深度学习-卷积神经网络-BatchNormalization-MobileNet-47
1. Normalization
feature map shape 记为[N, C, H, W],其中 N 表示 batch size,即 N个样本;C 表示通道数;H、W 分别表示特征图的高度、宽度。这几个方法主要的区别就是在:
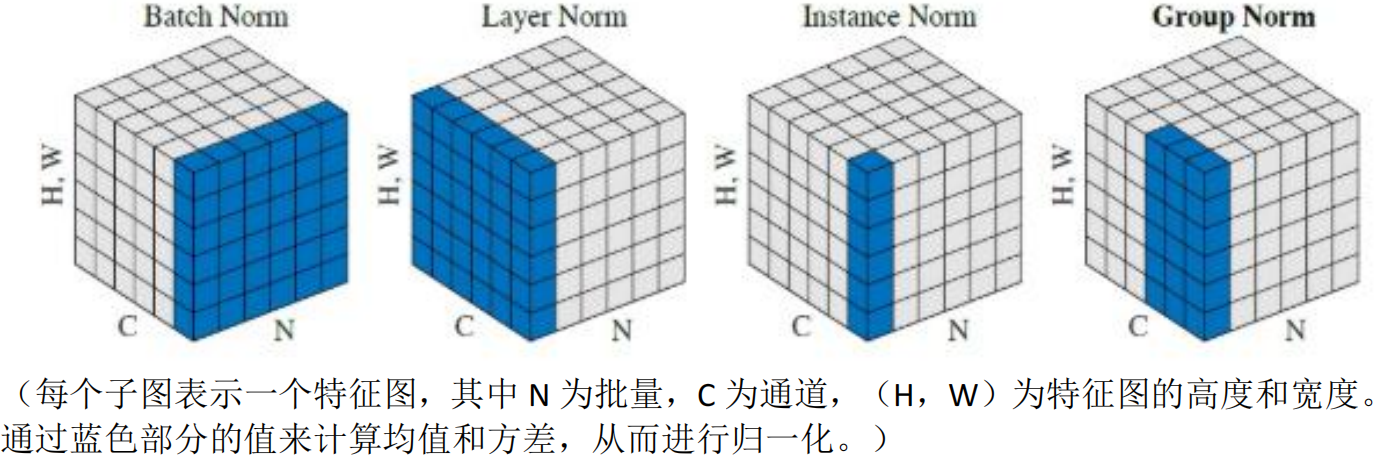
- BN 是在 batch 上,对 N、H、W 做归一化,而保留通道 C 的维度。BN 对较小的
batch size 效果不好。BN 适用于固定深度的前向神经网络,如 CNN,不适用于 RNN; - LN 在通道方向上,对 C、H、W 归一化,主要对 RNN 效果明显;
- IN 在图像像素上,对 H、W 做归一化,用在风格化迁移;
- GN 将 channel 分组,然后再做归一化。
目标:
我们想要的是在非线性 activation 之前,输出值应该有比较好的分布(例如高斯分布),以便于 back propagation 时计算 gradient,更新 weight。
Batch Normalization
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
......
fc = tf.contrib.layers.batch_norm(fc, center=True, scale=True, is_training=True)
fc = tf.nn.relu(fc)
为什么要进行 BN:
在深度神经网络训练的过程中,通常以输入网络的每一个 mini-batch 进行训练,这样每个 batch 具有不同的分布,使模型训练起来特别困难。
:在训练的过程中,激活函数会改变各层数据的分布,随着网络的加深,这种改变(差异)会越来越大,使模型训练起来特别困难,收敛速度很慢,会出现梯度消失的问题。
BN 的使用位置: 全连接层或卷积操作之后,激活函数之前。
BN过程:需要记忆-最好能默写

加入缩放和平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。、
作用:

缺点:

2. MobileNet
轻量级神经网络 MobileNet,顾名思义,运行在手机端的网络。MobileNet V1 由谷歌在 2017 年 4 月提出,创新点就是深度可分离卷积
深度可分离卷积
Depthwise Separable Convolution
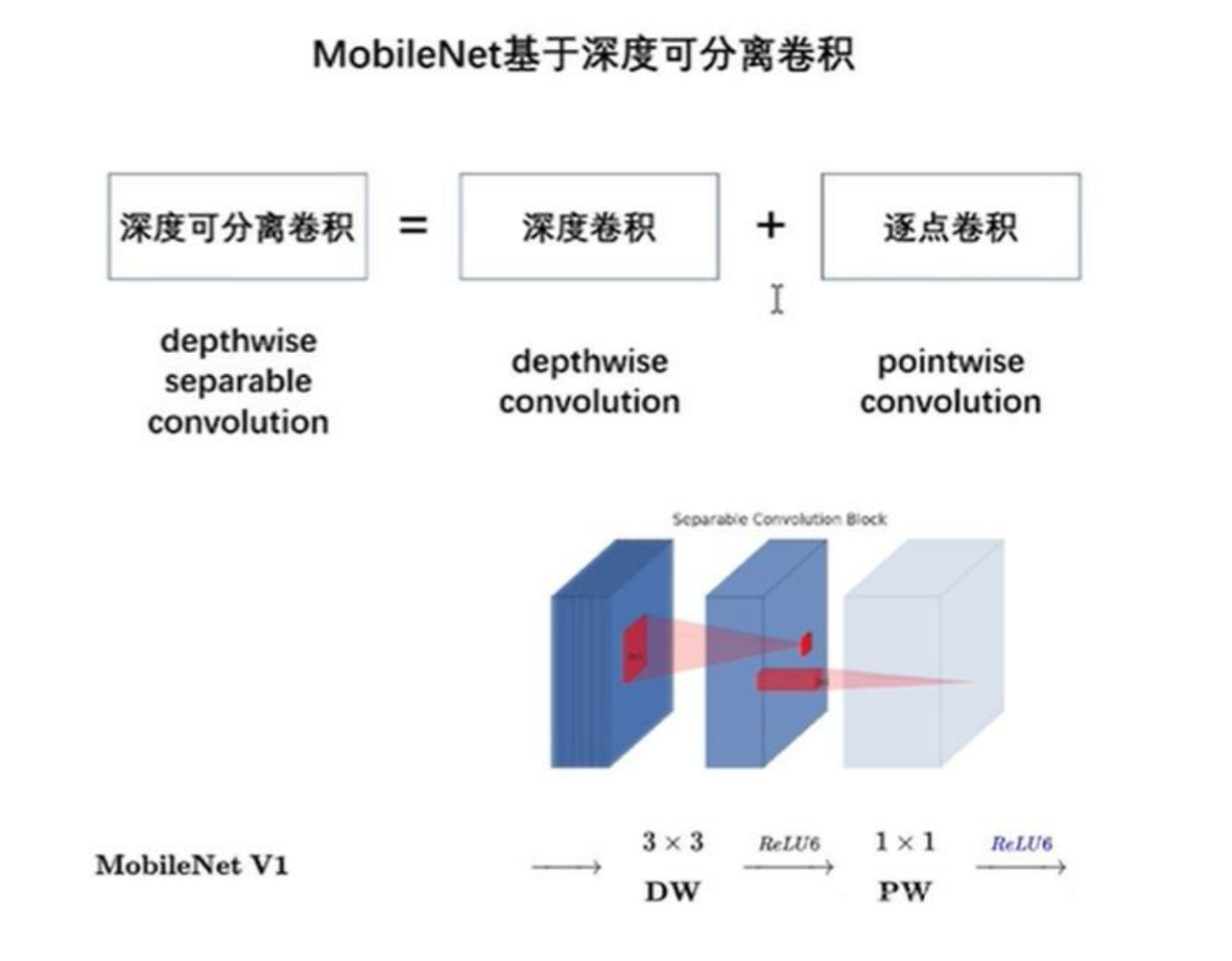
好处:用更少的参数,更少的运算,达到精度差不多的结果
参考:https://zhuanlan.zhihu.com/p/92134485
常规卷积:
对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3
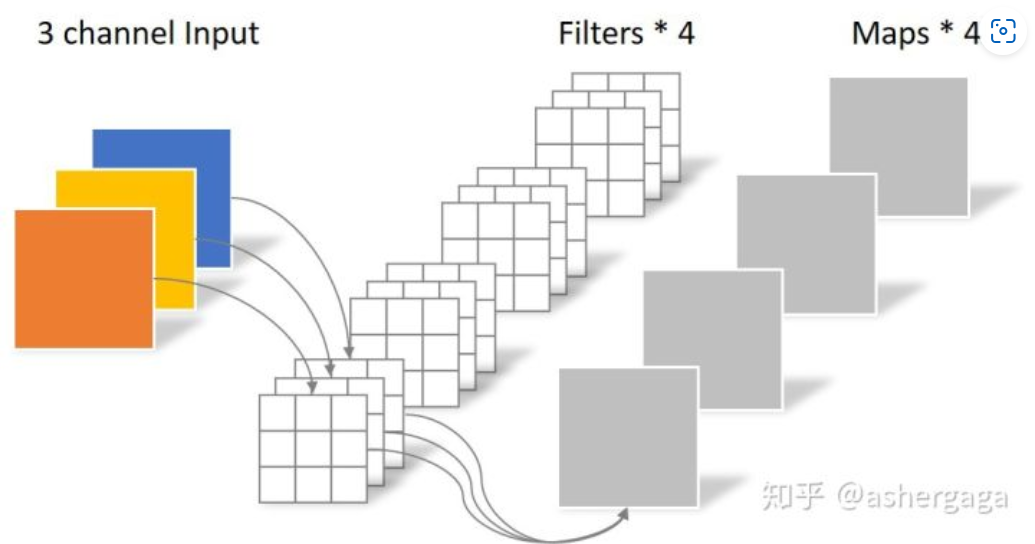
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积:
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积
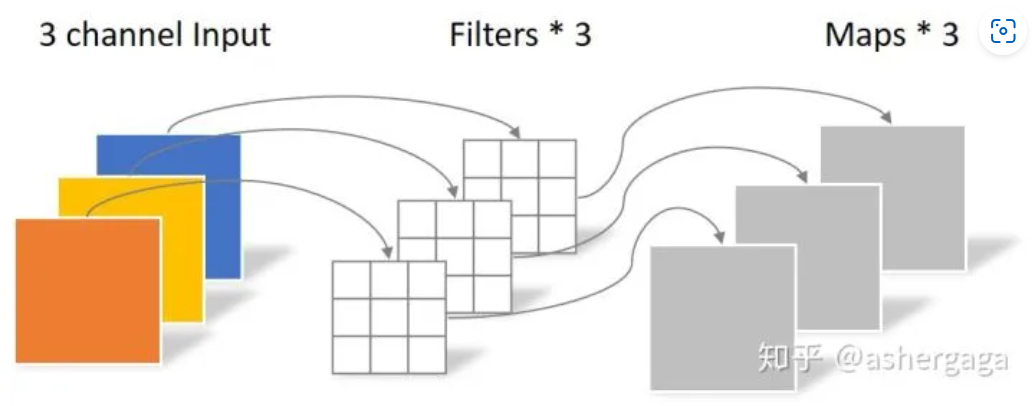
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5)。
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
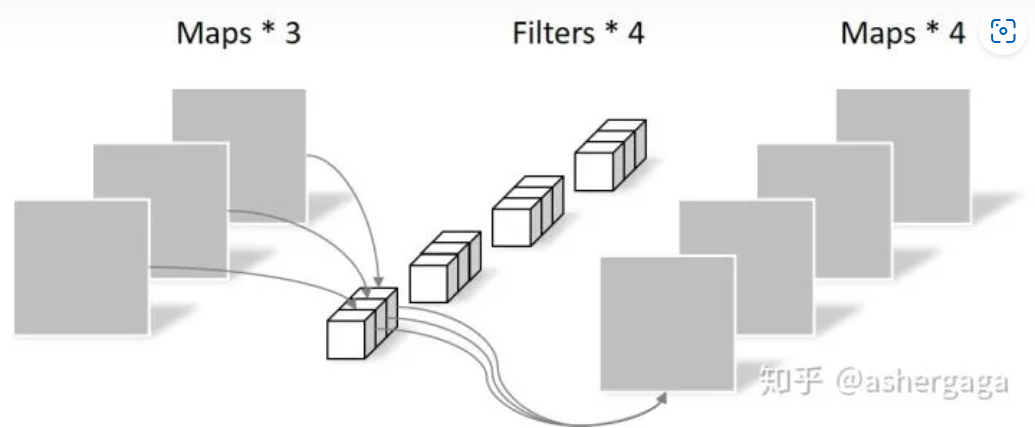
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同
参数对比:
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
Relu6
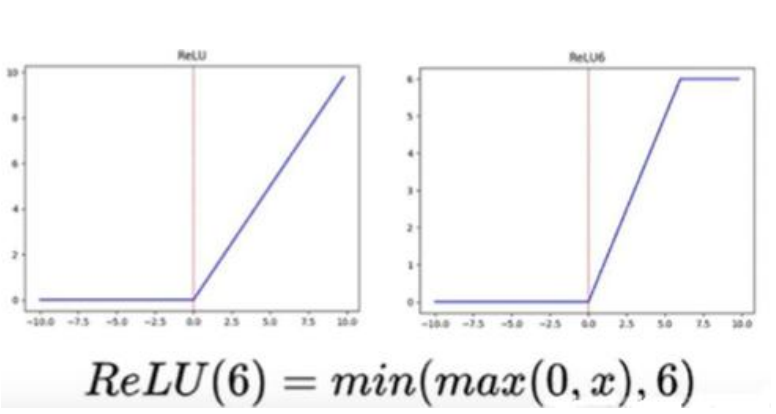

卷积之后通常会接一个 ReLU 非线性激活,在 Mobile v1 里面使用 ReLU6,ReLU6 就是普通的 ReLU 但是限制最大输出值为 6(对输出值做 clip),这是为了在移动端设备 float16的低精度的时候,也能有很的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为 0 到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的 float16 无法很好地精确描述如此大范围的数值,带来精度损失。
什么是 FP16?
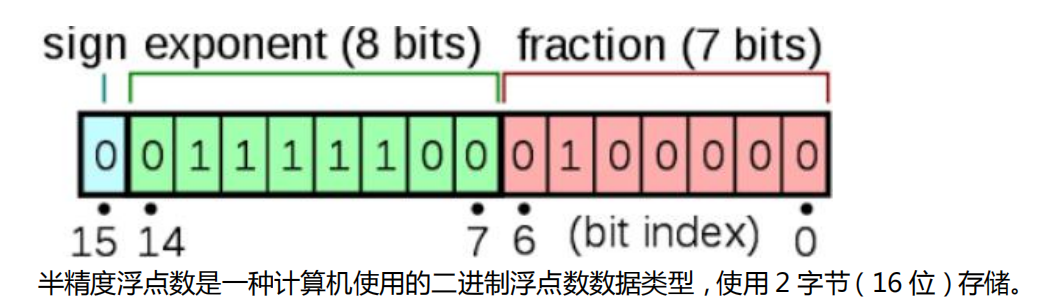
FP16的好处:
减少显(内)存占用
加快训练和推断的计算
张量核心的普及:硬件的发展同样也推动着模型计算的加速,随着 Nvidia 张量核心(Tensor Core)的普及,16bit 计算也一步步走向成熟,低精度计算也是未来深度学习的一个重要趋势
MobileNet V1:
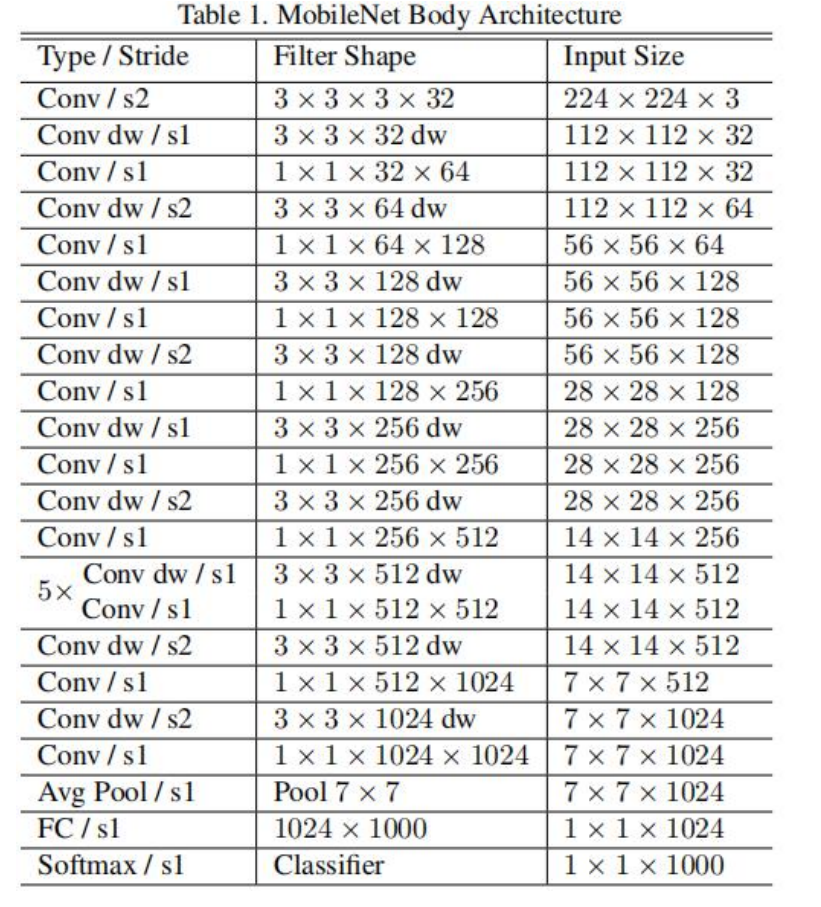
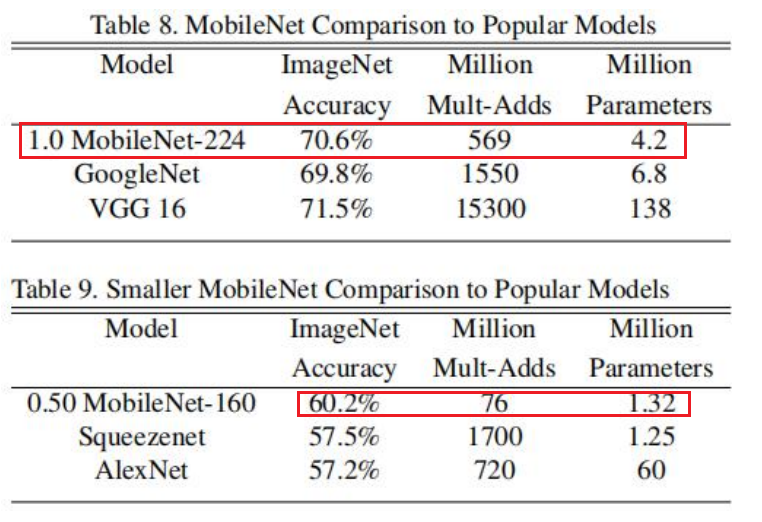
效果:
MobileNet V2
MobileNet V2 是对 MobileNet V1 的改进,同样是一个轻量级卷积网络。
V1 借鉴 VGG
V2 借鉴 ResNet
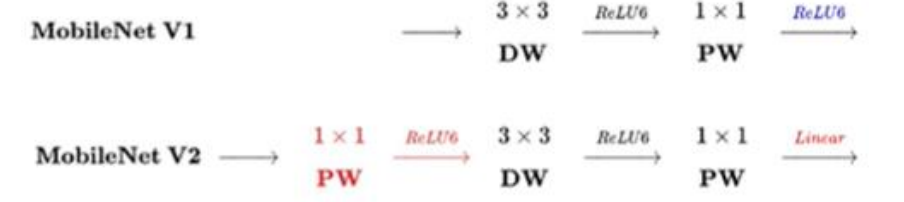

Inverted

ResNet 是先做了压缩,再做扩张,MobileNet V2 是相反的
V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以上一层给的通道数本身就很少话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数 t=6,这样不管输入通道 C 是多还是少,经过第一个 W 维之后,DW都是在相对更高维(t*C)进行工作的。
V2的结构:

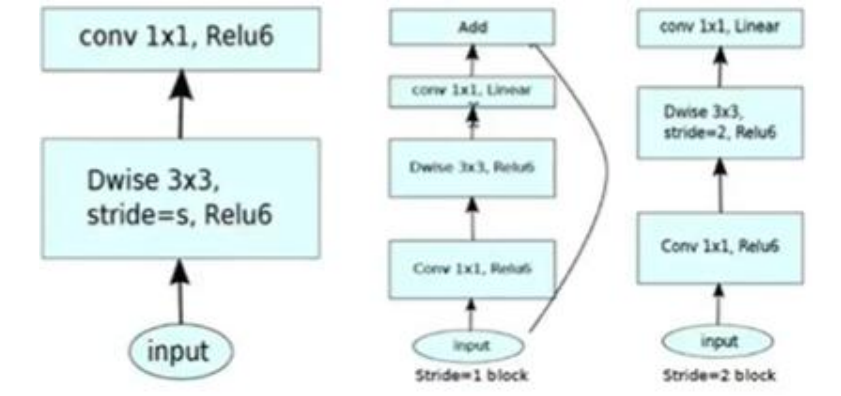
注意的是这个 shortcut 在 stride 等于 1 的会加,stride 等于 2 的时候不会加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号