深度学习-nlp-NLP之sequence2sequence attention--72
参考:https://zhuanlan.zhihu.com/p/38816145
sequence2sequence模型发展到今天,根据不同任务有着不同的变体。了解了最基本的框架之后,再看别的模型就没有太大问题了。
1. sequence2sequence任务 特点
- 输入输出时不定长的。比如说想要构建一个聊天机器人,你的对话和他的回复长度都是不定的。
- 输入输出元素之间是具有顺序关系的。不同的顺序,得到的结果应该是不同的,比如“不开心”和“开心不”这两个短语的意思是不同的。
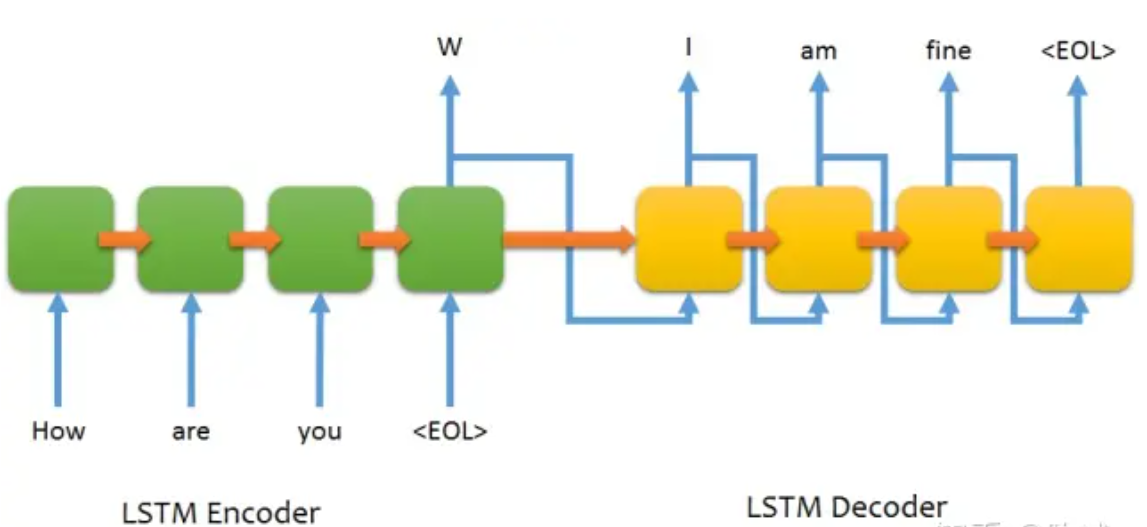
模型主要由两个部分组成,一个编码器(encoder)和一个解码器(decoder)。
编码器和解码器一般都是由RNN类网络构成,常用LSTM。
这里之所以说一般使用RNN类网络构成序列模型,这是因为使用CNN也可以构建序列到序列模型。使用CNN构造序列模型参考论文:Attention Is All You Need, Convolutional Sequence to Sequence Learning 。之所以使用CNN来做序列模型,是为了能够进行高度的并行化,不像RNN需要等待上一个节点运算后传到下一个节点才能进行输出,并且也更容易训练。
2. 编码器与解码器
通信领域,编码器(Encoder)指的是将信号进行编制,转换成容易传输的形式。
这里,主要指的是将句子编码成一个能够映射出句子大致内容的固定长度的向量。注意是固定长度的向量
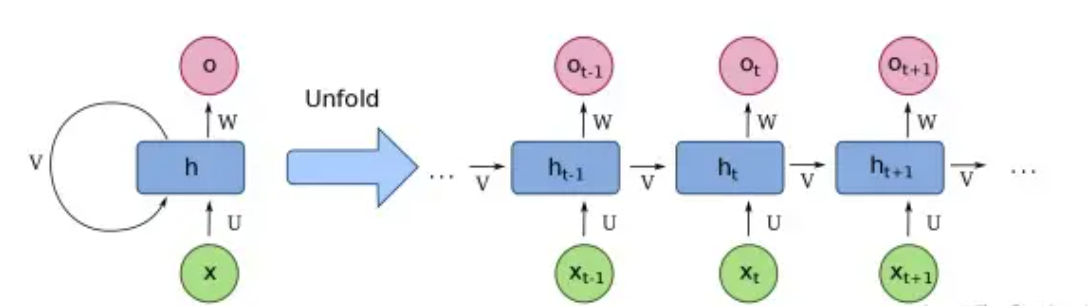
投入到的每个RNN展开的节点,我们将会得到一个输出层输出和一个隐含层输出,我们最终需要使用到的是最后一个输入节点的隐含层输出。这里面最后一个隐含节点的输出蕴含了前面所有节点的输入内容。
解码器(Decoder),这里就是将由编码器得到的固定长度的向量再还原成对应的序列数据,一般使用和编码器同样的结构,也是一个RNN类的网络。
实际操作过程会将由编码器得到的定长向量传递给解码器,解码器节点会使用这个向量作为隐藏层输入和一个开始标志位作为当前位置的输入。得到的输出向量能够映射成为我们想要的输出结果,并且会将映射输出的向量传递给下一个展开的RNN节点。
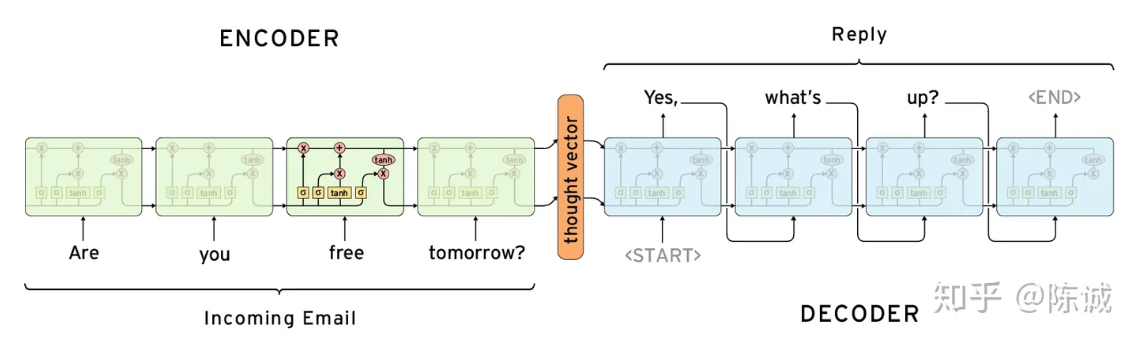
举例:
输入为 :
Are you free tomorrow ?
我们所需要的对应输出为:
Yes, what's up?
编码器将are you free tomorrow这几个单词的输入都丢到编码器LSTM中去,得到了包含输入内容的向量。
再将这个向量丢到一个解码器中去,一步步展开得到yes what's up 这几个词,遇到
总结:
序列到序列模型看似非常完美,但是实际使用的过程中仍然会遇到一些问题。比如说句子长度过长,会产生梯度消失的问题。
由于使用的是最后的一个隐含层输出的定长向量,那么对于越靠近末端的单词,“记忆”得会越深刻,而远远离的单词则会被逐渐稀释掉。,
面对这些问题,也有对应的一些解决方案比如加入attention,将句子倒向输入等。
3. Attention 注意力机制--太重要了!!
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。从注意力模型的命名方式看,很明显其借鉴了人类注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
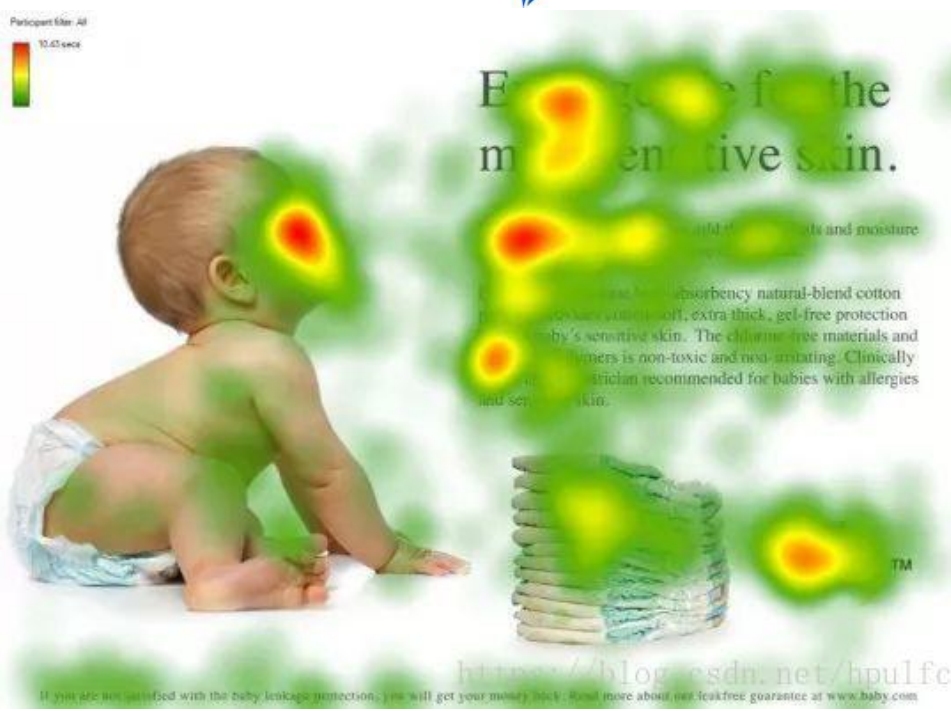
人类在看到一副图像时是如何高效分配有限的注意力资源的,人们会把注意力更多投入到人脸部,文本的标题以及文章首句等位置。
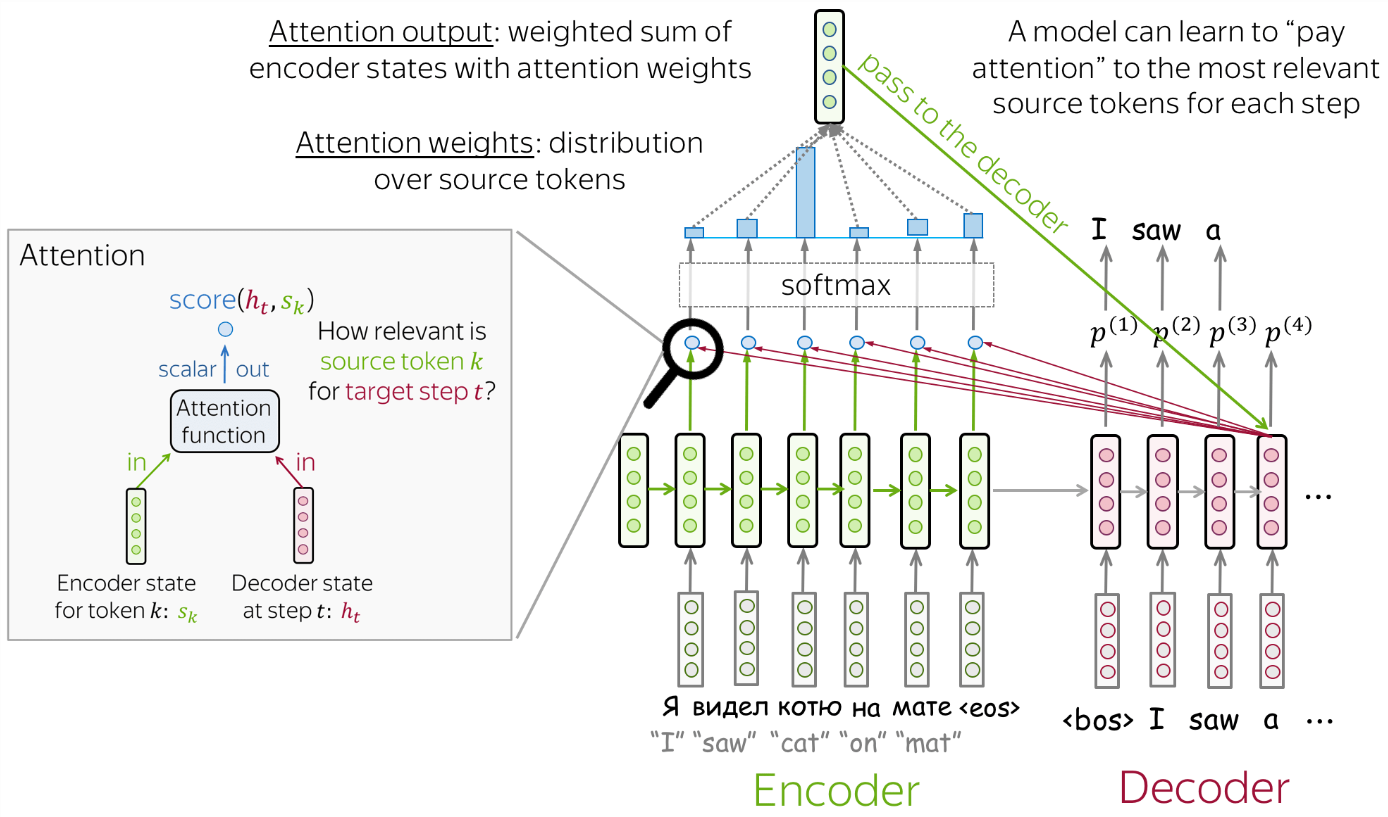
图中左半部分(绿色块)是编码器结构,右半部分(紫色块)是解码器结构,这里使用的是RNN作为编码器与解码器,也可以使用其他类型的神经网络,如LSTM等。seq2seq可以用于作为机器翻译,编码器用于读取源数列并生成它的表示,解码器则使用编码器的源表示与已生成的目标序列部分来生成整个目标序列。
这里在解码器中对于每一个时间步上的隐藏层,我们引入了一个注意力机制,
模型在翻译的时候希望让它在这个位置注意源序列对于的该词的位置。
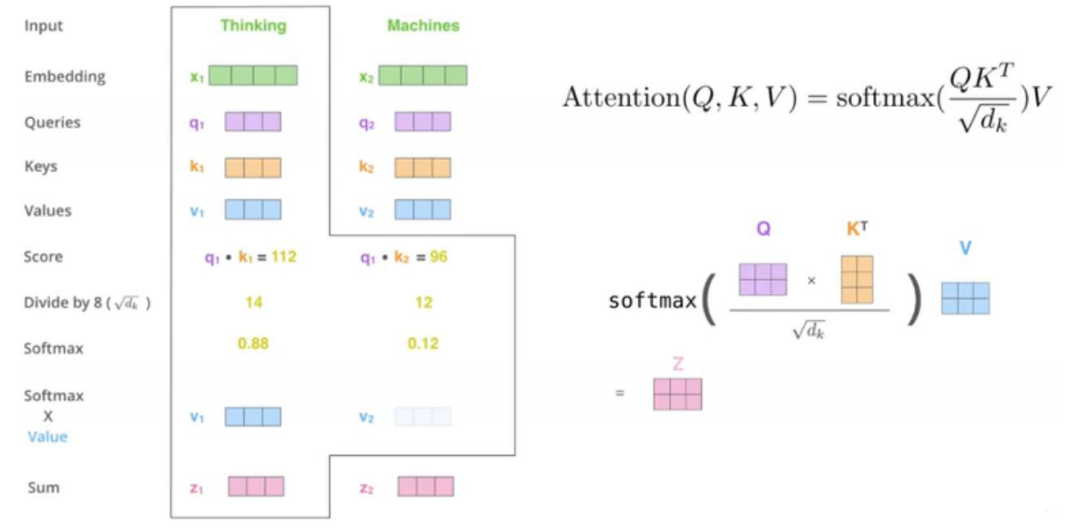
那么怎么给予它更多的关注呢?假设在 t 时间步,解码器的输入为“I”,我们要翻译“喜欢”这个词时,将“I”通过RNN编译得到隐藏层ht,与编码器的每一步输入经RNN编译后得到的隐藏层sk计算相关性,
也就是注意力得分,后将该得分通过softmax归一化作为各个sk的权重,将各个sk加权求和得到注意力的输出。

在上面的例子中,
ht被称为query,
sk被称为key,
‘各个sk加权求和’这里的sk被称为value,
要注意的是key与value不一定是一样的。
比如编码器使用的是双层RNN,那么key是第二层RNN的隐藏状态,而value可以是第一层RNN的隐藏状态,也可以是第二层RNN的隐藏状态,还可以是嵌入层。
更通俗的,query扮演的是去看其他内容,企图寻找一些信息来更好地理解自身。
key扮演的是给query一个回复,它被用来计算注意力权重。
value被用来计算注意力输出,并给那些被需要的信息更多的权重。
注意力得分的计算方式:
点积:是最简单的方法。
双线性函数(又名Luong attention)
多层感知机(又名Bahdanau attention)
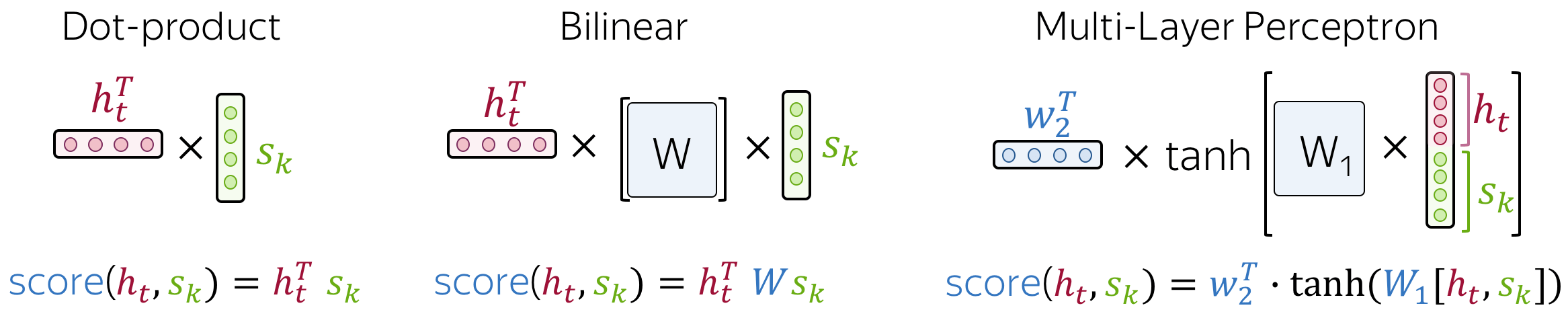
4. 自注意力机制
一个注意力函数可以被看做是从一个query和一个key-value pairs到一个output的映射,
其中query、keys、values和output都是向量。
在Transformer中用到了自注意力机制(self-attention)。
Scaled dot product Attention就是 self-attention
Multi head Attention 就是 Scaled dot product Attention 的堆积
Transformer 就是 Multi head Attention 的堆积
抽象理解attention:
Q 就是 decoder 中 St-1 这个时刻的输出
K 就是 encoder 中多个隐变量 ht
V 就是 K
attention 中不就是计算的 Q 和 K 之间的相似度=QK,然后除以一个常量 根号dk,然后做一个
softmax,不就是我们之前的α,然后乘上 V 不就是得到 context vector Ct
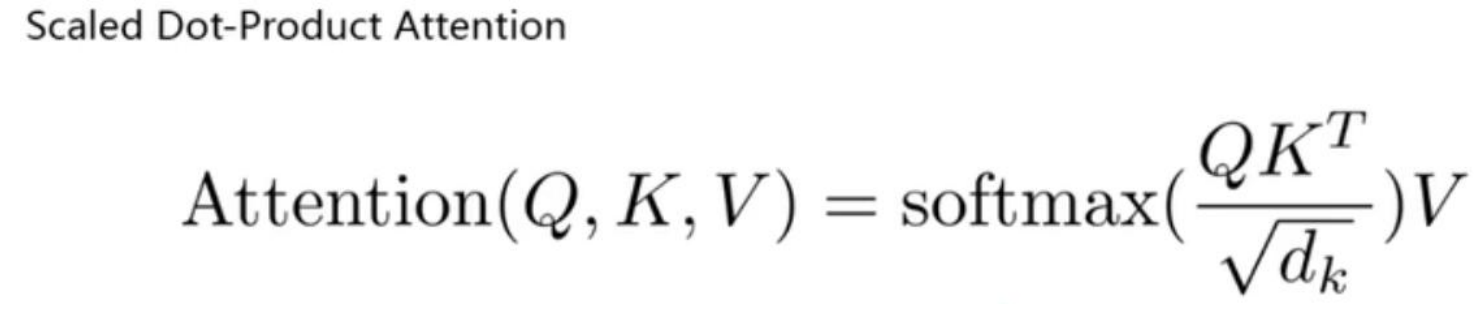
Scaled dot product Attention 之所以叫这个名字Scaled 是缩放 因为除了一个根号dk dot product是点积,在数学中,又称数量积(dot product; scalar product)
两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为:a·b=a1b1+a2b2+……+anbn
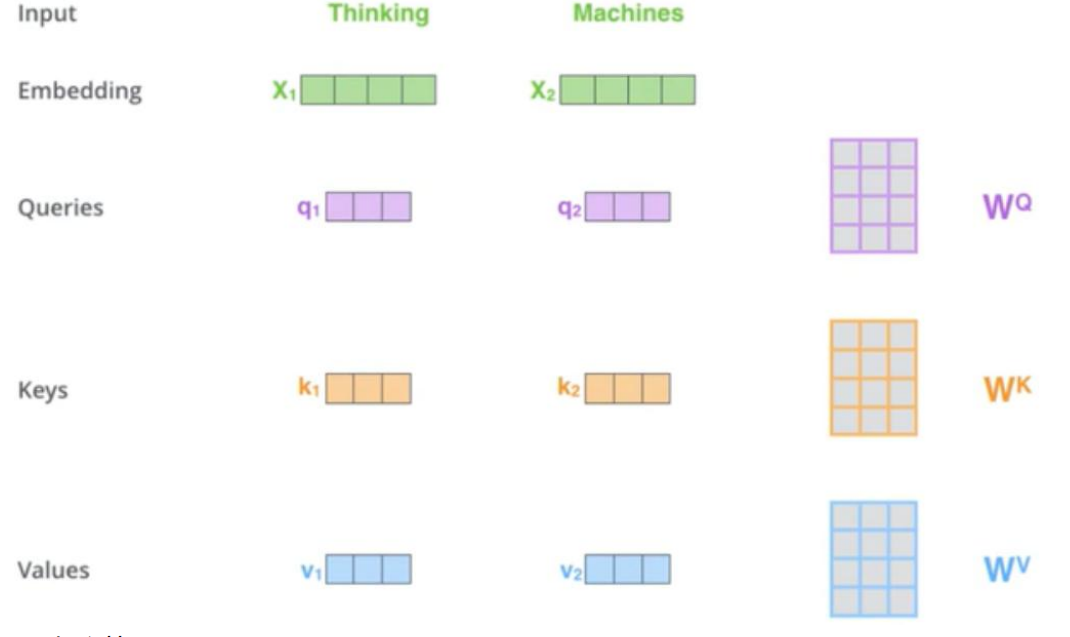
Multi head
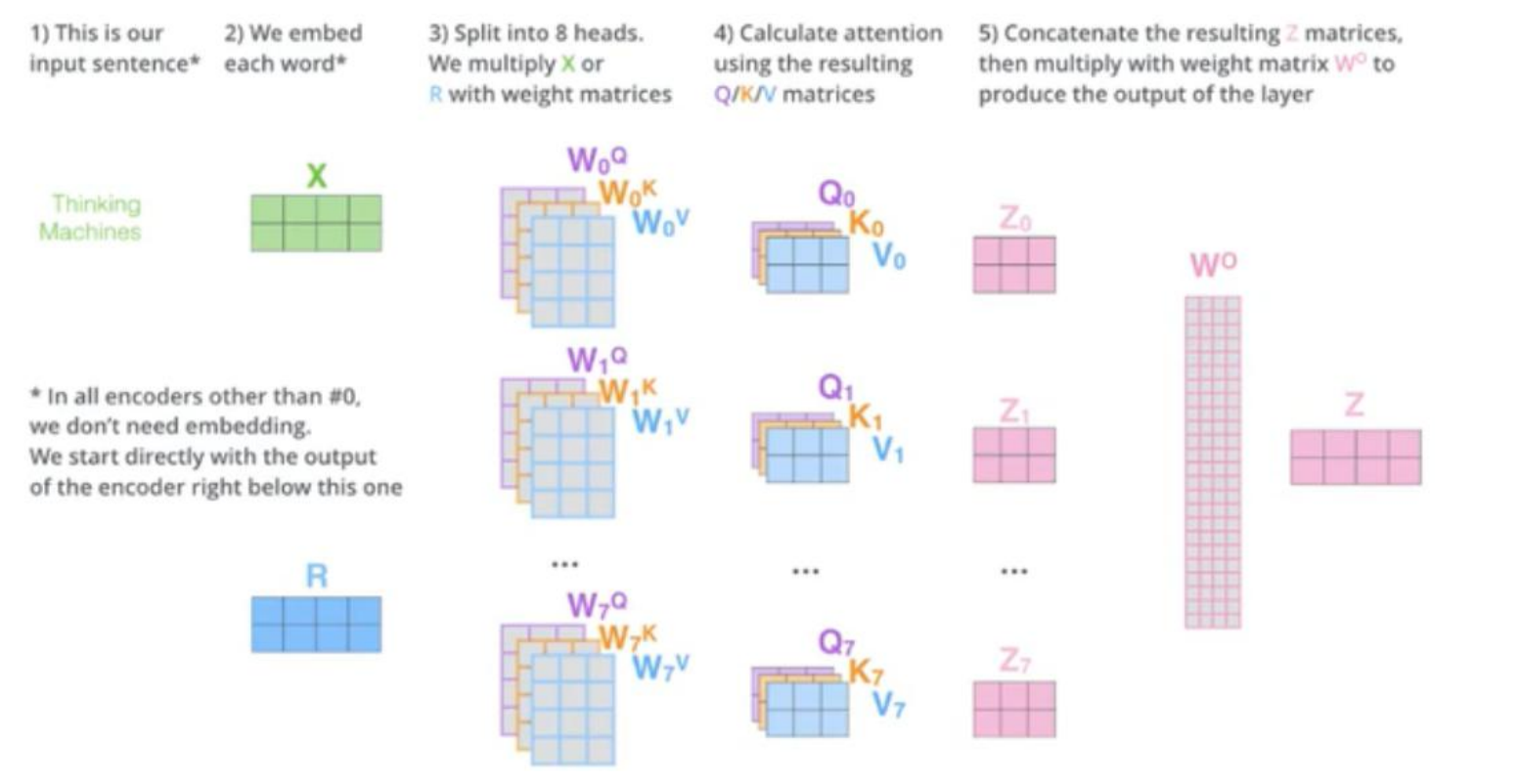
多个头的好处就是可以每个时刻同时关注多个地方,比如 8 个 head
batch normalization 是在不同样本间去计算的,layer normalization 是在同一个样本上计算的。
如果要用 add 相加必须保证 X 和 Z 维度是一样的,这就得让 self-attention 层处理后的 Z维度和 X 一样。

位置信息
BoW 是词袋模型,不考虑词语在句子中的先后顺序。有些任务对词序不敏感,有些任务词
序对结果影响很大。
Transformer 模 型 用 到 Position Embedding 。Transformer 摒弃了之前机器翻译任务中常用的 RNN 结构,使得并行性更好。RNN 的这种结构天生考虑了词语的先后顺序关系。当 Transformer 模型不用 RNN 结构时,它就要想办法通过其它机制把位置信息传输到 Encoding 的部分。所以在该模型中中,每个时刻的输入是 Word Embedding+Position Embedding。注意是Word Embedding+Position Embedding
Position Embedding 有多种方法
《Attention is All You Need》使用正弦函数和余弦函数来构造每个位置的值

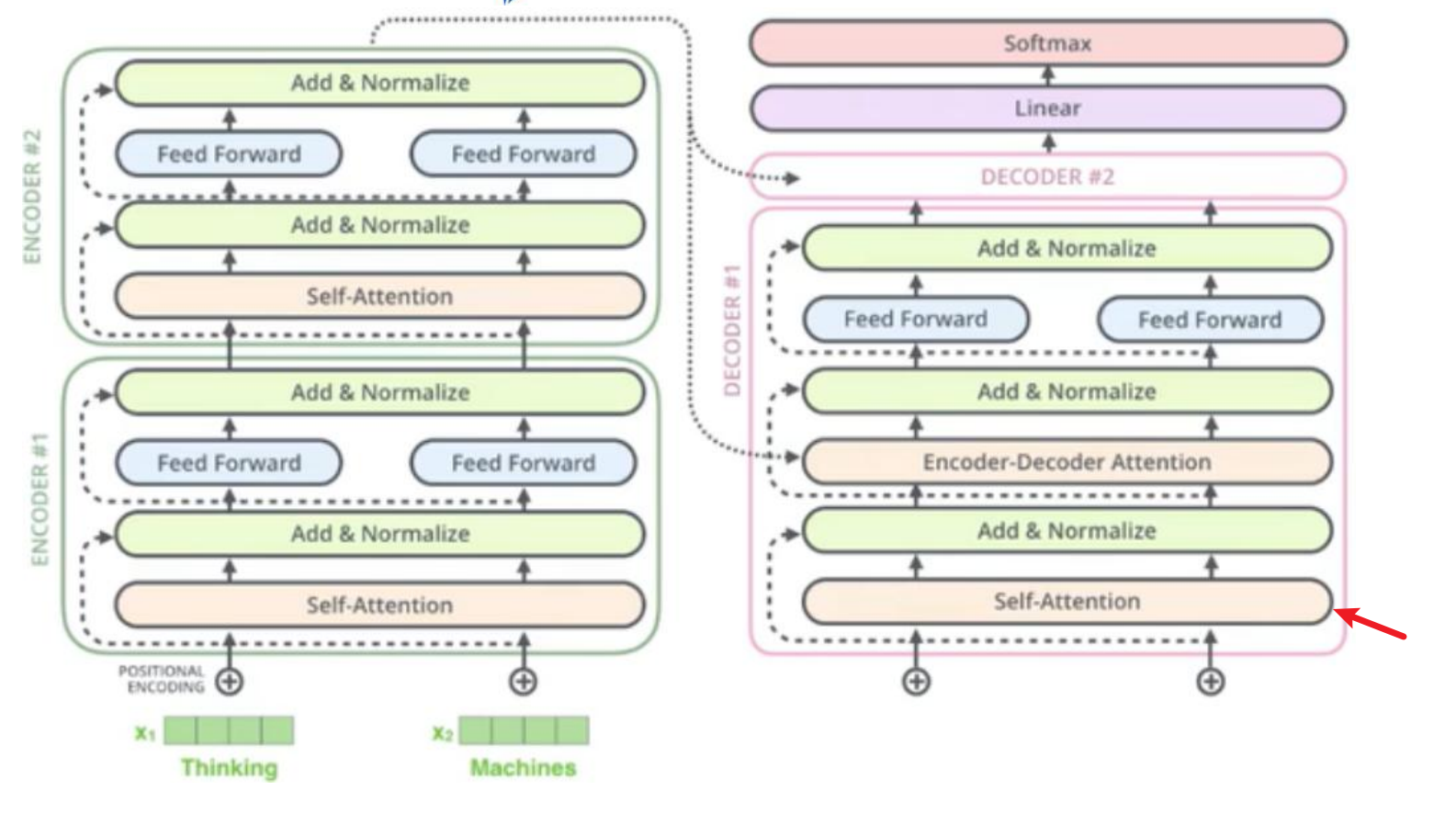
decoder 中的第一个 self-attention 是单向的,
从下往上的第一个 self-attention 是对之前的进行计算,比如现在是要预测yt,那么肯定已经知道 y0,y1,y2 一直到 yt-1yt 对 y0,y1,y2 一直到 yt-1这个已经预测好的来进行 self-attention 计算
encoder-decoder attention 中 是 把 刚 讲 过 的 yt 对 y0 , y1 , y2 一 直 到 yt-1 做self-attention 的当作 Q,之前的 encoder 的多个时刻的输出当作 K 和 V
Masked self-attention
在预测 yt 时候,还不知道后面的时刻,所以需要屏蔽调,在 softmax 的时候把权值设置为非常小的值就行了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律