深度学习--模型优化--神经网络知识蒸馏--93
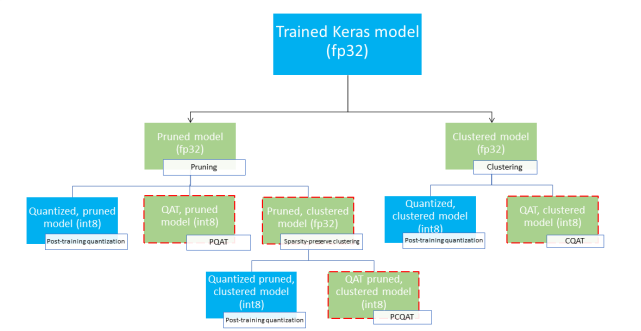
1. 剪枝、聚类、量化协同
协同优化,即将剪枝、聚类、量化同时使用,用于减小模型体积、加速推理速度。
1 使用工具转换器的默认量化功能
2 有代表性的数据集可以进行整数量化
3 如果希望在GPU上加速模型,可以使用float16优化,或TensorRT
4 如果模型大小是瓶颈,要缩减静态模型的大小,可以使用剪枝API训练模型
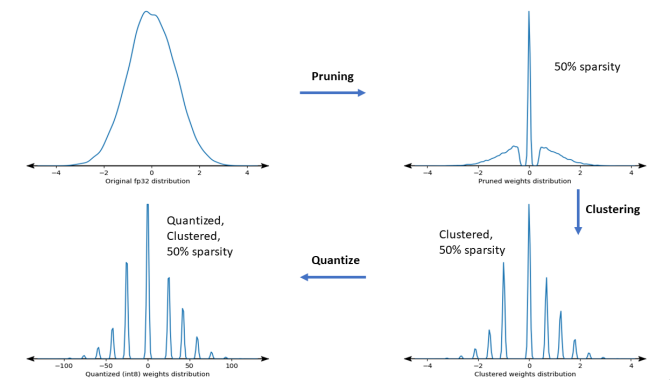
原始的float32-->剪枝使得大部分集中的0附近-->聚类量化-->整形量化
2.知识蒸馏
用一个已经训练好的模型A去“教”另外一个模型B。这两个模型称为老师-学生模型。通常模型A比模型B更强,在模型A的帮助下,模型B可以突破自我,学得更好。

训练集输入一张图片西红柿【1,0,0】,它是西红柿,它就是只是西红柿,
有老师教:【0.7,0.29,0.01】,它是西红柿,但它跟柿子长的挺像,跟西瓜差别大,这就是 潜在的知识,
Dark Knowledge and Softmax Temperature:
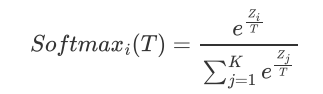
当温度T=1,获得的概率是所谓的unsoftened。
温度T是和一个网络中隐藏层的节点数相关的。例如,隐藏层有300个节点,温度设置为8比较好,相反节点数为30,那么设置在2.5到4之间最好。
更高的温度,会得到更softer的概率值。
举例:
[cow, dog, cat, car] 如果我们有一张图片是狗,unsoftened hardtarget [0, 1, 0, 0]
softening,我们也许可以得到[0.05, 0.3, 0.2, 0.005],它清晰的说明预测是一头牛的概率是一辆汽车的概率的十倍。
这就是需要从teacher网络中蒸馏出来的‘dark’ knowledge,回头给到student网络中。
Teacher Student Model
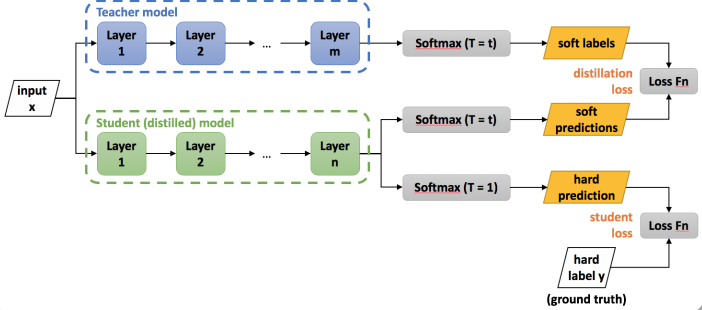
Total loss = distillation loss + student loss
distillation loss: 计算分布之间的相似度,使用KL散度
student loss:普通的交叉熵损失
知识蒸馏与正则项:

正则项是人们的prior(先验知识)

distillation loss是来自于teacher model的先验知识
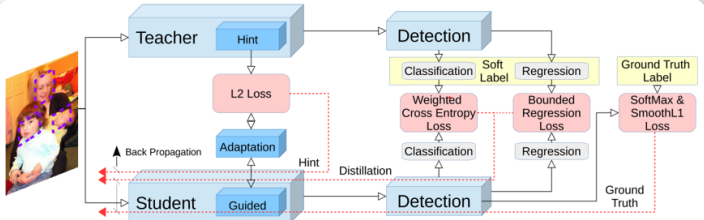
知识蒸馏用于目标检测:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号