大模型-大模型-架构设计-6种设计模式-09
架构设计模式已成为程序员的重要技能。然而,当我们转向大模型应用领域,情况可能会有所不同。面对新兴技术,比如:生成式 AI,我们尚缺乏成熟的设计模式来支撑这些解决方案。
总结了一些针对大模型应用的设计方法和架构模式,试图应对和解决大模型应用实现中的一些挑战,比如:成本问题、延迟问题以及生成的幻觉等问题。
1. 路由分发架构模式
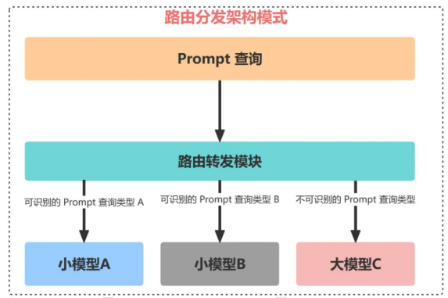
当用户输入一个 Prompt 查询时,该查询会被发送到路由转发模块,而路由转发模块则扮演着对输入 Prompt 进行分类的角色。
如果 Prompt 查询是可以识别的,那么它会被路由到小模型进行处理,这通常是一个更准确、响应更快且成本更低的操作。
如果 Prompt 查询无法被识别,那么它将由大模型来处理。尽管大模型的运行成本较高,但它能够成功返回更多种类型查询的答案。通过这种方式,大模型应用产品可以在成本、性能和用户体验之间实现平衡。
2. 代理架构模式
针对特定任务领域的专家,并行工作以处理特定类型的查询,然后将这些响应整合在一起,形成一个全面的答案。

这样的架构模式非常适合复杂的问题解决场景,在这种场景中,问题的不同方面需要不同的专业知识,就像一个由专家组成的小组,每个专家负责处理更大问题的一个方面。
更大的模型(比如:GPT-4)负责理解上下文,并将其分解为特定的任务或信息请求,这些任务或信息请求被传递给更小的代理模型。这些代理模型可能是较小模型,它们已经接受过特定任务的训练,或者是具有特定功能的通用模型,比如:BERT、Llama-2、上下文提示和函数调用。
3. 基于缓存的微调架构模式
将缓存和微调引入到大模型应用架构中,可以解决成本高、推理速度慢以及幻觉等组合问题。
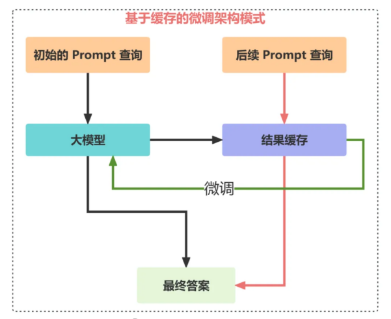
通过缓存初始结果,能够在后续查询中迅速提供答案,从而显著提高了效率。
当我们累积了足够的数据后,微调层将启动,利用早期交互的反馈,进一步完善一个更为专业化的私有大模型。
专有私有大模型不仅简化了操作流程,也使专业知识更好地适应特定任务,使其在需要高度精确性和适应性的环境中,比如:客户服务或个性化内容创建,表现得更为高效。
4.面向目标的 Agent 架构模式
对于用户的 Prompt 提示词,Agent 会基于大模型先做规划(Planning),拆解成若干子任务,然后对每个子任务分别执行(Action),同时对每一步的执行结果进行观测(Observation),如果观测结果合格,就直接返回给用户最终答案,如果观测结果不合格或者执行出错,会重新进行规划(Replanning)。
这种面向目标的 Agent 架构模式非常常见,也是 AGI 大模型时代,每一个程序员都需要掌握的架构设计模式。
5. Agent 智能体组合架构模式
该架构设计模式强调了灵活性,通过模块化 AI 系统,能自我重新配置以优化任务性能。
这就像一个多功能工具,可以根据需求选择和激活不同的功能模块,对于需要为各种客户需求或产品需求定制解决方案的企业来说,这是非常有效的。
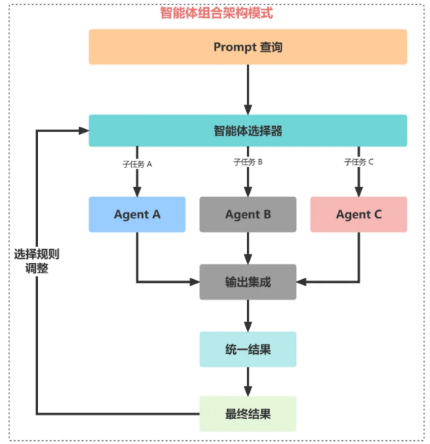
我们可以通过使用各种自主代理框架和体系结构来开发每个 Agent 智能体,比如:CrewAI、Langchain、LLamaIndex、Microsoft Autogen 和 superAGI等。
通过组合不同的模块,一个 Agent 可以专注于预测,一个处理预约查询,一个专注于生成消息,一个 Agent 来更新数据库。将来,随着专业 AI 公司提供的特定服务的增多,我们可以将一个模块替换为外部或第三方服务,以处理特定的任务或领域的问题。
6. 双重安全架构设计模式
大模型的核心安全性至少包含两个关键组件:一是用户组件,我们将其称为用户 Proxy 代理;二是防火墙,它为大模型提供了保护层。
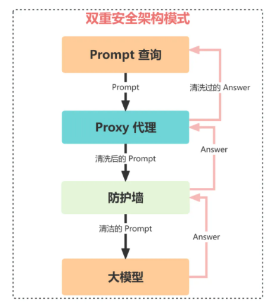
用户 Proxy 代理在查询发出和返回的过程中对用户的 Prompt 查询进行拦截。该代理负责清除个人身份信息和知识产权信息,记录查询的内容,并优化成本。
防火墙则保护大模型及其所使用的基础设施。尽管我们对人们如何操纵大模型以揭示其潜在的训练数据、潜在功能以及当今恶意行为知之甚少,但我们知道这些强大的大模型是脆弱的。
在安全性相关的技术栈中,可能还存在其他安全层,但对于用户的查询路径来说,Proxy 代理和防火墙是最关键的。

