深度学习-语音识别-gm与hmm参数的学习--81
1. GMM HMM参数的学习
GMM -->声学模型 声学特征与音素的映射关系

HMM -->语言模型 已经直到发音 决绝如何得到正确的文本
一个发硬会对应多个文本 哪种文本串联起来 才是意思通顺的
在GMM-HMM中,需要训练的参数是状态迁移概率和各个状态的概率密度函数。模型训练中有一个问题,那就是对于训练数据,我们不知道其状态迁移是什么样的。
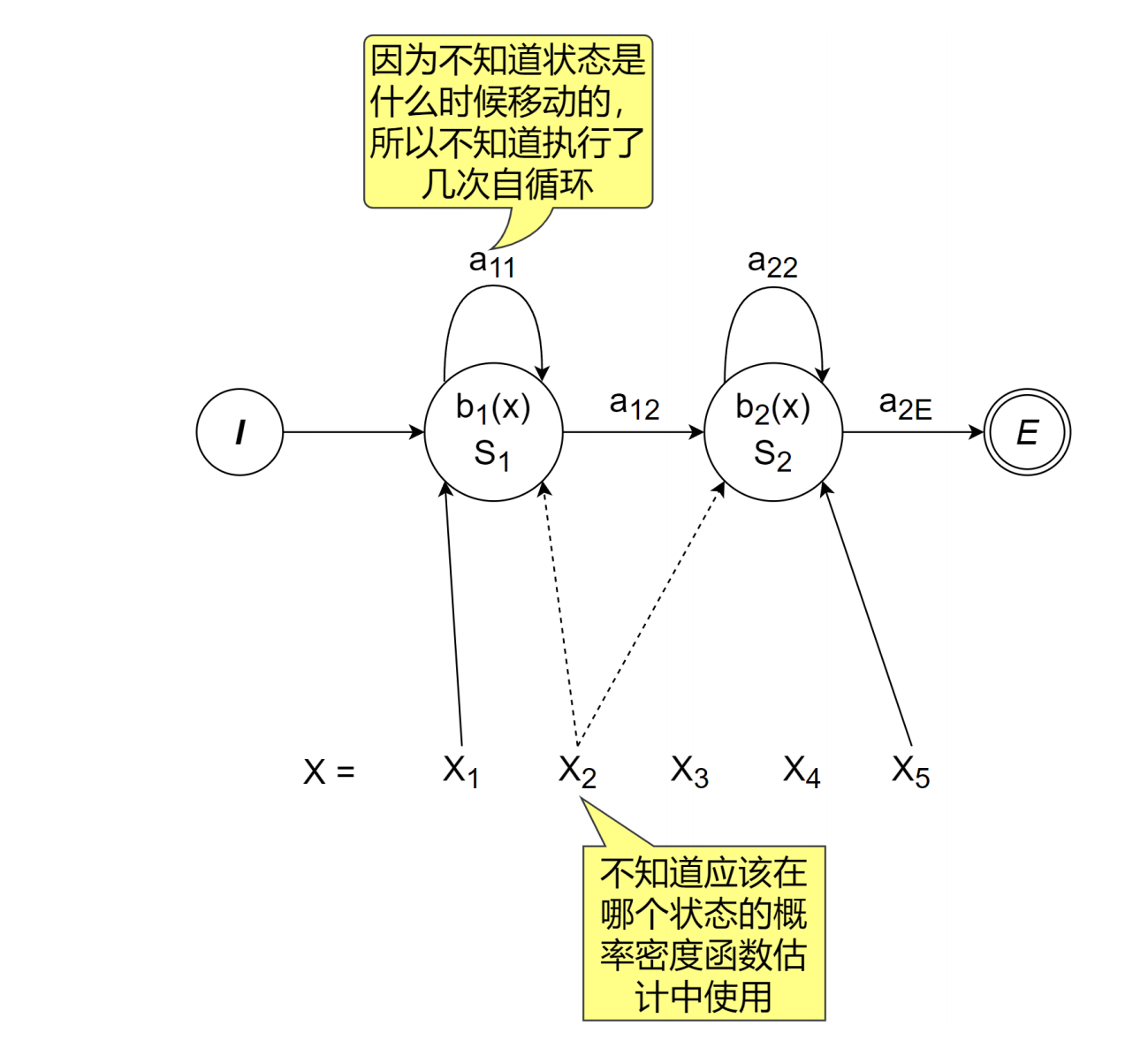
如果训练数据的状态迁移是已知的,那么数一数状态迁移的数量就能对HMM中状态迁移概率进行训练,而根据每个音素对应的特征向量集合便可以对GMM进行训练;

确实不知道状态迁移序列的发生概率,因此只能投放终极秘密武器--最大期望算法,即EM算法。
EM算法的执行步骤汇总如下:
1 给HMM的参数设定适当的初始值。
2 E步骤:
对于训练数据(输入),用现在的HMM来计算状态迁移的
发生概率;
对所有可能的状态迁移序列,求其发生概率。
3 M步骤:
对所有可能的状态迁移序列,求对应HMM参数的最大似然估计;
以E步骤求得的状态迁移概率为权重,对最大似然估计结果求加权和。
4 对E步骤、M步骤进行循环,直到M步骤的参数变化量小于一定的值。
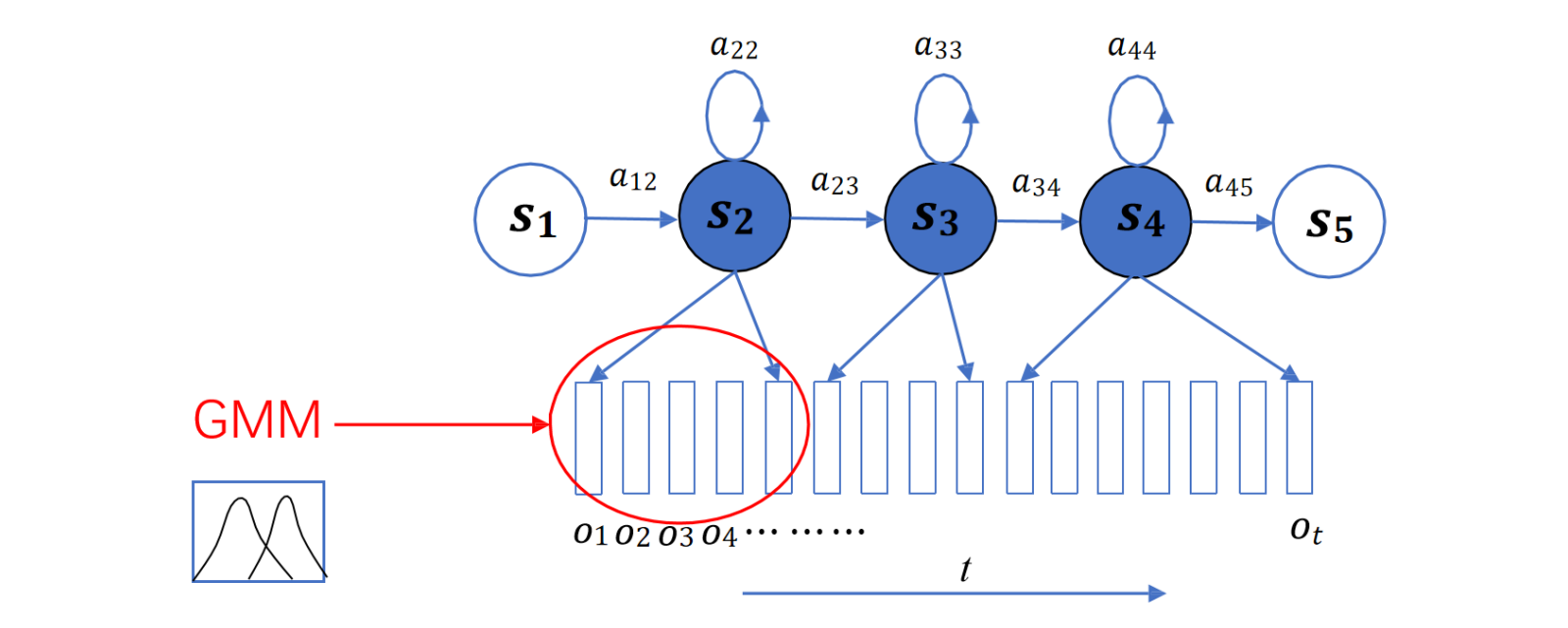
每一个发射状态对应一个gauss
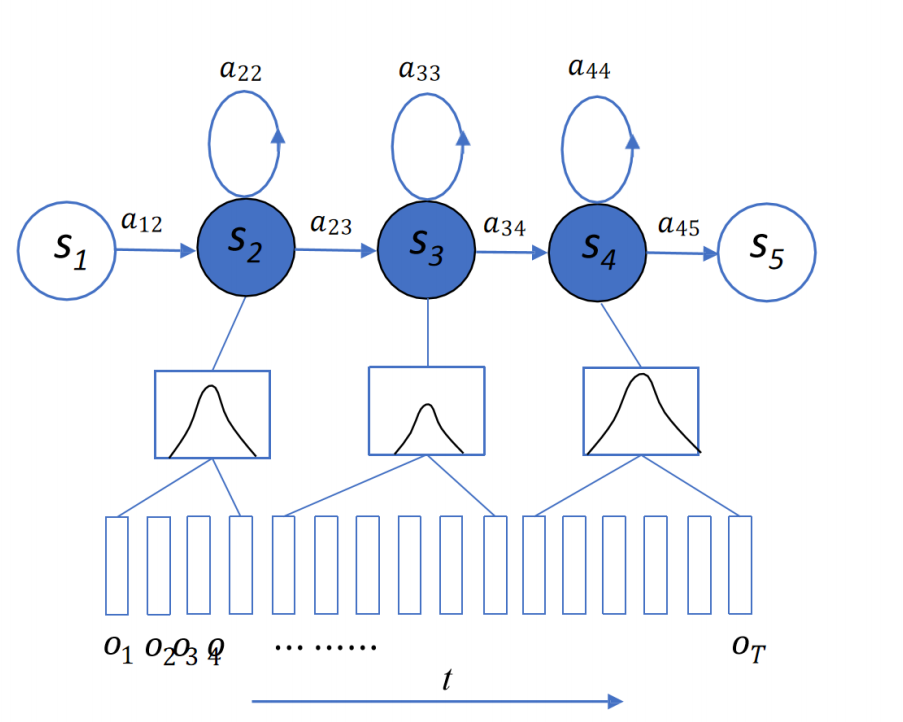
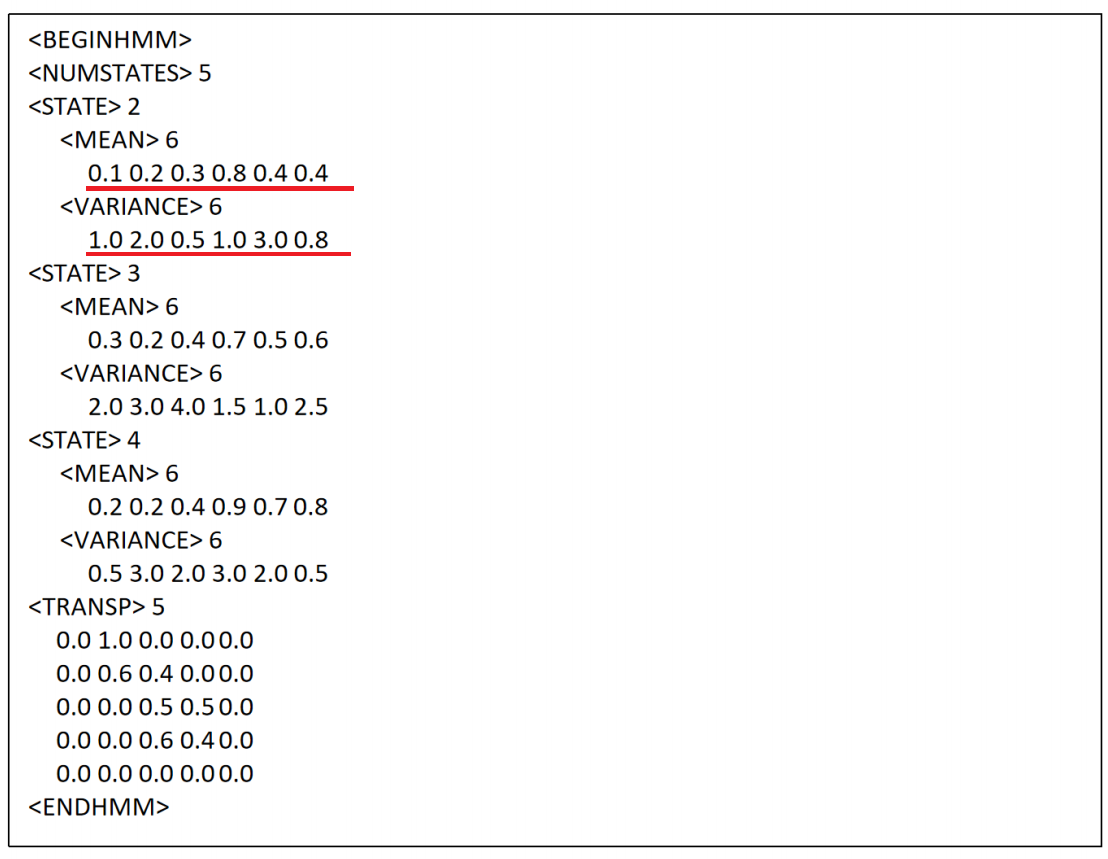
转移矩阵发生矩阵参数列表:
每个发生状态4个gauss
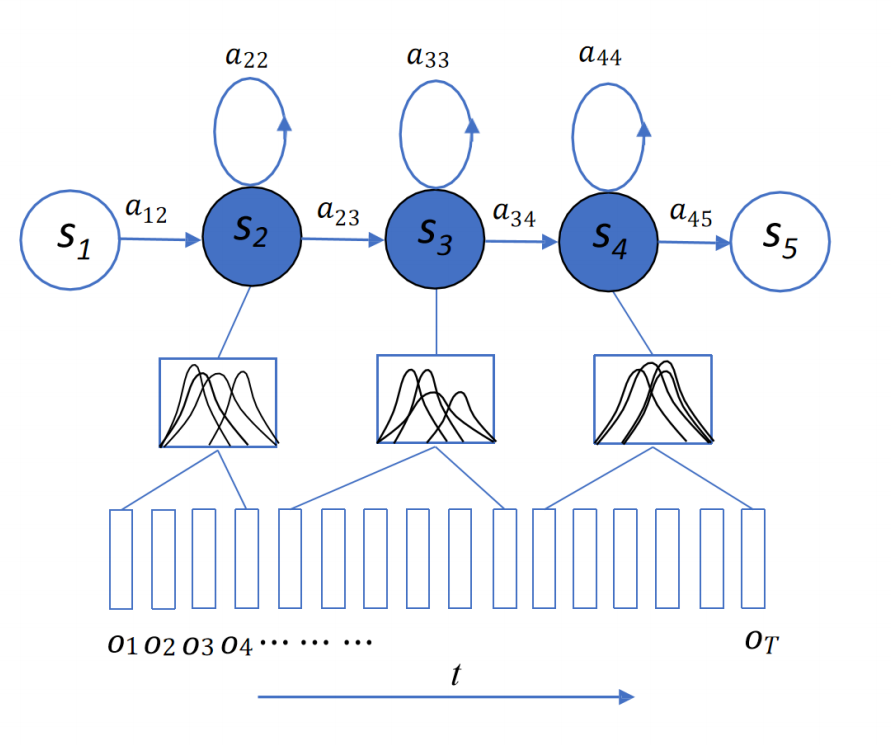
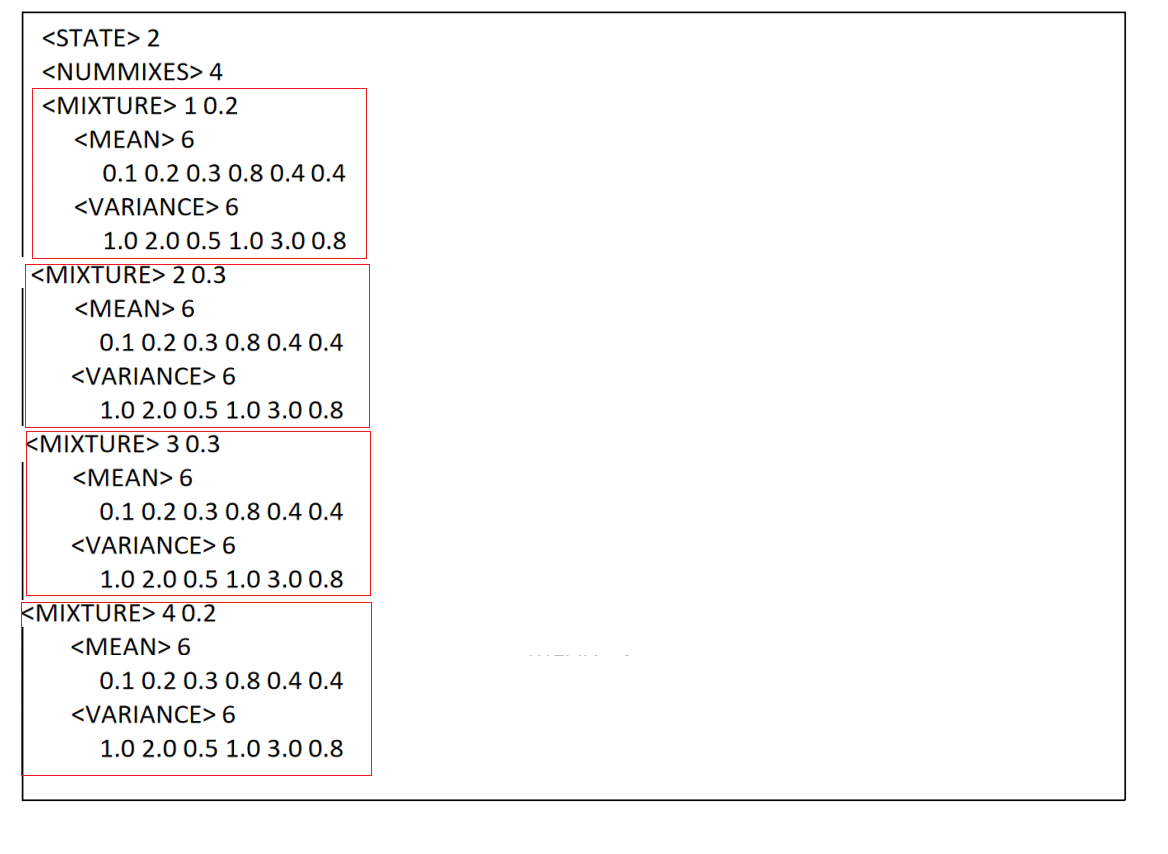
2. GMM概率计算
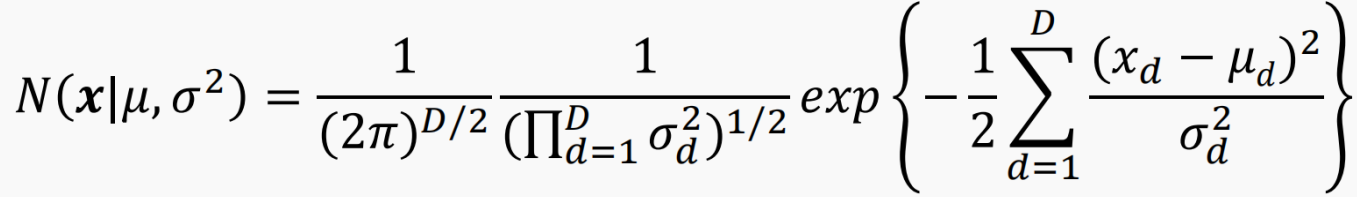

3. 具体训练流程
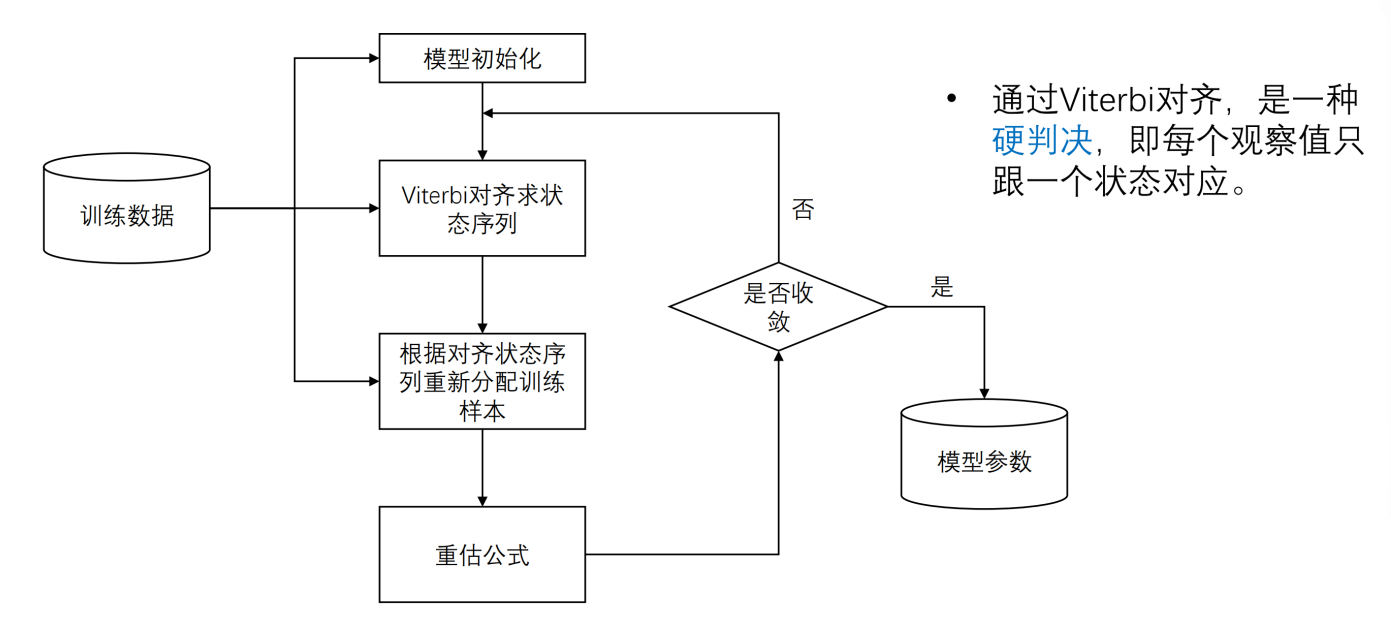
为什么要初始化对齐?为viterbi提供初始参数A、B。 ---- HMM的参数
一开始不知道一段语音的哪些帧对应哪些状态,我们就进行平均分配。
比如两秒的“six”语音一共80帧,分成四个音素“S IH K S”,每个音素分配到20帧,每个音素又有三个状态组成,每个状态分配6或者7帧。
这样就初始化了每个状态对应的输入数据。
说白了,就是假设前0-20帧数据都是“S”这个音素的发音,21-40帧数据都是“IH”这个音素的发音,41-60帧是“K”这个音素的发音,61-80是“S”这个音素的发音。
但这只是一个假设,事实到底如此我们还不知道。我们可以在这个初始对齐下进一步优化。
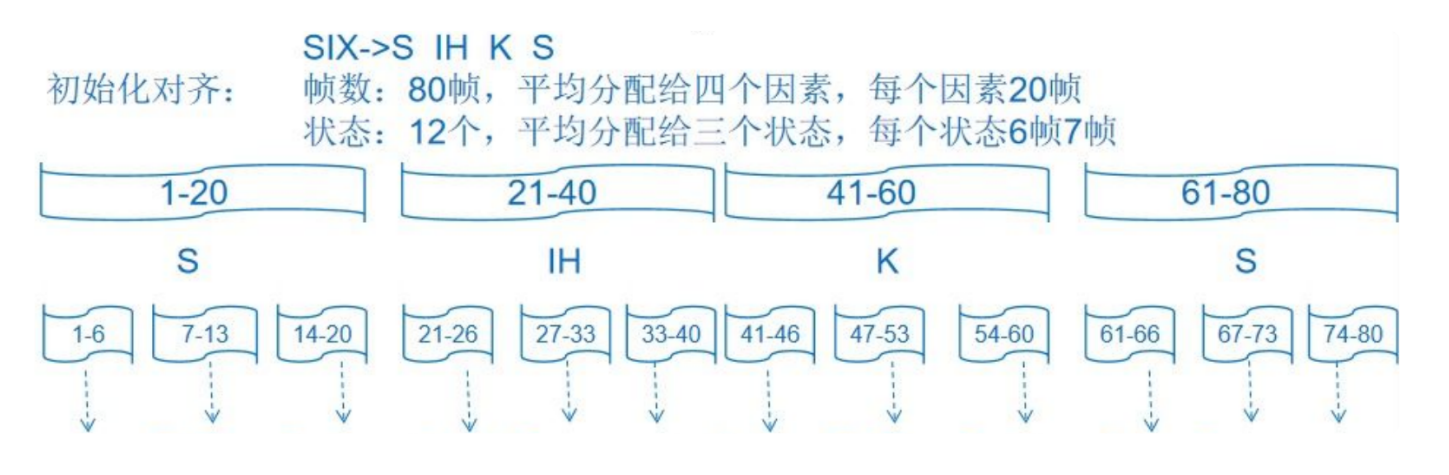
初始化模型
HMM模型λ=(A,B,Π)。我们对初始对齐的模型进行count。
在初始化对齐后就可以count状态1->状态1的次数,状态1->状态2的次数,这就是转移次数,转移次数/总转移次数=转移概率。转移初始转移概率A(aij)就得出了。
π就是[1,0,0,0...],一开始在状态一的概率是100%。在语音识别应用中由于HMM是从左到右的模型,第一个必然是状态一,即P(q0=1)=1。所以没有pi这个参数了。
还有B(bj(ot))参数怎么办?
一个状态对应一个gmm模型,一个状态对应若干帧数据,也就是若干帧数据对应一个gmm模型。
一开始我们不知道哪些帧对应哪个状态,所以gmm模型的输入数据就无从得知。
现在初始化后,状态1对应前6帧数据,我们就拿这六帧数据来计算状态1的gmm模型(单高斯,只有一个分量的gmm),得到初始均值μ和方差σ。
(完美的假想:假设我们初始化分配帧恰恰就是真实的样子,那么我们的gmm参数也是真实的样子,这个模型就已经训练好了。)
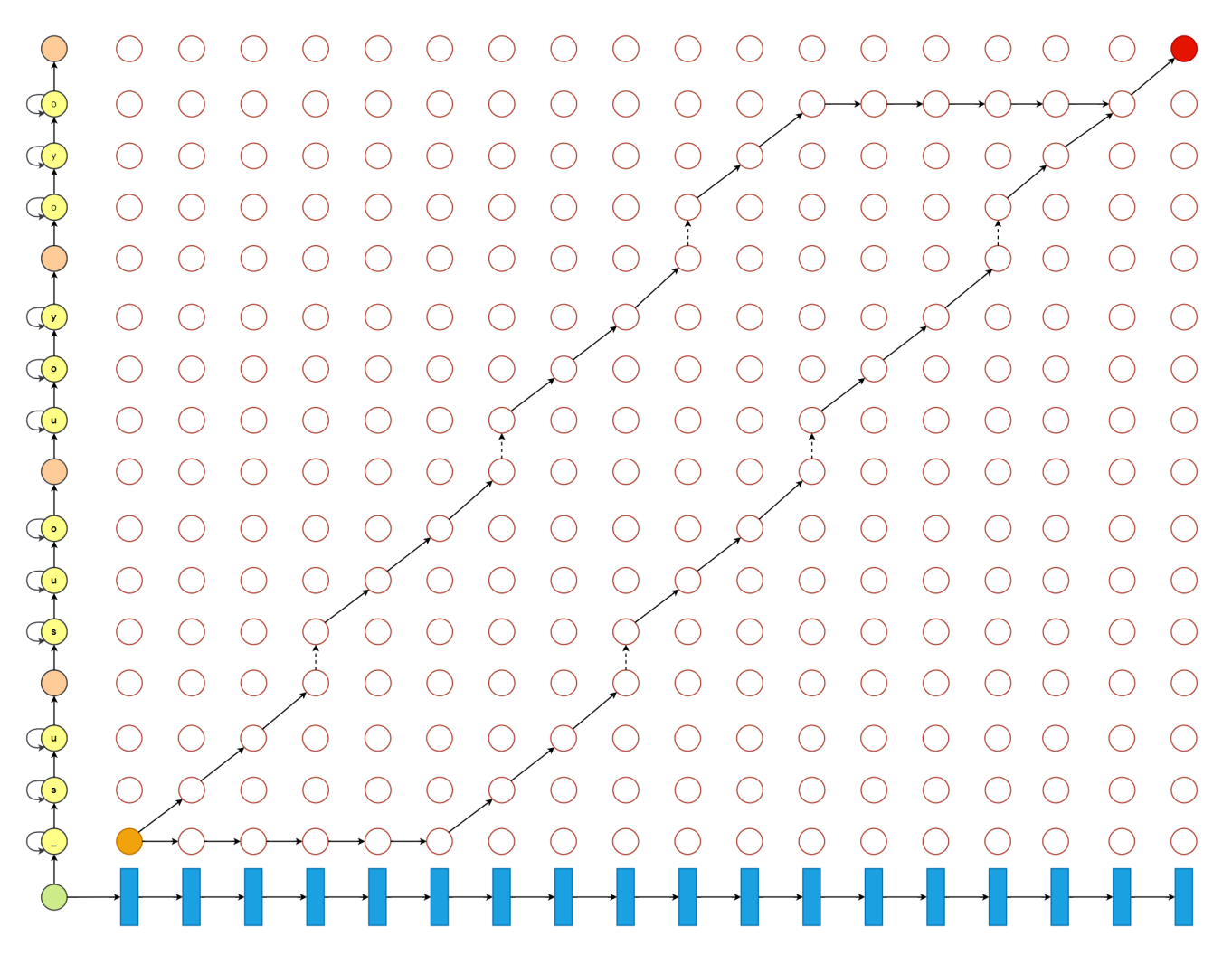
重新对齐(Viterbi硬对齐,Baum-Welch软对齐)
重新对齐,向真实情况逼近的重新对齐。如何逼近真实情况?
viterbi算法根据初始化模型λ=(A,B,π)来计算,它记录每个时刻的每个可能状态的之前最优路径概率。
同时记录最优路径的前一个状态,不断向后迭代,找出最后一个时间点的最大概率值对应的状态,如此向前回溯,得到最优路径。
得到最优路径就得到最优的状态转移情况,
哪些帧对应哪些状态就变了。转移概率A就变了。
哪些帧对应哪些状态变了导致状态对应的gmm参数自然就变了,也可以跟着更新均值 和方差,即发射概率B变了。
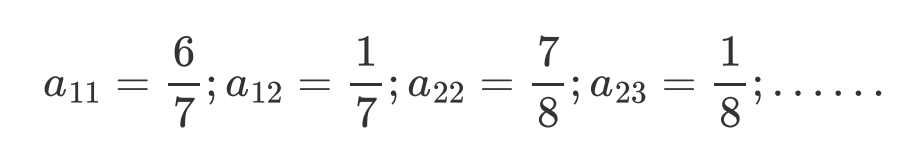
重新对齐之后:
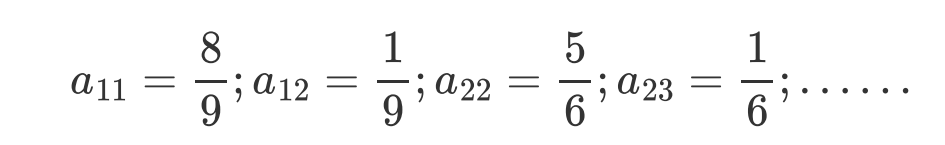
新的A和新的B又可以进行下一次的Viterbi算法,寻找新的最优路径,得到新的对齐,新的对齐继续改变着参数A、B。如此循环迭代直到收敛,则GMM-HMM模型训练完成。
4. 三音素模型

考虑音素所在的上下文(context)进行建模,一般的,
考虑当前音素的前一个(左边)音素和后一个(右边)音素,称之为三音素,并表示为A-B+C的形式,其中B表示当前音素,A表示B的前个音素,C表示B的后一个音素。
使用三音素建模之后,引入了新的问题:
- N个音素,则共有N**3个三音素,若N=100,则建模单元又太多了,每个音素有三个状态,每个状态对应的GMM参数,参数就太多了
- 数据稀疏问题,有的三音素数据量很少
- unseen data问题。有的三音素在训练数据没有出现,如K-K+K,但识别时却有可能出现,这时如何描述未被训练的三音素及其概率
决策树聚类:
所以通常我们会根据数据特征对triphone的状态进行绑定,常见的状态绑定方法有数据驱动聚类和决策树聚类,现在基本上是使用决策树聚类的方式。
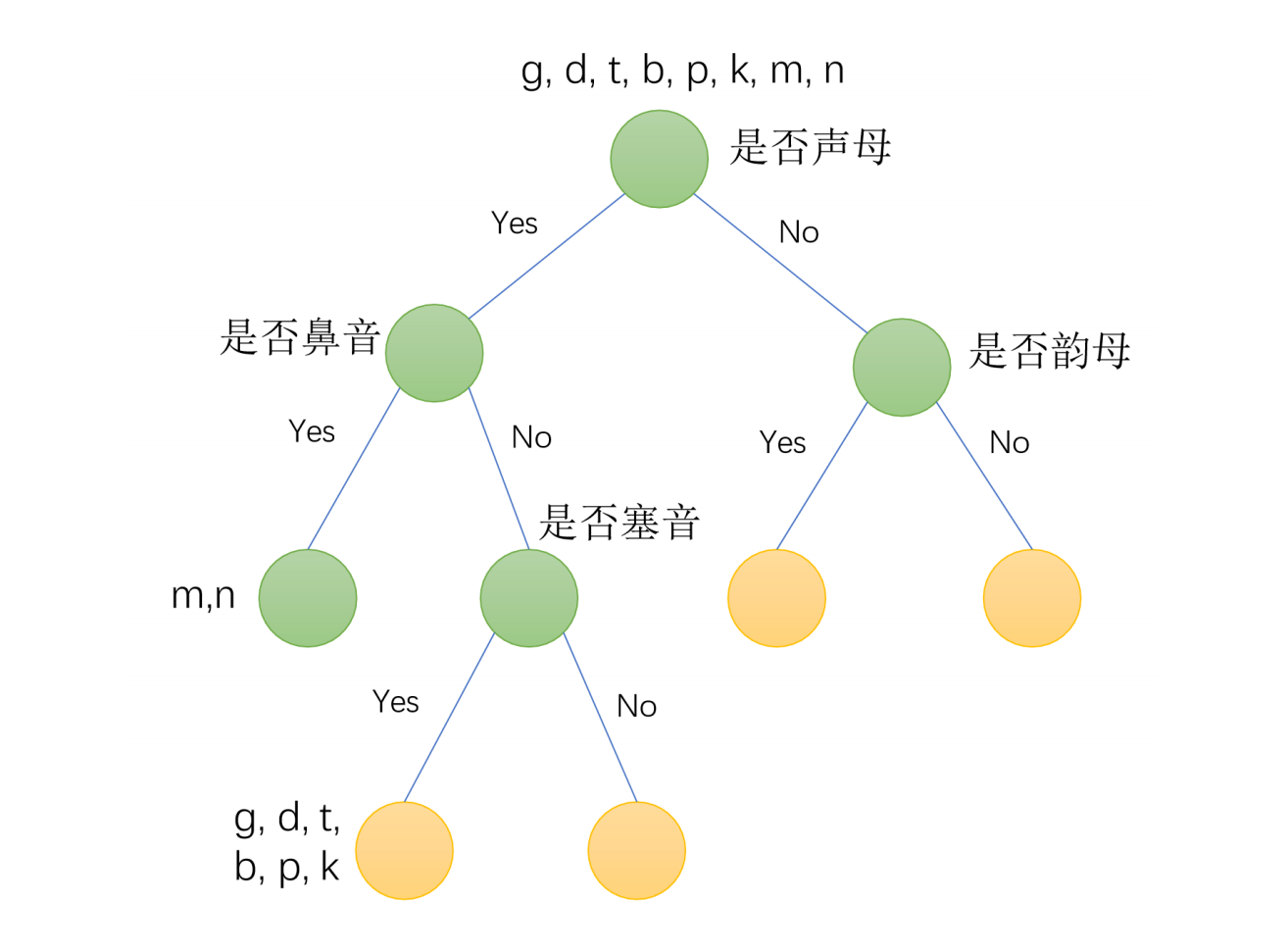
绑定的基本思想:上下文发音相似的三音素共享参数
决策树:二叉树;每个非叶子节点上都会有一个问题;叶子节点是一个绑定三音素的集合(Senone);绑定的粒度为状态;

生成的问题集question.int文件,数字代表音素的id,每一行表示一个音素集(问题):
1 | | 下面多行,构成了一整套问题集,供后面决策树聚类过程使用 |
2 | ---- | --------------------------------- |
3 | | 1 2 28 29 30 31 53 57 58 59 100 104 110 111 112 113 114 130 131 133 134 136 137 150 187 192 197 198 200 201 |
4 | | 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 5 |
5 | | 2 28 29 30 31 57 58 59 100 104 110 111 112 113 114 130 131 133 134 136 197 198 200 201 |
6 | | ...
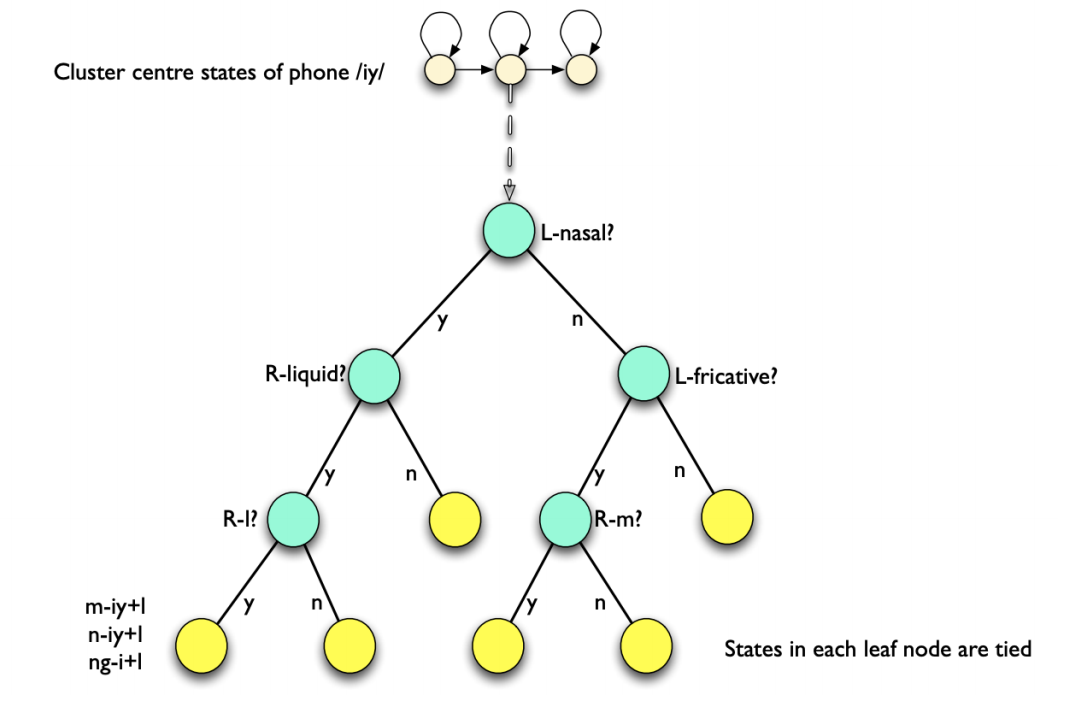
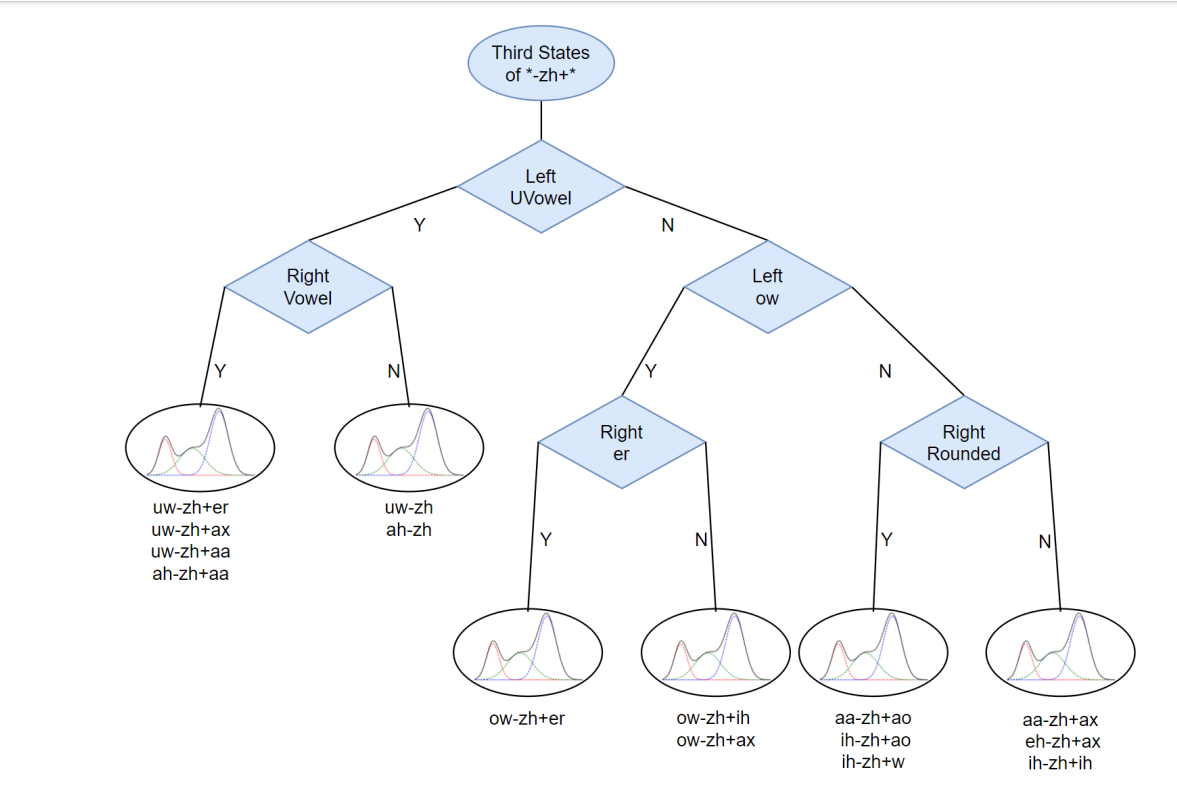
从根节点经过一些列的问题,相近(相似度高)的(绑定)三音素到达同一个叶子节点。决策树建立的基本单元是状态,对每个三音子的每个state建立一颗属于他们自己的决策树。每个三素对于该问题都会有一个Yes或No的的答案,那么对所有的三音素来讲,该问题会把所有三音素分成Yes集合和No集合。根节点是说这是以zh为中心音素的三音素的第三个状态的决策树,第个状态和第二个状态也都有各自独立的决策树即使zh-zh+zh从未在训练语料中出现过,通过决策树,我们最终将它绑定到一个与之相近的叶子节点上。
6. 三音素GMM-HMM模型训练
三音素GMM-HMM模型是在单音素GMM-HMM模型的基础上训练的通过在单音素GMM-HMM模型上viterbi算法得到与输入 对应的最佳状态链,就是得到对齐的结果。
单音素模型--获取对齐
通过单音素系统,我们可以得到单音素各个状态所有对应的特征集合,做一下上下文的扩展,我们可以得到三音素的各个状态所有对应特征集合。通过这样的方法,我们可以把训练数据上所的单音素的数据对齐转为三音素的对齐。
语音识别里的SAT通常指的是speaker adaptive training(说话人自适应)
性别、方言、个人等差异会导致说话人产生的语音特征各不相同。如此一来,若能够生成个人专用的统计模型(即实现特定说话人的语音识别),那么识别性能应该就可以得到提高。
但是,针对单一说话人训练声学模型,要收集到足够的语音数据是很困难的。因此,我们可以通过说话人自适应技术,即以非特定说话人的声学模型为基底模型,再利用特定说话人少量的语数据(自适应数据)对基底模型的参数进行调整适配,来提高识别率。
说话人自适应技术中具有代表性的方法是MLLR(MaximumLikelihood Linear Regression,最大似然线性回归)方法。
MLLR方法就是估计系数矩阵 和常数项 ,并用 和 对上述基底模型的参数(具体来说就是HMM各个状态下的正太分布的均值向量 )进行线性变换,使得变换后的声学模型生成适应语音数据概率最大。

7. 串接HMM的Viterbi识别
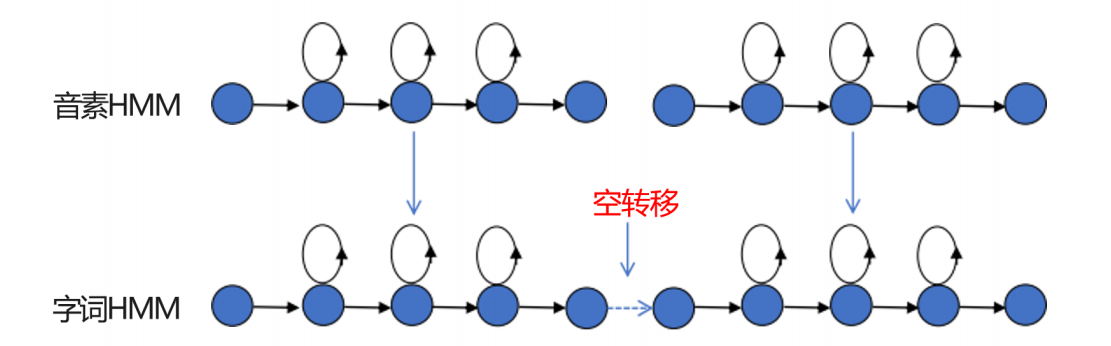
在连续语音识别中,字词的HMM都是由子词单元(音素)的HMM连接形成的。 一般在连接时,一个子词单元HMM的终止状态和相邻基元HMM的初始状态相连接,这种连接产生的转移弧就是空转,如下图所示: