深度学习-卷积神经网络-目标检测YOLO-v4-解读-56
YOLO-v4 那么多的首字母大写 略缩名字 五花八门 下面就一一解读
bag of freebies训练阶段
1. soft NMS
首先是NMS Non-Maximum Suppression 非极大值抑制
以目标检测为例:目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
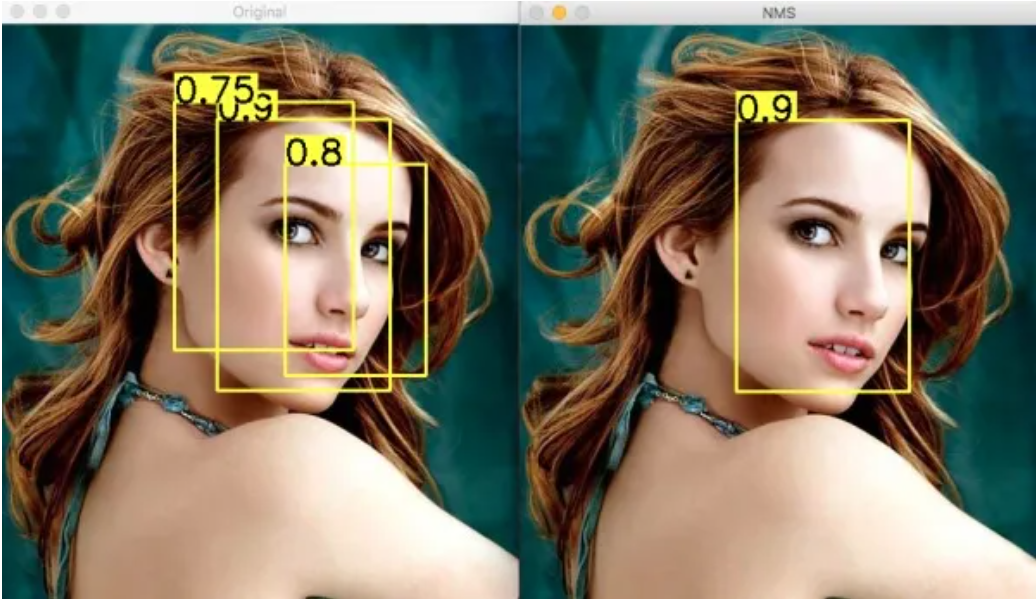
但是这当两个目标靠的比较近的时候 例如两匹马并列 这时候就有可能将第二个一个目标给丢弃了
soft NMS 就是为了解决这个问题而引入

drop block
2. GIOU DIOU CIOU
GIOU (Generalized Intersection over Union)
IOU 作为损失函数会出现的问题(缺点)
如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时
因为 loss=0,没有梯度回传,无法进行学习训练。
IoU 无法精确的反映两者的重合度大小
如下图所示,三种情况 IoU 都相等,但看得
出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
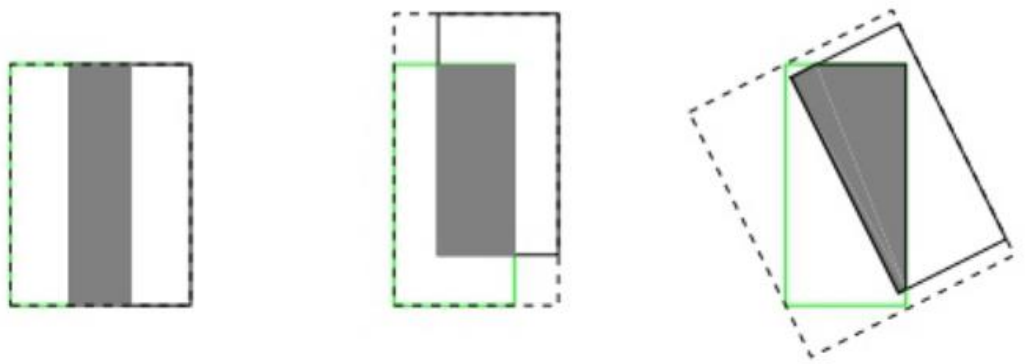
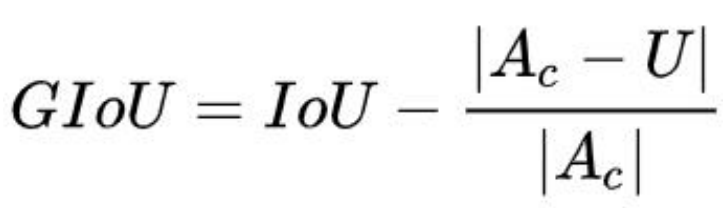
:先计算两个框的最小闭包区域面积 [公式] (通俗理解:同时包含了
预测框和真实框的最小框的面积),再计算出 IoU,再计算闭包区域中不属于两个框的区域
占闭包区域的比重,最后用 IoU 减去这个比重得到 GIoU
与 IoU 只关注重叠区域不同,GIoU 不仅关注重叠区域,还关注其他的非重合区域,能
更好的反映两者的重合度。
3. DIoU
(Distance-IoU)
DIoU 要比 GIou 更加符合目标框回归的机制,将目标与 anchor 之间的距离,重叠率
以及尺度都考虑进去,使得目标框回归变得更加稳定
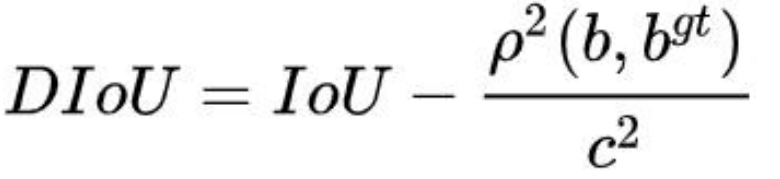
其中,b ,bgt 分别代表了预测框和真实框的中心点,且 ρ代表的是计算两个中心点间
的欧式距离。c 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。

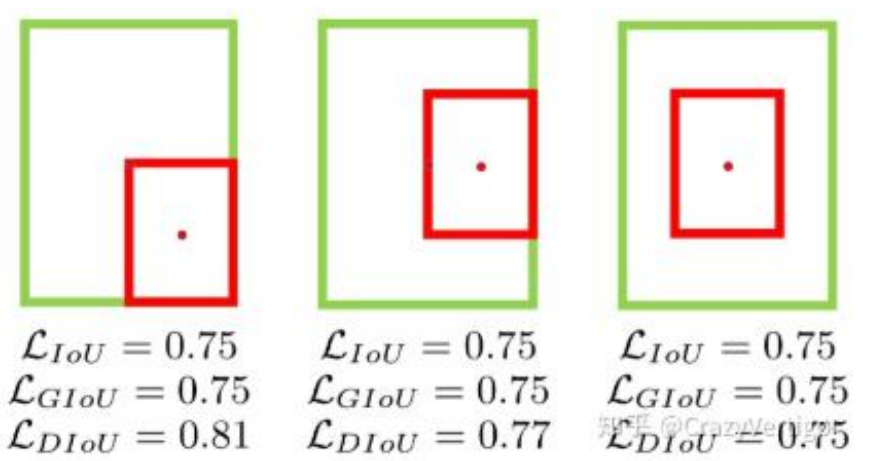
- 与 GIoU loss 类似,DIoU loss( [公式] )在与目标框不重叠时,仍然可以为边界框
提供移动方向。 - DIoU loss 可以直接最小化两个目标框的距离,因此比 GIoU loss 收敛快得多。
- 对于包含两个框在水平方向和垂直方向上这种情况,DIoU 损失可以使回归非常快,而
GIoU 损失几乎退化为 IoU 损失。 - DIoU 还可以替换普通的 IoU 评价策略,应用于 NMS 中,使得 NMS 得到的结果更加
合理和有效。
4. CIoU
(Complete-IoU)
论文考虑到 bbox 回归三要素中的长宽比还没被考虑到计算中,因此,进一步在 DIoU
的基础上提出了 CIoU。其惩罚项如下面公式:
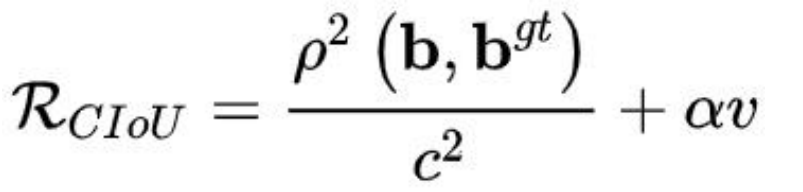
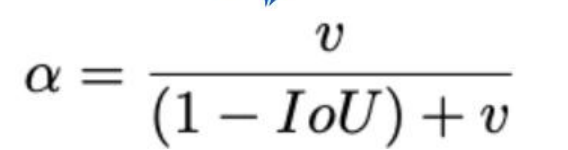
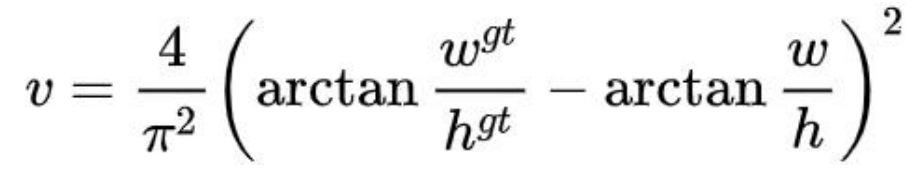
α 是权重函数
v 用来度量长宽比的相似性
完整的 CIoU 损失函数定义:
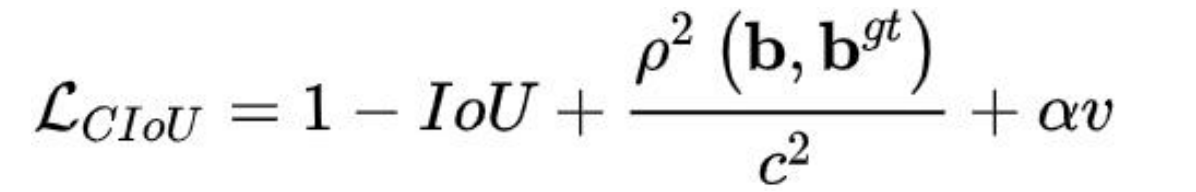
总结一下
IOU
-->
GIOU 引入能将两个框闭包
-->
DIOU 考虑中心点距离
-->
CIOU 考虑长宽比的相似性
yolov4 中
soft nms 在计算IOU的时候用的是 D IOU ---推理的时候去重
训练的时候 Loss 使用C IOU 让网络学的更准 bbox与gt尽可能的对齐
5. Focal loss
Focal loss 主要是为了解决 one-stage 目标检测中正负样本比例严重失衡的问题。该
损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘
Focal loss 是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
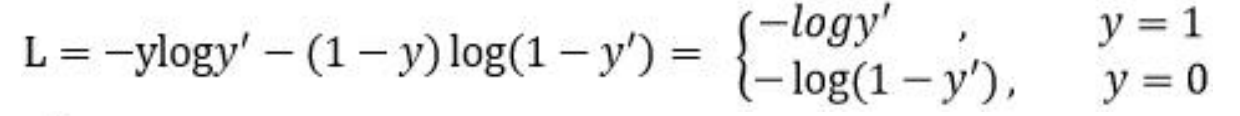
 是经过激活函数的输出,所以在 0-1 之间。可见普通的交叉熵对于正样本而言,输
是经过激活函数的输出,所以在 0-1 之间。可见普通的交叉熵对于正样本而言,输
出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量
简单样本的迭代过程中比较缓慢且可能无法优化至最优
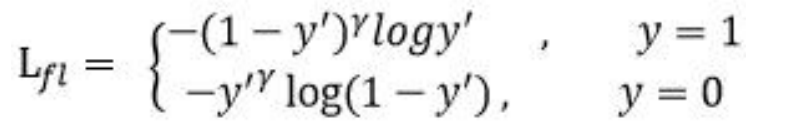
首先在原有的基础上加了一个因子,其中 gamma>0 使得减少易分类样本的损失。使
得更关注于困难的、错分的样本
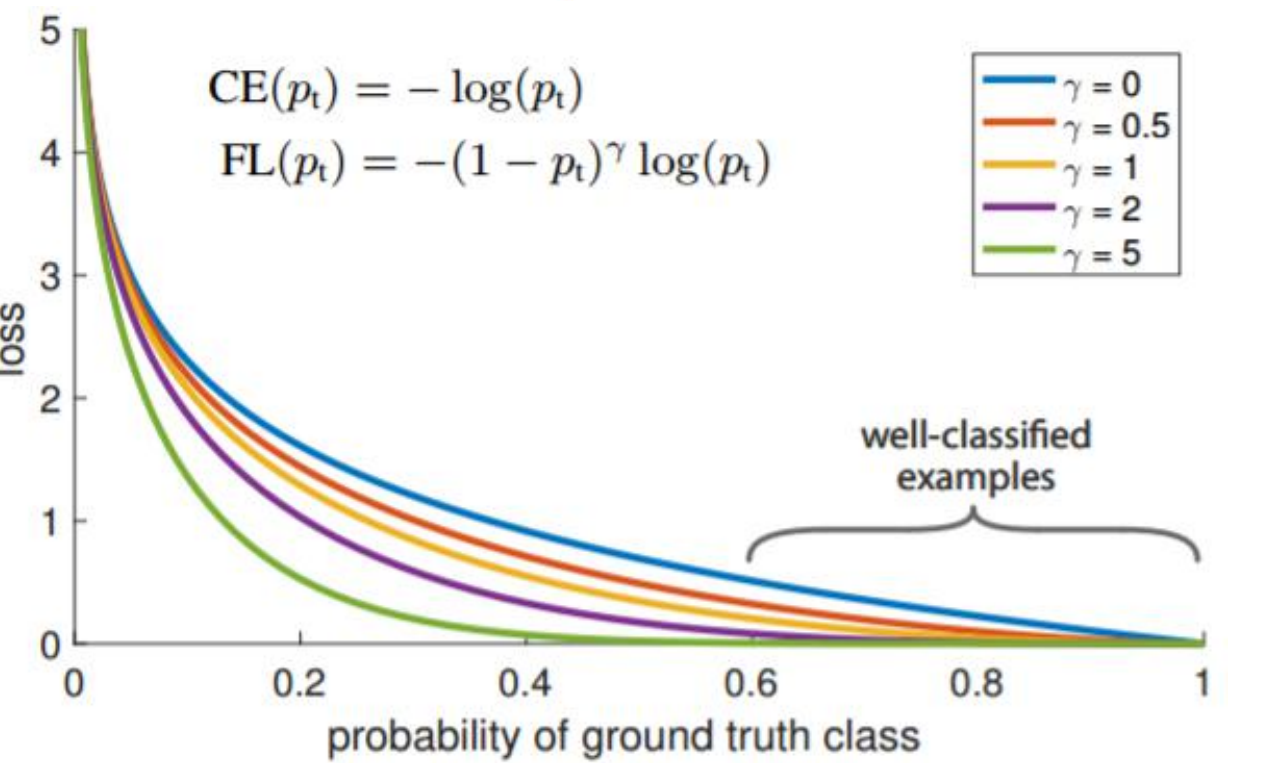
此外,加入平衡因子 alpha,用来平衡正负样本本身的比例不均:
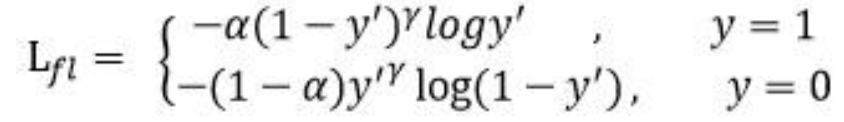
当 gamma 为 0 时即为交叉熵损失函数,当
gamma 增加时,调整因子的影响也在增加。实验发现 gamma 为 2 是最优
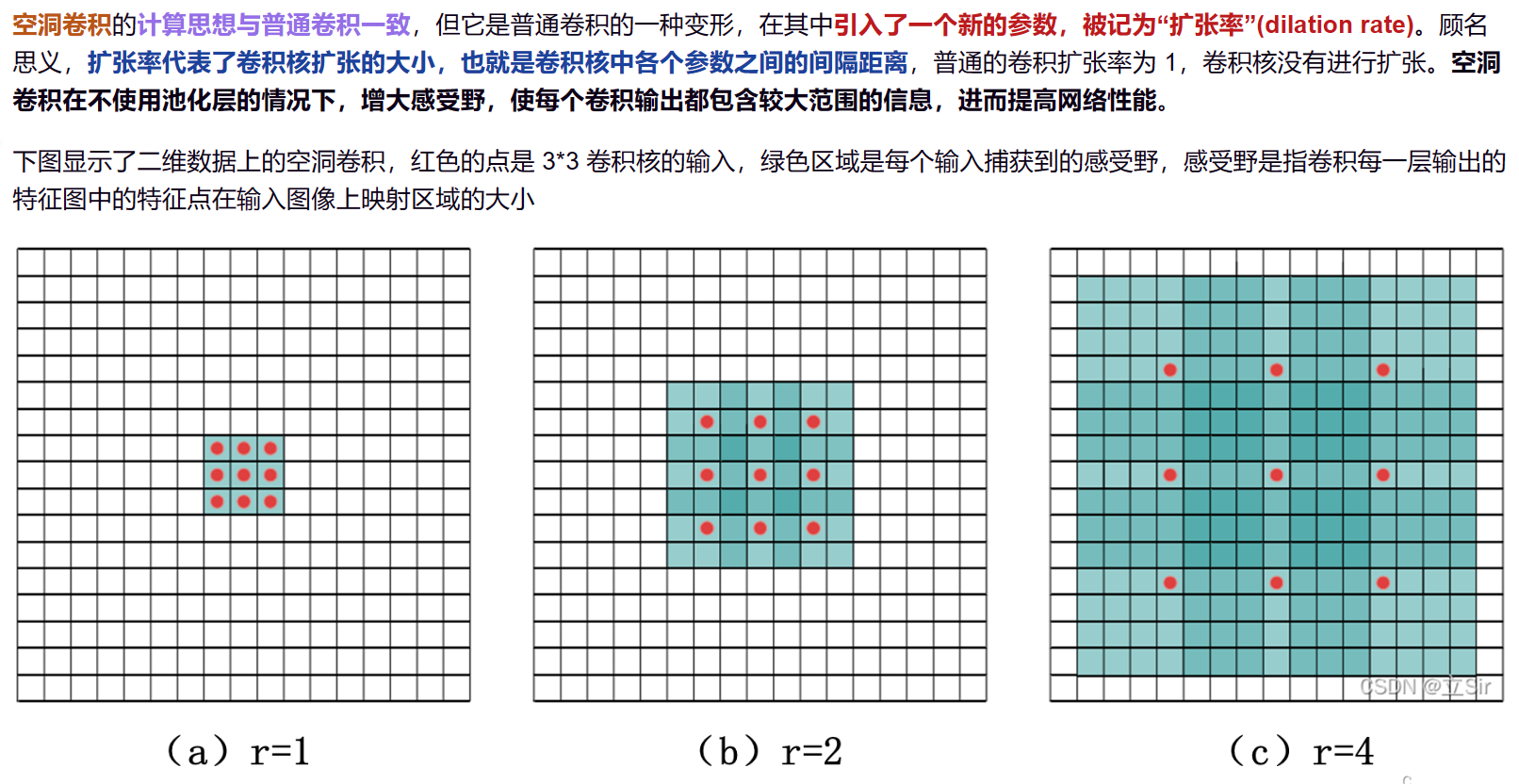
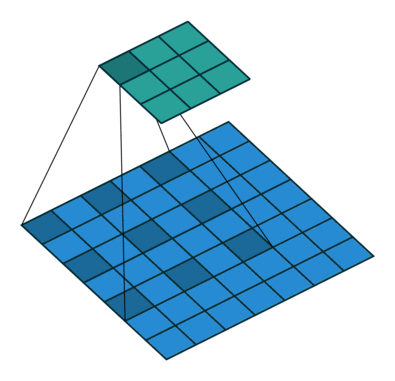
6. ASPP空洞池化
空洞空间金字塔池化
Atros spatial pyramind pooling

bag of specials推理预测阶段
7. PAN
路径聚合网络(PAN) path aggreagation network
原来多数的 object detection 算法都是只采用顶层特征做预测,
但我们知道低层的特征语义信息比较少,但是目标位置准确;
高层的特征语义信息比较丰富,但是目标位置比较粗略。
另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而不一样的地方在于预测是在不同特征层独立进
行的。
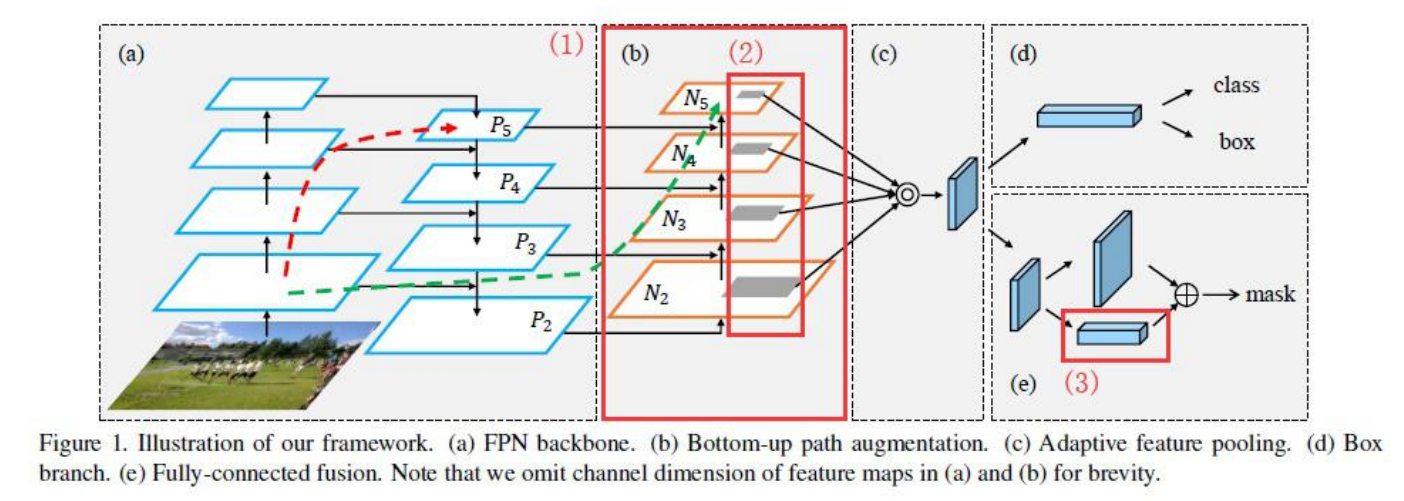
FPN 中,信息是从自下而上和自上而下流中的相邻层组合的。层之间的信息流成为模型设计中的另一个关键决策
上图是用于对象检测的路径聚合网络 (PAN)。自下而上的路径 (b) 被增强以使低层信息更容易传播到顶部。在 FPN 中,局部空间信息在红色箭头中向上传播。虽然图中没有清楚地展示,但红色路径经过了大约 100 多个层。PAN 引入了一条捷径(绿色路径),只需大约 10 层即可到达顶部 N₅ 层。这种短路概念使顶层可以使用细粒度的本地化信息。
8. MISH激活函数
一个新的 state of the art 的激活函数,ReLU 的继任者
对激活函数的研究一直没有停止过,ReLU 还是统治着深度学习的激活函数,不过,这
种情况有可能会被 Mish 改变
ReLU 和 Mish 的对比,Mish 的梯度更平滑,Mish 检查了理想的激活函数应该是什么
(平滑、处理负号等)的所有内容
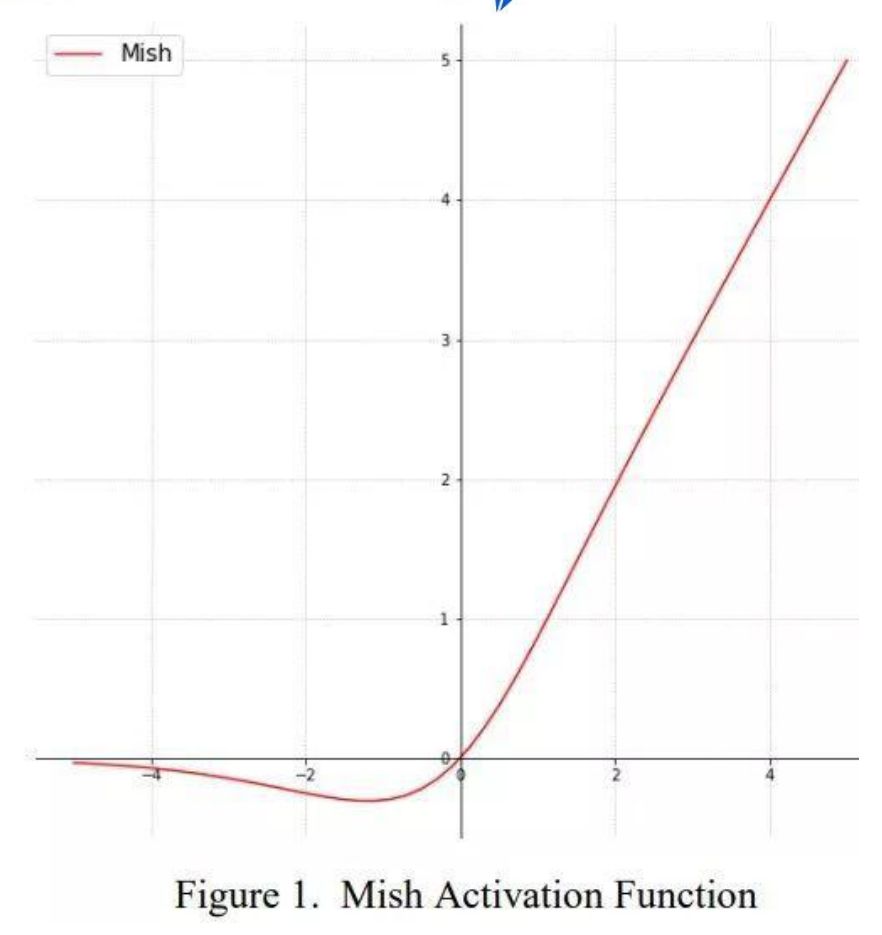
Mish是 x * tanh(ln(1+e^x))。
ReLU 是 max(0,x),
Swish 是 x * sigmoid(x)。
Tensorflow 中的 Mish 函数:
Tensorflow:x = x *tf.math.tanh(F.softplus(x))
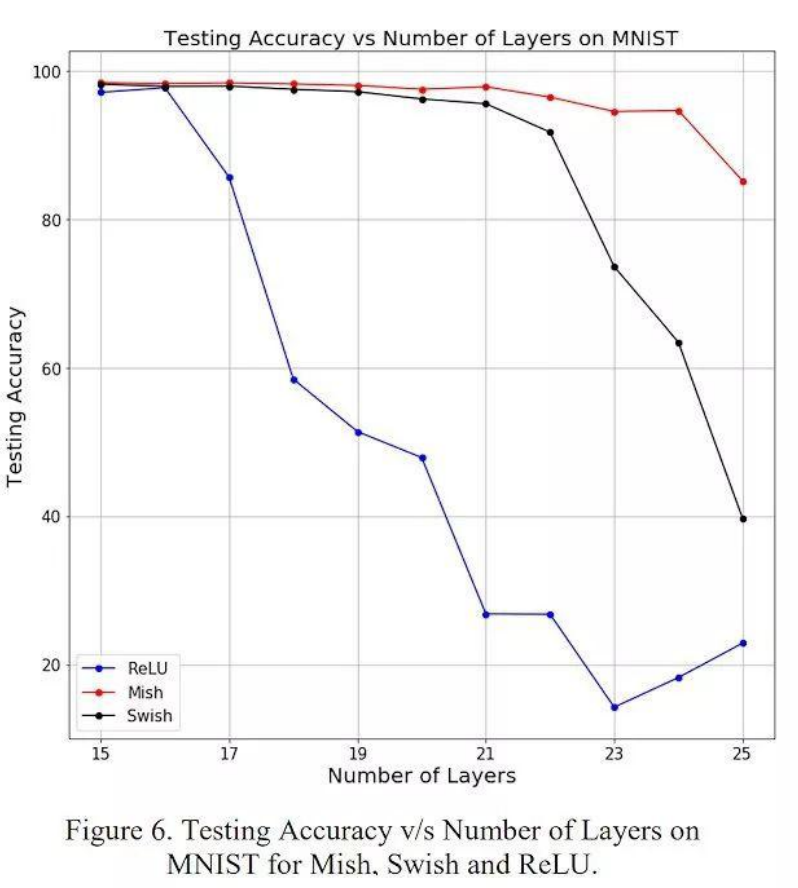
随着层深的增加,
ReLU 精度迅速下降,其次是 Swish。相比之下,Mish 能更好地保持准确性,这可能是因
为它能更好地传播信息:
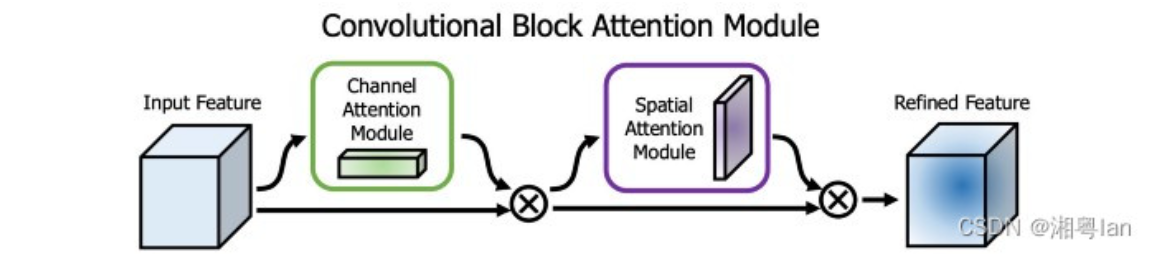
9. SAM
空间注意模块 (SAM) spatial attation module
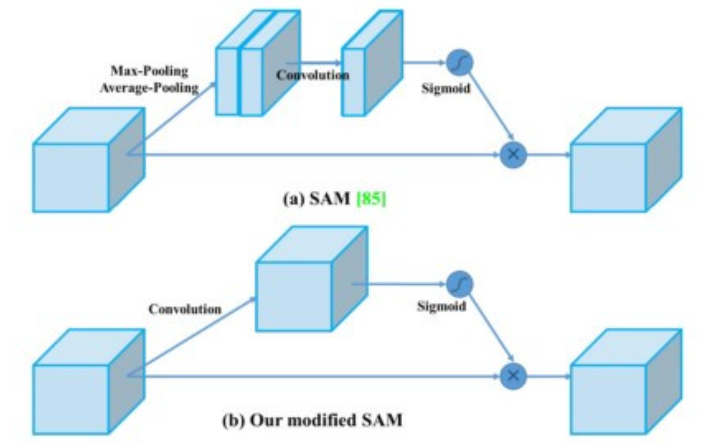
注意力在深度学习设计中被广泛采用。在 SAM 中,Max pooling和average pooling分别应用于输入特征图以创建两组特征图。结果被输入一个卷积层,然后是一个 sigmoid 函数来创建空间注意力
学习背景与物体 背景则 对应位置乘以0抑制掉 物体则对应位置乘以1 保留下来
在 YOLOv4 中,使用修改后的 SAM 而不应用Max pooling和average pooling
10 其他的
simulating object occlusion issues.
"simulating object occlusion issues" 意思是模拟物体遮挡问题。在计算机视觉和图像处理中,物体遮挡是指当一个物体部分或完全遮挡了另一个物体时,会发生的视觉问题。这可能会导致图像中出现遮挡物体的部分被遮挡的物体遮盖,或者遮挡物体的形状和颜色被错误地识别。为了解决这个问题,可以使用计算机模拟来模拟遮挡问题,以便测试和优化计算机视觉算法的性能。
multiply and superimpose
"multiply and superimpose" 是英语中的一个短语,意思是将两个或多个物体或图像相乘并叠加在一起。在数学和科学领域,这个短语通常用于描述两个函数或信号的卷积操作,它们被相乘并在一起叠加以产生一个新的函数或信号。在艺术和设计领域,这个短语通常用于描述将两个或多个图像或图形相乘并叠加在一起以创建一个新的复合图像。
introduced the concept of knowledge distillation to design the label refinement network
这句话的意思是,使用知识蒸馏的概念来设计标签细化网络。知识蒸馏是一种模型压缩技术,通过将一个复杂的模型的知识传递给一个更简单的模型,来提高模型的泛化能力和效率。在这个语境中,标签细化网络是指一个用于改善标签质量的神经网络模型。
post-processing is a method for screening model prediction results
post-processing是指对模型预测结果进行筛选和调整的方法。在机器学习中,模型的预测结果可能存在一些误差或不确定性,因此需要使用post-processing方法来对结果进行修正和优化。这种方法可以通过对预测结果进行过滤、平滑或聚合等处理,来提高模型的准确性和可靠性。因此,post-processing是机器学习中非常重要的一环,可以帮助我们更好地理解和利用模型的预测结果。
dilated convolution operation
扩张卷积运算
Dilated convolution operation(扩张卷积操作)是一种在卷积神经网络中使用的卷积操作。与普通的卷积操作不同,它在卷积核中间插入了一些空洞,使得卷积核的感受野(receptive field)变大,从而可以更好地捕捉输入图像中的长距离依赖关系。 具体来说,dilated convolution operation 可以通过在卷积核中间插入一些空洞(也称为膨胀率或dilation rate),来扩大卷积核的感受野。空洞的大小决定了卷积核的感受野大小,例如一个膨胀率为2的卷积核,其感受野大小相当于一个普通卷积核的3x3大小。使用扩张卷积操作可以在保持模型参数数量不变的情况下,增加卷积层的感受野,从而提高模型的性能。
Squeeze-and-Excitation (SE)和Spatial Attention Module (SAM)都是深度学习中用于增强卷积神经网络性能的注意力机制。
Squeeze-and-Excitation (SE)是一种注意力机制,它通过对每个通道的特征图进行全局池化,然后使用一个小型的全连接神经网络来学习每个通道的重要性权重,最后将这些权重应用于原始特征图以增强网络的表达能力。
Spatial Attention Module (SAM)是另一种注意力机制,它通过使用一个小型的卷积神经网络来生成一个空间注意力图,该图对输入特征图的每个空间位置分配一个权重,以增强网络对输入的关注度。 这两种注意力机制都可以用于增强卷积神经网络的性能,提高模型的准确性和泛化能力。
Swish and Mish are continuously differentiable activation function
连续的 可微分的函数
Yes, that is correct. Both Swish and Mish activation functions are continuously differentiable. Swish activation function is defined as: f(x) = x * sigmoid(x) where sigmoid(x) is the sigmoid function. It is continuously differentiable and has a derivative that is also continuous. Mish activation function is defined as: f(x) = x * tanh(softplus(x)) where tanh(x) is the hyperbolic tangent function and softplus(x) is the softplus function. Both of these functions are continuously differentiable and have continuous derivatives. Therefore, the Mish activation function is also continuously differentiable.
continuous derivatives连续可导
continuously differentiable连续可微

 浙公网安备 33010602011771号
浙公网安备 33010602011771号