深度学习-nlp-NLP之NER命名实体识别-CRF的Viterbi解码--76
参考链接:
https://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/ner/bilstm_crf.html
1. 概念
命名实体识别(NER),又称为“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、专有名词、机构名等。
命名实体识别自然语言处理中的一项基础关键性任务,是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具。
一般来说,命名实体识别的任务是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
例如:

2. BiLSTM + CRF 结构
为方便直观地看到BiLSTM+CRF是什么?
模型结构图
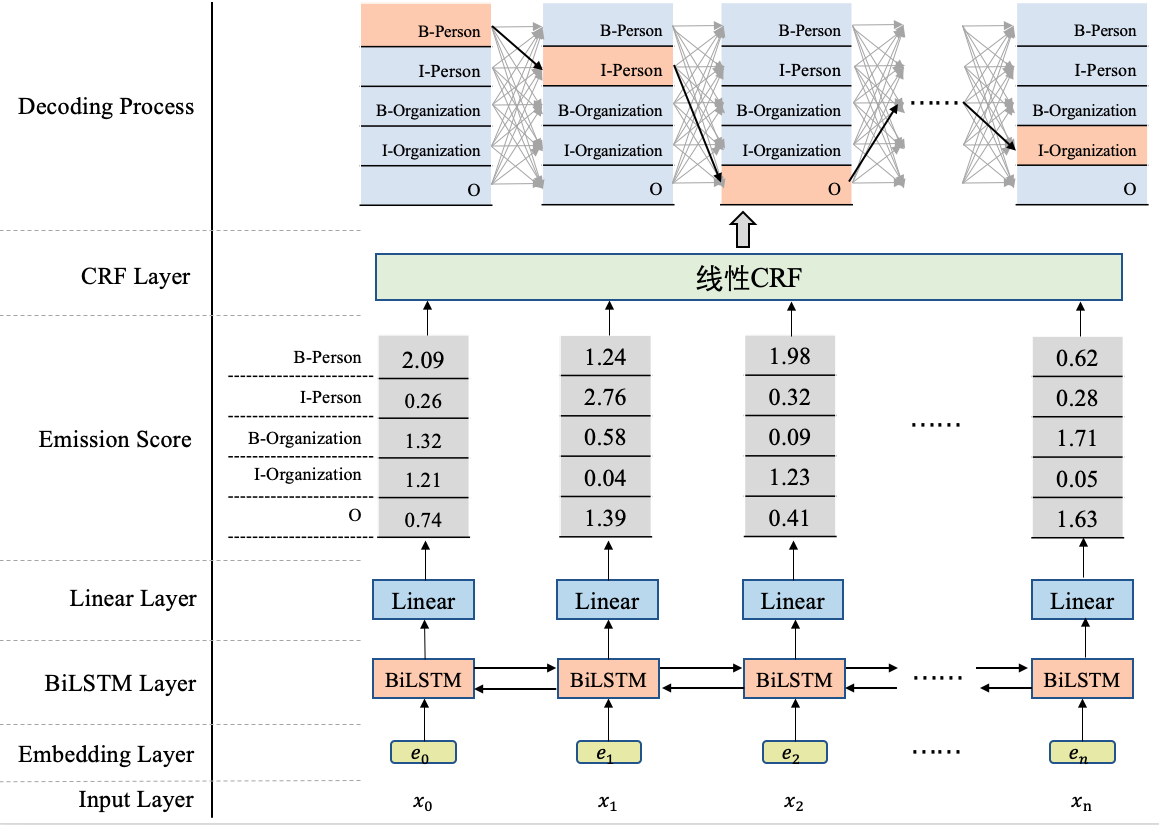
在BiLSTM上方我们添加了一个CRF层。具体地,在基于BiLSTM获得各个位置的标签向量之后,这些标签向量将被作为发射分数传入CRF中,
注意:是作为一个Emission Score整体丢进去,而不是一条一条放进去,
这些发射分数(标签向量)传入CRF之后,CRF会据此解码出一串标签序列,
从上图,最上边的解码过程可以看出,这里可能对应着很多条不同的路径,
CRF的作用就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出。
BiLSTM+CRF模型架构实现NER任务,大致分为两个阶段:
- 使用BiLSTM生成发射分数(标签向量),
- 基于发射分数使用CRF解码最优的标签路径。
CRF的概念:
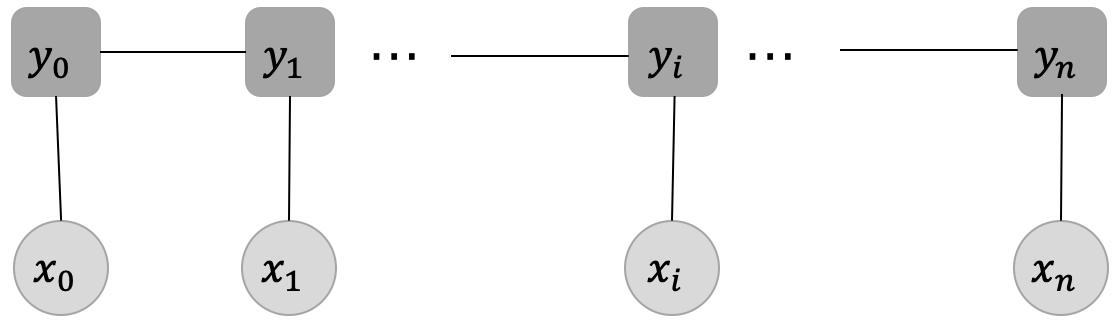
约束:
每个标签yi的产生,只与这些因素有关系:当前位置的输入xi,yi直接相连的两个邻居yi−1和yi+1,与其他的标签和输入没有关系。
保输入序列X和输出序列Y是线性序列
这样的定义,其实帮助我们减小了建模CRF的代价。
通过观察序列x1,x2, xn 来推断最有可能的隐藏序列
发射分数和转移分数
x=[x0,x1,...,xi,...,xn] 代表输入变量,对应到我们当前任务就是输入文本序列,y=[y0,y1,...,yi,...,yn]代表相应的标签序列
其中,每个输入xi均对应着一个标签yi,这一步对应的就是发射分数,它指示了当前的输入xi应该对应什么样的标签;在每个标签yi之间也存在连线,它表示当前位置的标签yi向下一个位置的标签yi+1的一种转移
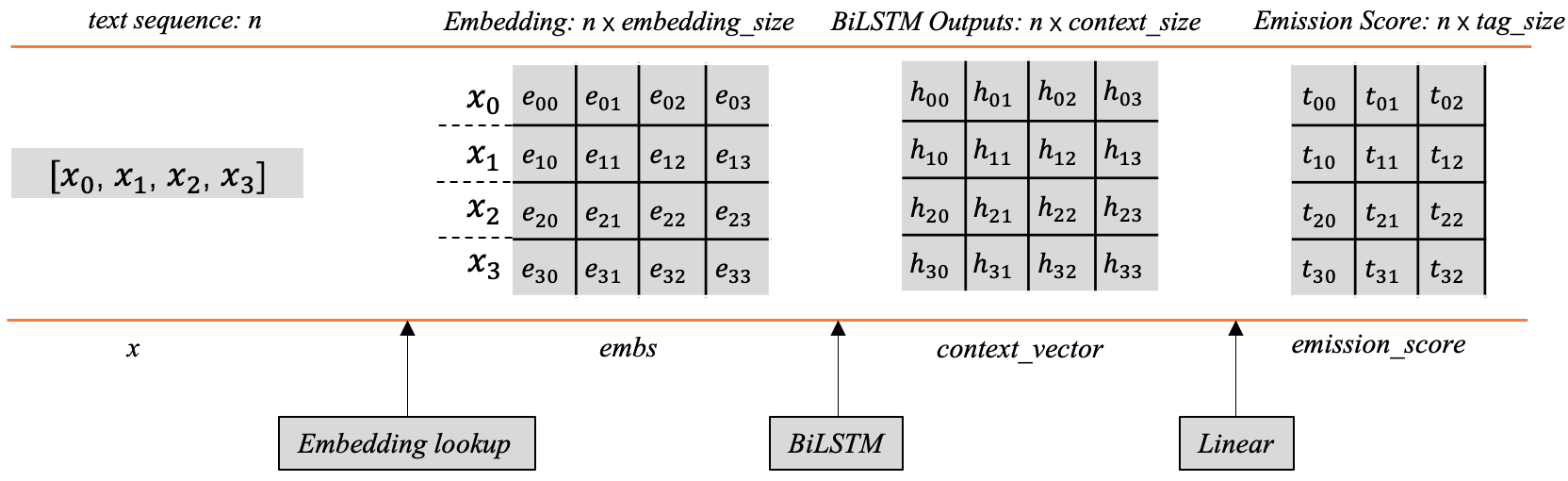
当给定的文本序列x=[x1,x2,x3,...,xn]映射为对应词向量之后,将会得到一个shape为[n,embedding_size]的词向量矩阵embs,例如x0对应的词向量是[e00,e01,e02,e03]
然后将embs传入BiLSTM后,每个词的位置都会产生一个上下文向量,所有的向量组合之后会得到一个向量矩阵context_vector,其中每行代表对应单词经过BiLSTM后的上下文向量。
这里的每个位置的上下文向量可以用来指导当前位置应该输出的标签信息,但这里有个问题,这个输出向量的维度并不是标签的数量,它不能直接用来指示应该输出什么标签。一般的做法是在后边加一层线性层,将这个上下文向量的维度映射为标签的数量,这样的话就会生成前边所讲的标签向量,其中的每个元素分别对应着相应标签的分数,根据这个分数可以用来指导最终标签的输出。
线性层这里只是做了这样的一个线性变换:y=XW+b,显然,这里的X就是context_vector, y是相应的emission_score,W和b是线性层的可学习参数。 前边提到,context_vector的shape为[n,context_size],那么线性层的W的shape应该是[context_size,tag_size],经过以上公式的线性变换,就可以得到发射分数emission_score,
转移分数
转移分数表示一个标签向另一个标签转移的分数,分数越高,转移概率就越大
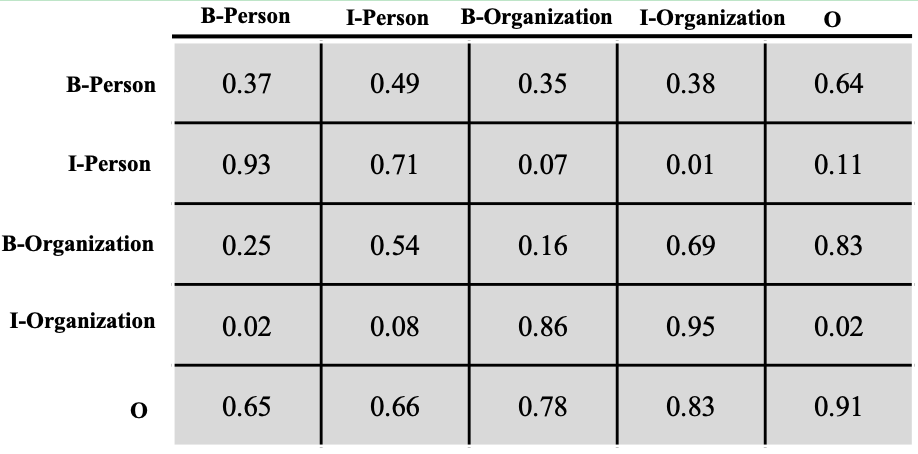
让我们从列到行地来看下这个转移矩阵T,B-Person向I-Person转移的分数为0.93,B-Person向I-Organization转移的分数为0.02,前者的分数远远大于后者。I-Person向I-Person转移的概率是0.71,I-rganization向I-Organization转移的分数是0.95,因为一个人或者组织的名字往往包含多个字,所以这个概率相对是比较高的,这其实也是很符合我们直观认识的。
3. CRF建模的损失函数
前边我们讲到,CRF能够帮助我们以一种全局的方式建模,在所有可能的路径中选择效果最优,分数最高的那条路径。
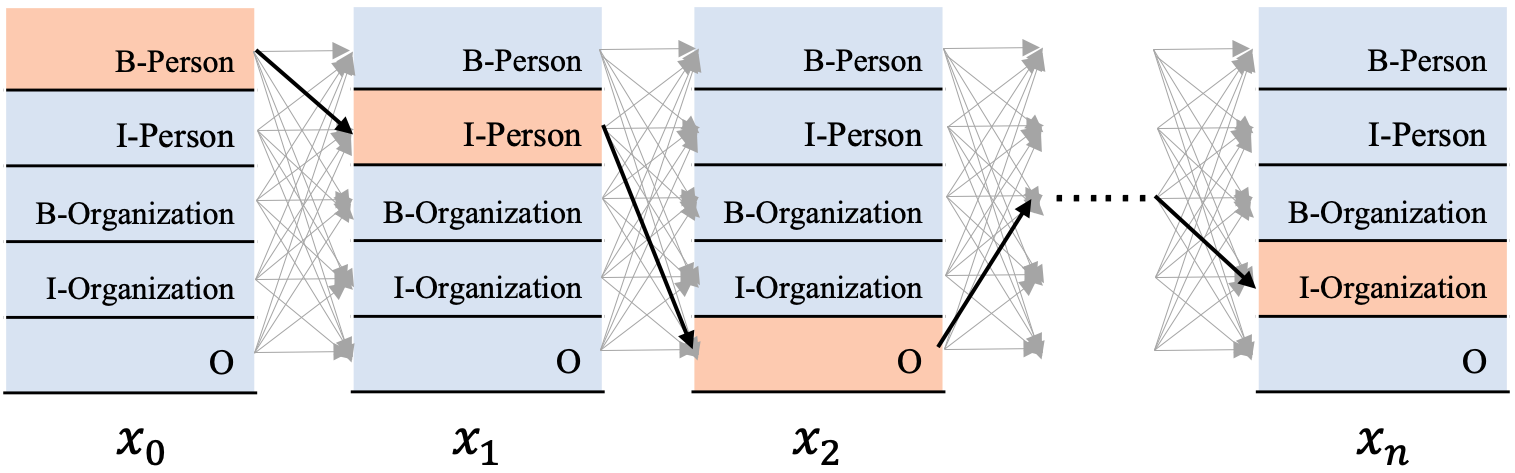
现在我们有一串输入x=[x0,x1,x2,xn],期待解码出相应的标签序列y=[y0,y1,y2,...,yn],
形式化为对应的条件概率公式如下:
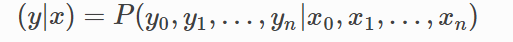
CRF的解码策略在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出,
假设标签数量是k,文本长度是n,显然会有N=kn条路径,若用Si代表第i条路径的分数,那我们可以这样去算一个标签序列出现的概率:
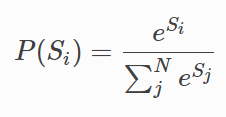
现在我们有一条真实的路径real,即我们期待CRF解码出来的序列就是这一条。那它的分数可以表示为sreal,它出现的概率就是:
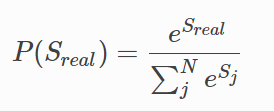
为方便求解,我们一般将这样的损失放到log空间去求解,因为log函数本身是单调递增的,所以它并不影响我们去迭代优化损失函数。
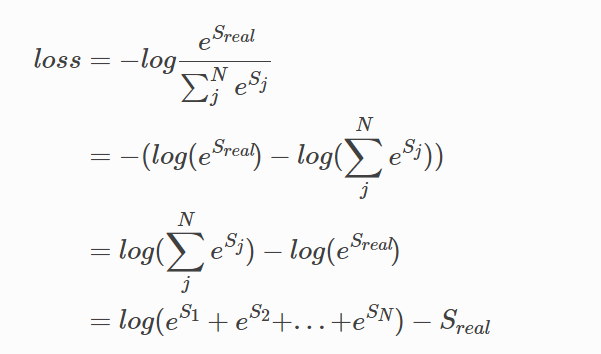
这就是我们CRF建模的损失函数了。我们整个BiLSTM+CRF建模的目的就是为了让这个函数越来越小,
从这个损失函数可以看出,这个损失函数包含两部分:单条真实路径的分数Sreal,归一化项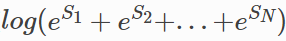
单条路径的分数计算:
发射分数和转移分数,假设:
E代表发射分数矩阵,
T代表转移分数矩阵,
n代表文本序列长度,
tag_size代表标签的数量。
E 的shape为[n,tag_size],每行对应着一个文本字词的发射分数,每列代表一个标签,
T的shape为[tag_size,tag_size],它代表了标签之间相互转移的分数,例如,T03代表id为3的标签向id为0的标签转移分数。
对于这个图:
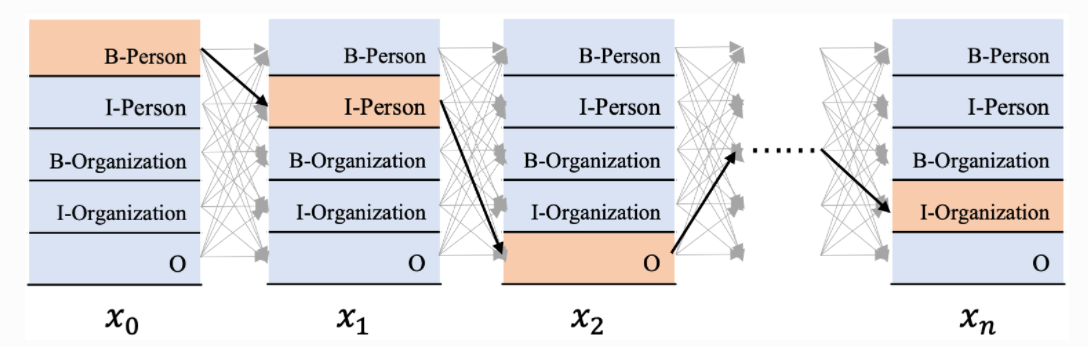
标记出来的黄色路径来说:
x0 的标签是B-Person,对应的发射分数是E00,
x1的标签是I-Person,对应的发射分数是E11,由B-Person向I-Person转移的分数是T10,
因此到这一步的分数就是:E00+T10+E11。
接下来x2的标签是O,由x1的标签向I-Person向x2的标签O转移的概率是T41,因此到这一步的分数是:E00+T10+E11+T41+E24,
依次类推,我们可以计算完整条路径的分数。
因此计算real_path的 分数是比较简单的
4. 全部路径的分数计算--前向算法的动态规划
损失函数包括两项,单条真实路径分数的计算和归一化项(如上所述,全部路径分数的log_sum_exp,为方便描述,后续直接将个归一化项描述为全部路径之和)
假设我对串包含50个字的文本串进行实体识别,标签的数量是31,那么这个路径的数量将是31**50条,这是真的是难以接受的一件事情,所以把所有的路径列出来是不可行的。
换一种高效的思路,这里其实用到了一种被称为前向算法的动态规划
简化一下:
假设我们现在在计算 只有两个tag 3个x的情况:
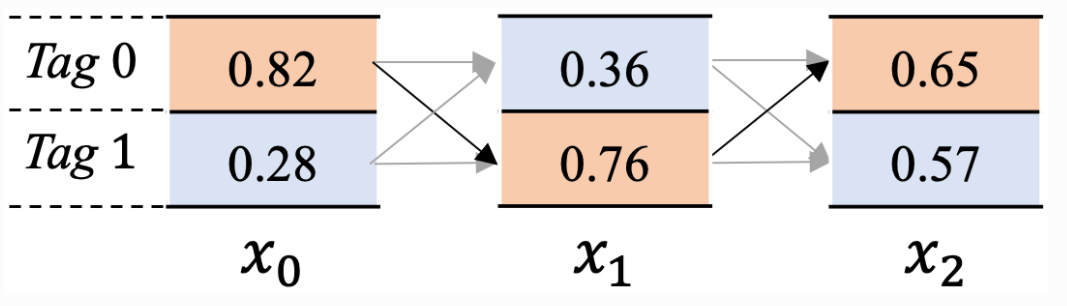
共包含2个标签Tag 0 和Tag 1, 文本串有3个单词x0,x1,x2。
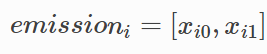 ,代表xi位置的发射分数。
,代表xi位置的发射分数。
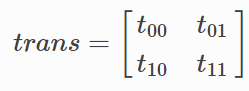 ,代表转移矩阵。
,代表转移矩阵。
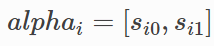 ,到当前位置xi为止,以xi位置相应标签结尾的路径分数之和,以x2步为例,alpha2=[s20,s21],其中s20代表截止到x2步骤为止,以标签Tag 0 结尾所有的路径分数之和,s21代表截止到x2步骤为止,以标签Tag 1结尾的所有路径分数之和。
,到当前位置xi为止,以xi位置相应标签结尾的路径分数之和,以x2步为例,alpha2=[s20,s21],其中s20代表截止到x2步骤为止,以标签Tag 0 结尾所有的路径分数之和,s21代表截止到x2步骤为止,以标签Tag 1结尾的所有路径分数之和。
有了xi位置的发射分数,有了转移矩阵,
到达某一步 以某个label结尾的所有路径分数之和alpha
就可以进行递推
截止到x0位置:
当前位置x0输入的发射分数为:emission0=[x00,x01]
截止到x0位置有:alpha0=[x00,x01]
截止到x1位置:
emission1=[x10,x11]
转移矩阵: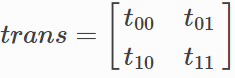
前一个位置x0各标签的路径累计和:alpha0=[x00,x01]
计算截止到x1位置,到不同标签的每条路径的分数:
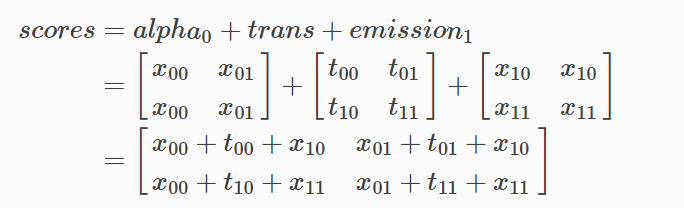
注:emission1 和 alpha0需要维度expand
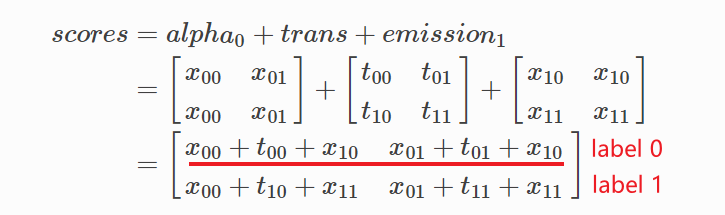
当前位置x1的各个标签的路径累计分数alpha1:
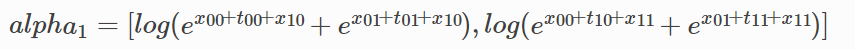
重复上面的过程 直到最后一个x输入
5. CRF的Viterbi解码
CRF的损失函数、单条路径分数的计算、全部路径分数的计算,根据这些内容完全可以进行BiLSTM+CRF的训练。但是,我们如何使用CRF从全部的路径中解码出得分最高的那条路径呢?
显然暴力计算全部路径分数后,选择得分最大的那条路径肯定是不行的。
其实这里是使用了一种被称为Viterbi的算法,上面的前向算法有些类似,
将从全部路径中查找最优路径的过程,拆解为选择每个位置累计的最大路径。
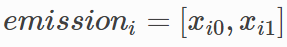 ,代表xi位置的发射分数
,代表xi位置的发射分数
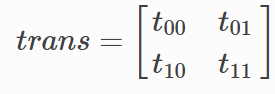 ,代表转移矩阵。
,代表转移矩阵。
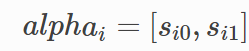 ,其中各个数值代表到当前位置xi为止,以当前位置xi相应标签结尾的路径中,取得最大分数的路径得分。
,其中各个数值代表到当前位置xi为止,以当前位置xi相应标签结尾的路径中,取得最大分数的路径得分。
依然以截止到x1位置举例:
x1 位置输入的发射分数为: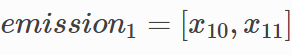
转移概率矩阵为: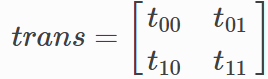
到前一个位置x0各标签的最大路径得分为 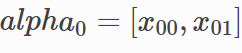
计算截止到x1位置,到不同标签的每条路径的分数:
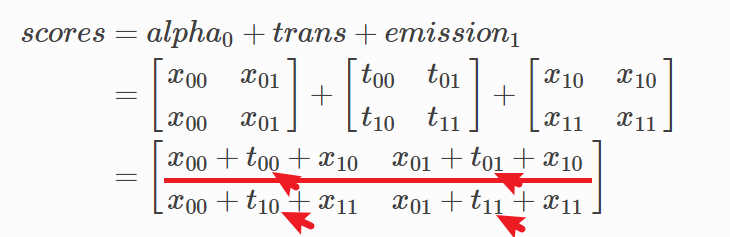
第1行代表到当前位置x1标签Tag 0结尾的所有路径的得分,那么第1行中分数最大这一条路径,就是到当前位置x1并且以Tag 0结尾的所有路径中得分最大的路径。
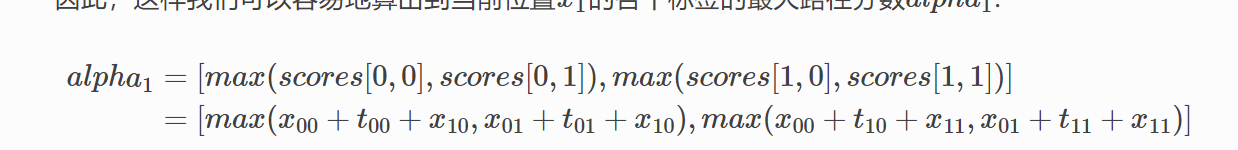
假如:

x1 位置 Tag 0的最大路径,是由上一步的tag 1位置跳过来的。
x1 位置 Tag 1的最大路径,是由上一步的tag 0位置跳过来的。
用变量beta 来记录这个跳跃的过程:
x1位置的beta1=[1,0]
这样alpha 记录到xi 某一个tag的分数有了 怎么跳过来的beta也有了
解码标签序列:
x2 位置所有标签对应的最大路径中,假设是Tag 0 对应的路径分数最大。因此x2位置对应的标签就是Tag 0。
beta2=[1,0],因此x2位置解析出的标签Tag 0,对应的上一位置x1的标签是Tag 1。
beta1=[1,0] ,因此x1位置解析出的标签Tag 1,对应的上一位置x0的标签是Tag 0
beta0=[−1,−1],当解析到这一步的时候,反回的标签肯定是-1,因此这个回溯过程也就结束了。
当回溯完成之后,将解析出的结果倒序排序,就是我们期望的最大路径。该路径就是Tag 0 –>Tag 1 –>Tag 0。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-04-28 工厂模式-设计模式-第4篇
2021-04-28 简单工厂模式-设计模式-第三篇
2021-04-28 面向对象SOLID原则-设计模式-第2篇