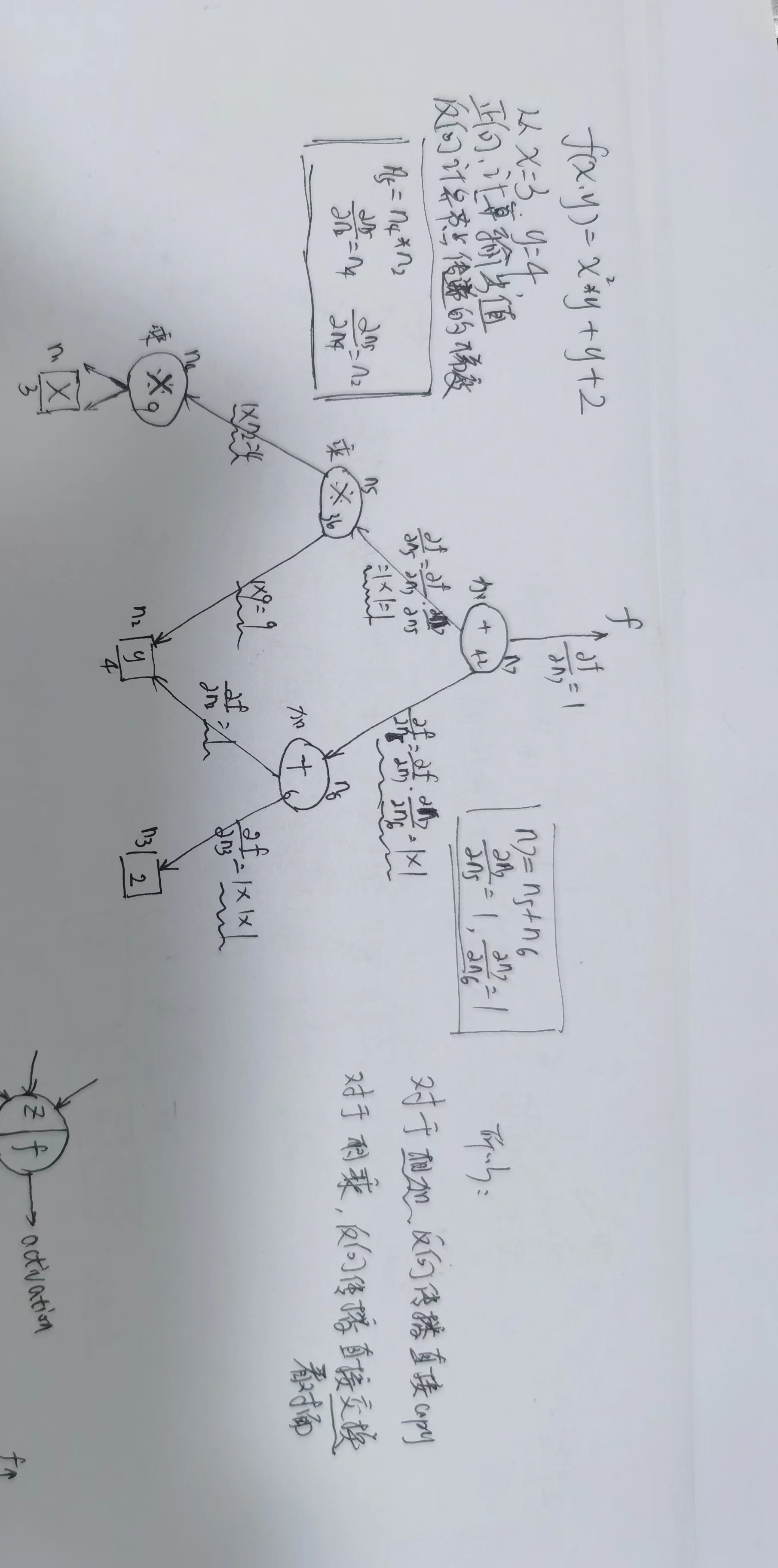
1. 举例
![]()
2. python实现
import numpy as np
from sklearn.datasets import fetch_mldata
from sklearn.utils.extmath import safe_sparse_dot
def train_y(y_true):
y_ohe = np.zeros(10)
y_ohe[int(y_true)] = 1
return y_ohe
mnist = fetch_mldata('MNIST original', data_home='./for_my_own_nn_data/')
X, y = mnist['data'], mnist['target']
print('X shape:', X.shape)
print('y shape:', y.shape)
y = np.array([train_y(y[i]) for i in range(len(y))])
hidden_layer_size = [300, 100]
#max_iter = 20
max_iter = 20
alpha = 0.0001 # l2正则项系数
learning_rate = 0.001
def log_loss(y_true, y_prob):
# 交叉熵损失
y_prob = np.clip(y_prob, 1e-10, 1 - 1e-10)
if y_prob.shape[1] == 1:
y_prob = np.append(1 - y_prob, y_prob, axis=1)
if y_true.shape[1] == 1:
y_true = np.append(1 - y_true, y_true, axis=1)
return -np.sum(y_true * np.log(y_prob)) / y_prob.shape[0]
def soft_max(x):
tmp = x - x.max(axis=1)[:, np.newaxis]
np.exp(tmp, out=x)
x /= x.sum(axis=1)[:, np.newaxis]
return x
def relu(x):
np.clip(x, 0, np.finfo(x.dtype).max, out=x) # max(0, x)
return x
def relu_derivation(z, delta):
# relu的导数要不为0 要不为1 为1则保持不变
delta[z == 0] = 0
def gen_batch(n, bs):
start = 0
for _ in range(n // bs):
end = start + bs
yield slice(start, end)
start = end
# 遍历完成之后还有剩余的 剩下的全部切出
if start < n:
yield slice(start, n)
n_samples, n_features = X.shape
n_outputs = y.shape[1]
batch_size = min(200, n_samples)
layer_units = ([n_features] + hidden_layer_size + [n_outputs])
print("====>layer_units:", layer_units)
n_layers = len(layer_units)
print("====>n_layers: ", n_layers)
# w b 的初始化
coefs_ = []
intercepts_ = []
for i in range(n_layers - 1):
fan_in = layer_units[i]
fan_out = layer_units[i + 1]
factor = 6.
ini_bound = np.sqrt(factor / (fan_in + fan_out))
coef_init = np.random.uniform(-ini_bound, ini_bound, (fan_in, fan_out))
coefs_.append(coef_init)
intercept_init = np.random.uniform(-ini_bound, ini_bound, fan_out)
intercepts_.append(intercept_init)
# 正项传播值的初始化
activations = [X]
activations.extend(np.empty((batch_size, n_fan_out)) for n_fan_out in layer_units[1:])
# w的更新量 deltas alpha * delta
deltas = [np.empty_like(a_layer) for a_layer in activations]
coef_grads = [np.empty((n_fan_in, n_fan_out)) for
n_fan_in, n_fan_out in zip(layer_units[:-1], layer_units[1:])]
intercept_grads = [np.empty(n_fan_out) for n_fan_out in layer_units[1:]]
loss_ = 0.
for it in range(max_iter):
arr = np.arange(n_samples)
np.random.shuffle(arr)
X = X[arr]
y = y[arr]
accumulated_loss = 0.0
for batch_slice in gen_batch(n_samples, batch_size):
batch_x = X[batch_slice]
batch_y = y[batch_slice]
# 输入层赋值
activations[0] = batch_x
# 正向传播
for i in range(n_layers - 1):
activations[i + 1] = safe_sparse_dot(activations[i], coefs_[i])
# 只要不是最后一层 都需要进过激活函数
if (i + 1) != (n_layers - 1):
activations[i + 1] = relu(activations[i + 1])
# 对于最后一层 需要经过softmax
activations[i + 1] = soft_max(activations[i + 1])
# 计算loss
loss = log_loss(batch_y, activations[-1]) # 最后一层的输出 与 y_true 计算交叉熵
# loss添加正则项
values = np.sum(np.array([np.dot(s.ravel(), s.ravel()) for s in coefs_]))
loss += (0.5 * alpha) * values / len(batch_y)
accumulated_loss += loss * len(batch_y)
# 反向传播
last = n_layers - 2
deltas[last] = activations[-1] - batch_y # y_predict - y_true
# 计算倒数第一个W的梯度 即从输出层返回过来的梯度
# 1. base loss 梯度 (y_hat - y) * x
coef_grads[last] = safe_sparse_dot(activations[last].T, deltas[last])
# 2. L2 loss 对应的梯度
coef_grads[last] += (alpha * coefs_[last])
# 求平均
coef_grads[last] /= n_samples
# 截距项对应的梯度
intercept_grads[last] = np.mean(deltas[last], 0)
# 最后一层算好之后 反向 往前推
for i in range(n_layers - 2, 0, -1):
# deltas_previous = deltas * W * 激活函数的导
deltas[i - 1] = safe_sparse_dot(deltas[i], coefs_[i].T)
# 用上激活函数的导数
relu_derivation(activations[i], deltas[i - 1])
# 计算每个隐藏层前面的W矩阵的梯度
# 1,base loss对应的梯度
coef_grads[i - 1] = safe_sparse_dot(activations[i - 1].T, deltas[i - 1])
# 2,L2 loss对应的梯度
coef_grads[i - 1] += (alpha * coefs_[i - 1])
# 3,梯度求平均
coef_grads[i - 1] /= n_samples
# 4,截距项,base loss对应的梯度
intercept_grads[i - 1] = np.mean(deltas[i - 1], 0)
# 反向传播结束 跟新参数
grads = coef_grads + intercept_grads # 只是列表的拼接
updates = [-learning_rate * grad for grad in grads]
params = coefs_ + intercepts_
for param, update in zip(params, updates):
param += update
loss_ = accumulated_loss / X.shape[0]
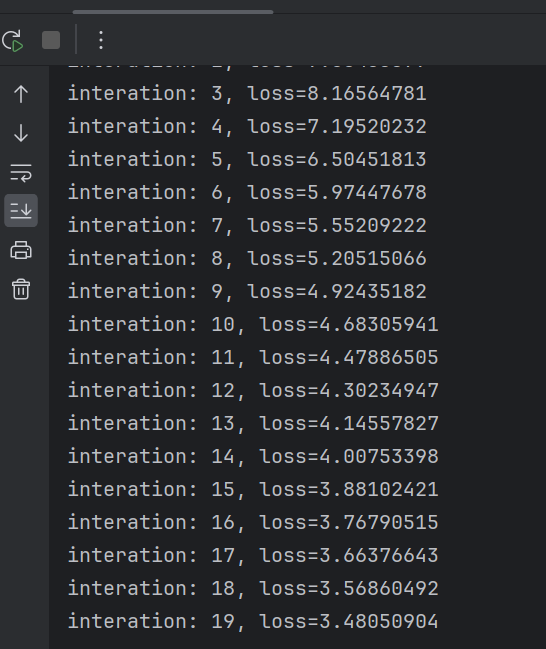
print("interation: %d, loss=%.8f" % (it, loss_))
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号