深度学习-卷积神经网络--MT CNN-人脸检测-64
Paper地址:
https://kpzhang93.github.io/MTCNN_face_detection_alignment/
github链接:
https://github.com/kpzhang93/MTCNN_face_detection_alignment
1. MT CNN-的原理
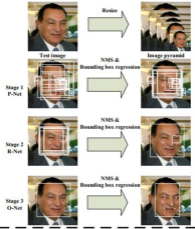
- 图像金字塔
对图片进行Resize操作,将原始图像缩放成不同的尺度,生成图像金字塔。
然后将不同尺度的图像送入到这三个子网络中进行训练,目的是为了可以检测到不同大小的人脸,从而实现多尺度目标检测。
读源码会发现,使用的是每次使面积为原有的1/2 不断的缩小hw 直到不满足12像素为止
-
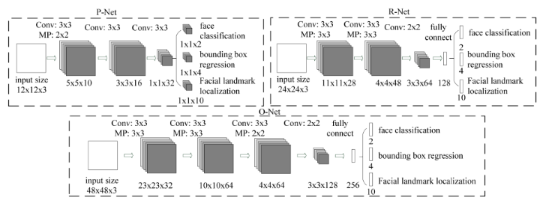
P-Net(Proposal Network)
P-Net是一个人脸区域的候选网络,该网络的输入一个12x12x3的图像,通过3层的卷积之后,判断这个12x12的图像中是否存在人脸,并且给出人脸框的回归和人脸关键点。
网络的第一部分输出是用来判断该图像是否存在人脸,输出向量大小1x1x2,也就是两个值。
网络的第二部分给出框的精确位置,一般称为框回归。P-Net输入的12×12的图像块可能并不是完美的人脸框的位置,如有的时候人脸并不正好为方形,有可能12×12的图像偏左或偏右,因此需要输出当前框位置相对完美的人脸框位置的偏移。这个偏移大小为1×1×4,即表示框左上角的横坐标的相对偏移,框左上角的纵坐标的相对偏移、框的宽度的误差、框的高度的误差。
网络的第三部分给出人脸的5个关键点的位置。5个关键点分别对应着左眼的位置、右眼的位置、鼻子的位置、左嘴巴的位置、右嘴巴的位置。每个关键点需要两维来表示,因此输出是向量大小为1×1×10。
注意:P-Net是全卷积网络对于输入图片size要求不限定 -
R-Net(Refine Network)
从网络图可以看到,只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive(预测有人脸 但实际并不是人脸)的作用。在输入R-Net之前,都需要缩放到24x24x3,网络的输出与P-Net是相同的,R-Net的目的是为了去除大量的非人脸框。 -
O-Net(Output Network)
这个阶段类似于第二阶段,但是在这个阶段在此阶段,我们目的通过更多的监督来识别面部区域。特别是,网络将输出五个面部关键点的位置。
从网络图可以看到,该层比R-Net层有多了一层卷积层,所以处理的结果会更加精细。输入的图像大小48x48x3,输出包括N个边界框的坐标信息,score以及关键点位置。
从P-Net到R-Net,再到最后的O-Net,网络输入的图像越来越大,卷积层的通道数越来越多,网络的深度(层数)也越来越深,因此识别人脸的准确率应该也是越来越高的。
2. 损失函数
对于是否是人脸,直接使用交叉熵损失函数,
对于框回归和关键点定位,使用L2损失。
最后把这三部分的损失各自乘以自身的权重累加起来,形成最后的总损失。
人脸识别损失函数(cross-entry loss)
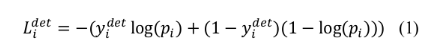
回归框的损失函数 (Euclidean loss)
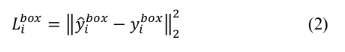
关键点的损失函数 (Euclidean loss)
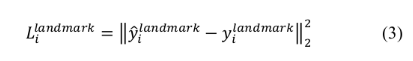
总损失:
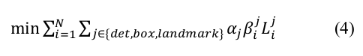
最后的总损失前添加了一个权重 α ,即损失函数所对应的权重是不一致的

也就是说在O-net 对于landmark的检测更看重
4. 升华
MT CNN 是用来检测图片中哪里有人脸 以及人脸的5个关键点位置进行输出 (人脸是谁不是不属于MT CNN的任务)
思考下 是否可以用这个 来检测 图片中 哪里有人 人体的key-point也进行标注?
改下项目是否能用于 手掌的检测 从而实现 隔空的操作 有戏里面的角色 等等!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号