深度学习--模型优化--模型的量化--92
1. 什么是量化
量化可以理解为:从连续到离散,针对parameters(W)、activations(A)使用整数值取代浮点数值,
模型尺寸更小
改进inference时间
减小内存使用
更低的功耗/能量(单位焦耳)
一些GPUs支持
FPGAs和ASICs能够更激进的量化
量化技术的发展:
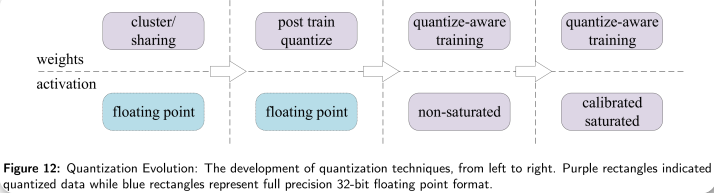
可量化的对象:输入值、特征值、权重\偏置项、误差\梯度值
量化位宽:1bit、8bit、3/4/6bit、float16、混合bit(不同层不同位宽)
神经网络的量化:高精度(位宽)转化成低精度(位宽),比如float32 -> float16, int8, int4, int2 等,缩小可表示的空间大小(位宽)bit width
2 位宽,高精度浮点数的表示
exponent / integer bits + fraction / precision bits
32位:


8位

64位:

如果我们从FP32减小位宽到FP16,或使用整数INT8,不就节省内存和计算资源了
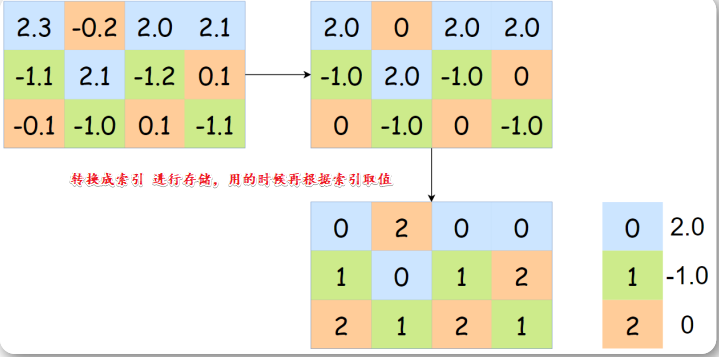
3. K-means 聚类量化
将参数一维数组进行聚类

所下图所示权重矩阵的所有参数可以聚类为 4 个类别,不同的类别使用不同的颜色表示。
上半部分的权重矩阵可以取聚类中心,并储存在 centroids 向量中,
随后原来的权重矩阵只需要很少的空间储存对应的索引。
下半部是韩松等研究者利用反向传播的梯度对当前centroids 向量进行修正的过程。 注意这里有个根据weight颜色进程group的操作
这种量化过程能大量降低内存的需求,因为我们不再需要储存 FP64 或 FP32 的数据,而只需要储存INT8 或更少占位的数据。
4. 均匀/线性量化(linear quantization)
非对称量化与对称量化
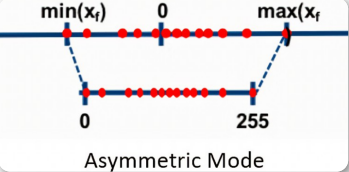
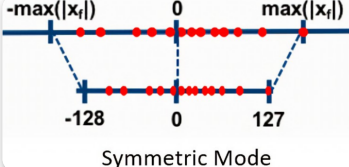
非对称线性量化就是线性缩放肯定是需要bias偏置项的
量化权重为n-bit整数,公式如下:

当然量化之后如果要计算,还需要恢复成原始值进行运算,还原公式:

矩阵相乘-量化加速计算:
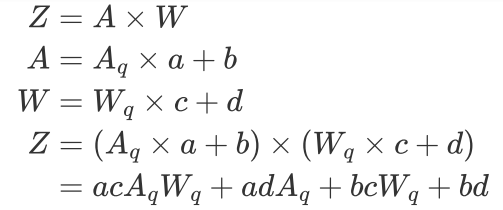

对称线性量化(Symmetric linear quantization):

还原公式:

注意这里没有bias

5. Thresholding量化
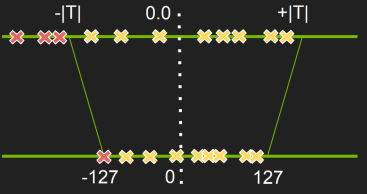
模型为了去拟合一些离群值或异常样本,很有可能学到一些不太常见的参数,从而使得过拟合,对测试集反而失去很大的精度。我们都知道weights越小越可以防止过拟合,将权重压制到-T到T之间。
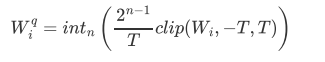
这个T是权重里面的两端,一图胜千言:
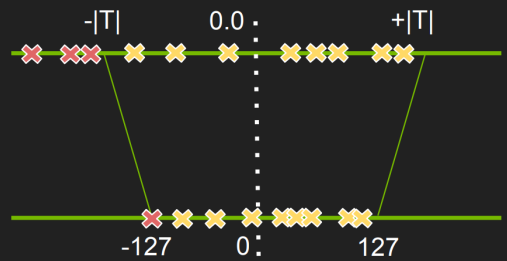
如何选择合适的 threshold?
使用Calibration数据集运行 FP32 inference --注意需要使用较正数据集
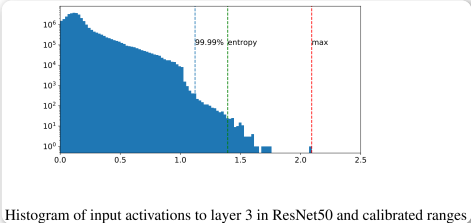
对于每一层layer,获得activations,并构建直方图(也就是统计落在每个区间有多少个)
使用各种不同的thresholds去生成许多量化的值分布,
选择可以使得量化的分布(quant_distr)和inference输出activations的分布(ref_distr)之间,最接近的threshold,
也就是要计算很多KL_divergence(ref_distr, quant_distr),选最小的KL对应的threshold,
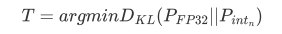
整个过程也许会花费几分钟,这也是为什么量化时往往要传入数据集Calibration dataset的原因。
但是还是值得去做的。
计算Calibration(Calibration就是Threshold阈值,用于进行缩放量化)的三种方式:
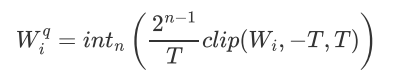
Max:使用绝对值的最大值作为 calibration
Entropy:使用 KL divergence 去最小化原始浮点数和量化之后二者之间的信息损失。TensorRT 中这是默认的方法。
Percentile:设置一个绝对值分布的保留百分比。例如,99% calibration 将会截断 1% 的最大幅度值
6. 何时量化
整体上来说,训练后的优化技术迭代快,容易使用但是对模型精度的损失可能会比较大,
训练中的优化技术,相对难以使用,需要更长的时间来重新训练模型,但是对模型精度的保持比较好。
Post Training Quantization(PTQ)
使用FP32,然后缩放和量化作为后处理步骤,
1 以任意方式训练浮点数模型,
2 导出推理的模型
3 指定转换器所需的优化选项
Quantization-aware training(QAT)
直接训练一个量化的模型
1 使用框架构建模型
2 将QAT API应用到具体某层或某些层,更便捷的是应用到整个模型
3 导出模型到具体的设备上
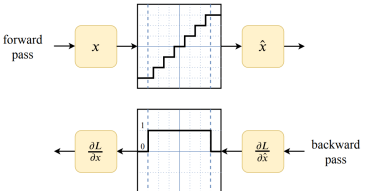
训练过程中forward propagation引入量化误差,backwardpropagation会调整模型的权重,使得它们对量化的容错率更高,这样经过量化后的模型可以更好的保留浮点数的精度。
当正向传播的时候,进行量化,
反向传播求梯度的时候,还是对之前没量化的FP32数值求偏导,然后更新参数
聚类量化代码
import tensorflow as tf
from tensorflow import keras
import tensorflow_model_optimization as tfmot
import numpy as np
import tempfile
import zipfile
import os
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3,3), activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2,2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=["accuracy"])
model.fit(
train_images,
train_labels,
validation_split=0.1,
epochs=10
)
Epoch 1/10
1688/1688 [] - 6s 3ms/step - loss: 2.3012 - accuracy: 0.1132 - val_loss: 2.3020 - val_accuracy: 0.1050
Epoch 2/10
1688/1688 [] - 6s 3ms/step - loss: 2.3012 - accuracy: 0.1132 - val_loss: 2.3019 - val_accuracy: 0.1050
Epoch 3/10
1688/1688 [] - 6s 3ms/step - loss: 2.3012 - accuracy: 0.1132 - val_loss: 2.3024 - val_accuracy: 0.1050
Epoch 4/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3020 - val_accuracy: 0.1050
Epoch 5/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3020 - val_accuracy: 0.1050
Epoch 6/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3023 - val_accuracy: 0.1050
Epoch 7/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3020 - val_accuracy: 0.1050
Epoch 8/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3020 - val_accuracy: 0.1050
Epoch 9/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3018 - val_accuracy: 0.1050
Epoch 10/10
1688/1688 [] - 6s 3ms/step - loss: 2.3013 - accuracy: 0.1132 - val_loss: 2.3021 - val_accuracy: 0.1050
<keras.callbacks.History at 0x191caa0f9d0>
_, baseline_model_accuracy = model.evaluate(test_images, test_labels, verbose=0)
print("baseline_model_accuracy:", baseline_model_accuracy)
baseline_model_accuracy: 0.11349999904632568
keras_file = "./models/mnist.h5"
print("Saving model to:", keras_file)
tf.keras.models.save_model(model, keras_file, include_optimizer=False)
Saving model to: ./models/mnist.h5
# 使用聚类API
cluster_weights = tfmot.clustering.keras.cluster_weights
CentroidInitialization = tfmot.clustering.keras.CentroidInitialization
clustering_params = {
"number_of_clusters": 16,
"cluster_centroids_init": CentroidInitialization.LINEAR
}
# 聚类整个模型
clustered_model = cluster_weights(model, **clustering_params)
# 使用小的学习率进行 fine-tuning 聚类的模型
opt = tf.keras.optimizers.Adam(learning_rate=1e-5)
clustered_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=opt,
metrics=["accuracy"]
)
clustered_model.summary()
clustered_model.fit(
train_images,
train_labels,
batch_size=500,
epochs=1,
validation_split=0.1
)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
cluster_reshape (ClusterWei (None, 28, 28, 1) 0
ghts)
cluster_conv2d (ClusterWeig (None, 26, 26, 12) 244
hts)
cluster_max_pooling2d (Clus (None, 13, 13, 12) 0
terWeights)
cluster_flatten (ClusterWei (None, 2028) 0
ghts)
cluster_dense (ClusterWeigh (None, 10) 40586
ts)
=================================================================
Total params: 40,830
Trainable params: 20,442
Non-trainable params: 20,388
_________________________________________________________________
108/108 [==============================] - 4s 29ms/step - loss: 2.3011 - accuracy: 0.1132 - val_loss: 2.3021 - val_accuracy: 0.1050
<keras.callbacks.History at 0x191d6b1d790>
_, clustered_model_accuracy = clustered_model.evaluate(test_images, test_labels, verbose=0)
print("baseline_model_accuracy:", baseline_model_accuracy)
print("clustered_model_accuracy:", clustered_model_accuracy)
baseline_model_accuracy: 0.11349999904632568
clustered_model_accuracy: 0.11349999904632568
# strip_clustering 会移除聚类仅在训练期间才需要的所有变量
final_model = tfmot.clustering.keras.strip_clustering(clustered_model)
clustered_keras_file = "./models/mnist_clustered.h5"
converter = tf.lite.TFLiteConverter.from_keras_model(final_model)
tflite_clustered_model = converter.convert()
with open(clustered_keras_file, "wb") as f:
f.write(tflite_clustered_model)
print("saved clustered TFlite model to:", clustered_keras_file)
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op while saving (showing 1 of 1). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: C:\Users\C30004~1\AppData\Local\Temp\tmpizar29oy\assets
INFO:tensorflow:Assets written to: C:\Users\C30004~1\AppData\Local\Temp\tmpizar29oy\assets
saved clustered TFlite model to: ./models/mnist_clustered.h5
# 通过 gzip 实际压缩模型并测量压缩后的大小
def get_gzipped_model_size(file):
_, zipped_file = tempfile.mkstemp(".zip")
with zipfile.ZipFile(zipped_file, "w", compression=zipfile.ZIP_DEFLATED) as f:
f.write(file)
return os.path.getsize(zipped_file)
# 聚类后的模型应用训练后量化
converter = tf.lite.TFLiteConverter.from_keras_model(final_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op while saving (showing 1 of 1). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: C:\Users\C30004~1\AppData\Local\Temp\tmprtvzr62u\assets
INFO:tensorflow:Assets written to: C:\Users\C30004~1\AppData\Local\Temp\tmprtvzr62u\assets
quantized_and_clustered_tflite_file = "./models/quantized_clustered_mnist.tflite"
with open(quantized_and_clustered_tflite_file, "wb") as f:
f.write(tflite_quant_model)
print("Saved quantized and cluster TFlite model to:", quantized_and_clustered_tflite_file)
print("Size of gzip baseline Keras model: %.2f bytes" % (get_gzipped_model_size(keras_file)))
print("Size of gzipped cluster and quantized TFLite model: %.2f bytes" % (get_gzipped_model_size(quantized_and_clustered_tflite_file)))
Saved quantized and cluster TFlite model to: ./models/quantized_clustered_mnist.tflite
Size of gzip baseline Keras model: 77694.00 bytes
Size of gzipped cluster and quantized TFLite model: 13208.00 bytes
# 定义函数查看准确率
interpreter = tf.lite.Interpreter(model_content=tflite_quant_model)
interpreter.allocate_tensors()
def eval_model(interpreter):
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
predict_digits = []
for i, test_image in enumerate(test_images):
if i % 100 == 0:
print("Eval on {n} results so far.".format(n=i))
test_image = np.expand_dims(test_image, axis=0).astype(np.float32)
interpreter.set_tensor(input_index, test_image)
interpreter.invoke()
output = interpreter.tensor(output_index)
digit = np.argmax(output()[0])
predict_digits.append(digit)
print("\n")
predict_digits = np.array(predict_digits)
accuracy = (predict_digits == test_labels).mean()
return accuracy
test_accuracy = eval_model(interpreter)
print("Cluster and quantized TFLite accuracy:", test_accuracy)
print("Cluster TF test accuracy:", clustered_model_accuracy)
Eval on 0 results so far.
Eval on 100 results so far.
Eval on 200 results so far.
Eval on 300 results so far.
Eval on 400 results so far.
Eval on 500 results so far.
Eval on 600 results so far.
Eval on 700 results so far.
Eval on 800 results so far.
Eval on 900 results so far.
Eval on 1000 results so far.
Eval on 1100 results so far.
Eval on 1200 results so far.
Eval on 1300 results so far.
Eval on 1400 results so far.
Eval on 1500 results so far.
Eval on 1600 results so far.
Eval on 1700 results so far.
Eval on 1800 results so far.
Eval on 1900 results so far.
Eval on 2000 results so far.
Eval on 2100 results so far.
Eval on 2200 results so far.
Eval on 2300 results so far.
Eval on 2400 results so far.
Eval on 2500 results so far.
Eval on 2600 results so far.
Eval on 2700 results so far.
Eval on 2800 results so far.
Eval on 2900 results so far.
Eval on 3000 results so far.
Eval on 3100 results so far.
Eval on 3200 results so far.
Eval on 3300 results so far.
Eval on 3400 results so far.
Eval on 3500 results so far.
Eval on 3600 results so far.
Eval on 3700 results so far.
Eval on 3800 results so far.
Eval on 3900 results so far.
Eval on 4000 results so far.
Eval on 4100 results so far.
Eval on 4200 results so far.
Eval on 4300 results so far.
Eval on 4400 results so far.
Eval on 4500 results so far.
Eval on 4600 results so far.
Eval on 4700 results so far.
Eval on 4800 results so far.
Eval on 4900 results so far.
Eval on 5000 results so far.
Eval on 5100 results so far.
Eval on 5200 results so far.
Eval on 5300 results so far.
Eval on 5400 results so far.
Eval on 5500 results so far.
Eval on 5600 results so far.
Eval on 5700 results so far.
Eval on 5800 results so far.
Eval on 5900 results so far.
Eval on 6000 results so far.
Eval on 6100 results so far.
Eval on 6200 results so far.
Eval on 6300 results so far.
Eval on 6400 results so far.
Eval on 6500 results so far.
Eval on 6600 results so far.
Eval on 6700 results so far.
Eval on 6800 results so far.
Eval on 6900 results so far.
Eval on 7000 results so far.
Eval on 7100 results so far.
Eval on 7200 results so far.
Eval on 7300 results so far.
Eval on 7400 results so far.
Eval on 7500 results so far.
Eval on 7600 results so far.
Eval on 7700 results so far.
Eval on 7800 results so far.
Eval on 7900 results so far.
Eval on 8000 results so far.
Eval on 8100 results so far.
Eval on 8200 results so far.
Eval on 8300 results so far.
Eval on 8400 results so far.
Eval on 8500 results so far.
Eval on 8600 results so far.
Eval on 8700 results so far.
Eval on 8800 results so far.
Eval on 8900 results so far.
Eval on 9000 results so far.
Eval on 9100 results so far.
Eval on 9200 results so far.
Eval on 9300 results so far.
Eval on 9400 results so far.
Eval on 9500 results so far.
Eval on 9600 results so far.
Eval on 9700 results so far.
Eval on 9800 results so far.
Eval on 9900 results so far.
Cluster and quantized TFLite accuracy: 0.1135
Cluster TF test accuracy: 0.11349999904632568

 浙公网安备 33010602011771号
浙公网安备 33010602011771号