深度学习-卷积神经网络--facenet人脸识别--67
1. 概述
FaceNet是谷歌于[CVPR2015.02](FaceNet: A Unified Embedding for Face Recognition and Clustering)发表,提出了一个对识别(这是谁?)、验证(这是用一个人吗?)、聚类(在这些面孔中找到同一个人)等问题的统一解决框架,
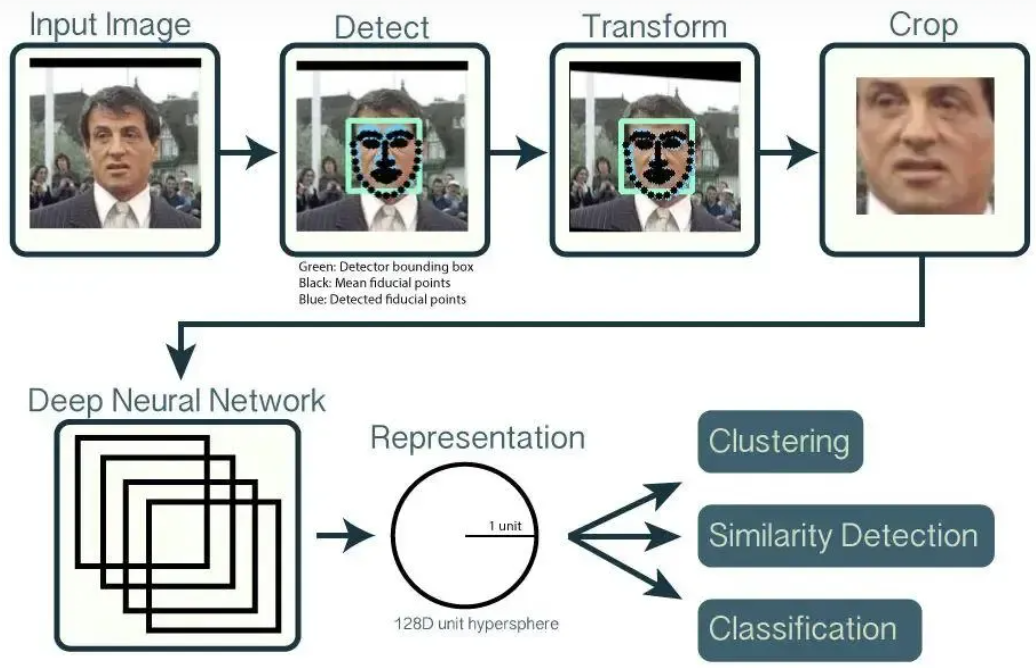
即它们都可以放到特征空间里统一处理,只需要专注于解决的仅仅是如何将人脸更好的映射到特征空间。其本质是通过卷积神经网络学习人脸图像到128维欧几里得空间的映射,该映射将人脸图像映射为128维的特征向量,联想到二维空间的相关系数的定义,使用特征向量之间的距离的倒数来表征人脸图像之间的"相关系数"(为了方便理解,后文称之为相似度),对于相同个体的不同图片,其特征向量之间的距离较小(即相似度较大),对于不同个体的图像,其特征向量之间的距离较大(即相似度较小)。最后基于特征向量之间的相似度来解决人脸图像的识别、验证和聚类等问题,FaceNet算法的流程如下图所示:
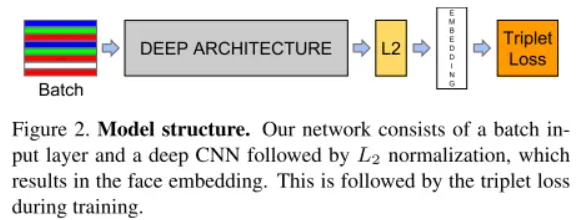
- 将图像通过深度卷积神经网络映射到128维的特征空间(欧几里得空间)中,得到对应的128维特征向量;
- 对特征向量进行L2正则化,筛选出有效特征;
- 使用正则化后的特征向量,计算Triplets Loss;
2.Triplets Loss
在上文中提到过,FaceNet 模型需要基于三元组数据(2 张张三、1 张李四)进行训练。因此可以将每一个三元组内的数据定义为:
张三的第一张人脸图像为:锚样本(Anchor),标记为 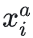
张三的第二张人脸图像为:正样本(Positive),标记为 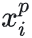
李四的人脸图像为:负样本(Negative),标记为 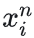
骨干网络所进行的图像向量化用 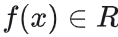 表示,
表示,
L2 范数归一化用 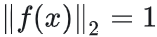 表示,
表示,
Anchor-Positive 组与 Anchor-Negative 组之间的夹角用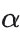
表示。
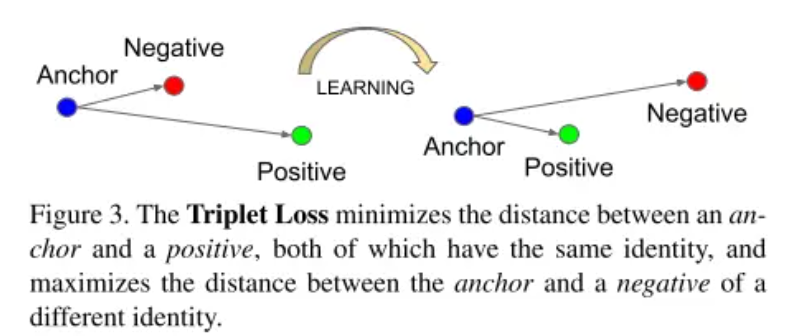
FaceNet 模型优化的目标是“让张三本人最不相像的两张人脸图像的特征向量之间的欧式距离,小于张三与世界上跟他最相像的李四的人脸图像的特征向量之间的欧氏距离”。
模型需要确保某人的一张图像 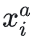 与此人的所有其他图像之间的距离
与此人的所有其他图像之间的距离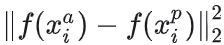 ,比
,比 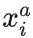 与任意其他人的任何图像
与任意其他人的任何图像 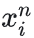 的距离
的距离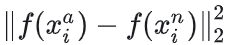 要小。
要小。
模型的目标:
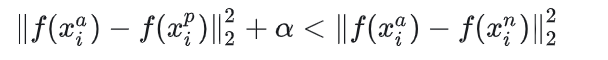
所有不符合上述不等式的样本(也就是满足: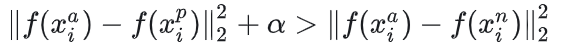
)的样本,都将用来优化模型。
三元损失函数:
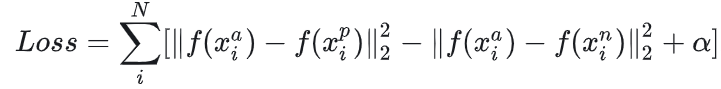
3. 三元组样本选择
为了保证模型的快速收敛,选择三元组样本的方法是至关重要的,为了实现找到“张三的两张最不相像的人脸图像”和“世界上与张三最相像的李四的图像”。
那么对于给定的锚样本 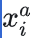
,需要选择一个满足条件:
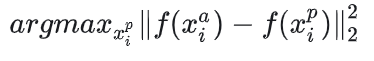
(最不像但还是正样本)的正样本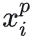
,
还需要选择一个满足条件:
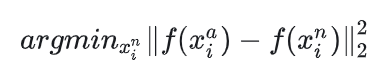
(最像但还是负样本)的负样本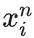
。
从整个训练集中选取 Argmax 和 Argmin 是不现实的,因为整个训练集中的 Argmax 和 Argmin 经常是由标签(Label)标记错误或图像成像效果不佳导致的,选择这样的数据既从工程的角度不好实现,又不符合模型优化原理。
两种方式来解决三元组选取的问题:
离线生成:训练过程中每隔 n 步(Step),计算这 n 步对应的数据子集上的 Argmax 和 Argmin。
在线生成:训练过程中直接从每个批(Batch)中选择所有符合条件的正/负样本。
在构建批(Batch)时,需要保证某人有一定数量的照片后(40张以上),才能构建正样本对,而负样本对使用其他人像随机添加即可。
训练过程中,可以使用每个批(Batch)中的所有正样本对,以及满足 的半难负样本对。
的半难负样本对。
这是因为如果直接选择最难负样本,可能会使得模型在训练初期直接收敛到一个较差的局部最优解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号