BF16的设计目的是平衡大范围数值表示与存储效率,牺牲部分精度来换取更大的数值范围。它的指数位比FP16多3位,因此能够表示更大的数值范围,但牺牲了精度。
符号位(1位) | 指数位(8位) | 尾数位(7位)
数值范围的差异
由于BF16的指数位较大(8位),数值范围比FP16要宽得多。
FP16的指数部分只有5位,这限制了它可以表示的数值范围。
BF16的指数部分有8位,允许它表示的数值范围更广,适合处理一些需要大范围数值的任务,如神经网络中的梯度更新。
FP16 的指数范围:约为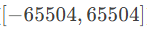
BF16 的指数范围:约为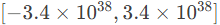
BF16能够处理比FP16更大或更小的数值。
BF16 有点专门为神经网络AI而生的一种数据类型,精度不要求太高,只要表示的范围足够大,运算速度足够快,因为神经元的个数多到一定的量级,
这些一点点精度的损失完全可以通过调整其他的神经元来实现精准的推理,反向传播,梯度更新的时候,神经元之间是会协作更新权重的,
精度差异
由于BF16的尾数部分只有7位,而FP16有10位,因此在表示小数部分时,BF16的精度比FP16低。
FP16能提供更多的小数位精度,因此在某些要求高精度的任务中,FP16可能更合适。
性能和存储
显存占用:
由于BF16和FP16都是16位格式,因此它们都比32位浮动数(FP32)要节省显存。这意味着使用BF16或FP16可以在显存较小的GPU上训练更大的模型,或者在相同显存的GPU上运行更多的模型。
计算速度
BF16的较大指数范围使得它更适合深度学习中的大范围梯度计算,特别是在训练大规模神经网络时。
许多现代加速器(如Google的TPU)对BF16进行了硬件优化,因此使用BF16进行训练时,性能可能会优于FP16,尤其是在使用这些硬件时。
应用场景
BF16:BF16的设计初衷是针对深度学习中的训练任务,尤其是那些需要大范围梯度更新的场景。在训练大型神经网络时,使用BF16能显著节省存储空间和提高计算效率,尤其在Google TPU、NVIDIA A100等硬件上,BF16的优势更为明显。
FP16:由于精度较高,FP16适合用于对精度要求较高的计算场景,尤其是对于小范围的数值操作。它常见于图像处理、科学计算等领域,也适用于深度学习中的某些计算。
硬件支持
BF16主要由Google的TPU(张量处理单元)提出并优化,并且在NVIDIA的A100 GPU中也提供了对BF16的支持。许多深度学习框架(如TensorFlow和PyTorch)已经开始支持BF16格式。
FP16广泛支持并已在大多数现代GPU上得到硬件加速,特别是NVIDIA的Volta、Turing、Ampere系列GPU。FP16还被许多框架(如TensorFlow、PyTorch)支持,能够通过混合精度训练(Mixed Precision Training)有效提高训练速度。
混合精度训练--存储的是fp32 训练的时候 复制一份fp16 使用fp16进行训练
总结
虽然 FP16 和 BF16 都是16位浮动点数格式,但它们在精度、数值范围和应用场景上有所不同。
对于大多数深度学习训练任务,尤其是大规模神经网络的训练,BF16 由于其更大的数值范围和对硬件优化的优势,越来越成为主流选择。
对于需要较高精度的小范围数值计算的任务,FP16 可能更为合适。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号